







排序算法
内部与外部排序
- 内部排序 -> 所有记录都加载到内存中
- 外部排序 -> 把数据分块排序(数据量比较大)
一般对大数据量排序时,可以把数据加载进b树
几种排序方法
- 冒泡排序
/*
相邻数字之间两两比较,第一轮把最大的数选出来放到最右边,第二轮把剩下的最大的数选出来放到最右边(除开第一轮的那个数)……最后把最左边的两个数比较完,较大的数放右边。
如果中途已经全部排好序,则停止排序。
*/
#include <iostream>
#include <cstdlib>
using namespace std;
int N = 17;
void PRINT(float data[])
{
float t, *p;
p = data;
for (int i=0; i<N; i++) cout << p[i] << " ";
cout << "\n";
}
void SORT(float data[])
{
float t, *p;
int n;
bool stopFlag;
p = data;
// Bubble
stopFlag = false;
n = N;
while (n > 0){
stopFlag = true;
for (int i=0; i+1<n; i++){
if (p[i]>p[i+1]) {t=p[i];p[i]=p[i+1];p[i+1]=t;stopFlag=false;} //swap
}
if (true == stopFlag) break;
n--;
PRINT(p);
}
}
int main()
{
float data[N];
FILE *fp;
fp = fopen("data","r");
for(int i=0; i<N; i++){
fscanf(fp, "%f", data+i);
}
PRINT(data);
SORT(data);
fclose(fp);
return 0;
}OUTPUT:
0.38 0.16 0.53 0.24 0.18 0.38 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.16 0.38 0.24 0.18 0.38 0.51 0.21 0.08 0.34 0.51 0.53 0.71 0.95 0.62 0.88 0.56 0.98
0.16 0.24 0.18 0.38 0.38 0.21 0.08 0.34 0.51 0.51 0.53 0.71 0.62 0.88 0.56 0.95 0.98
0.16 0.18 0.24 0.38 0.21 0.08 0.34 0.38 0.51 0.51 0.53 0.62 0.71 0.56 0.88 0.95 0.98
0.16 0.18 0.24 0.21 0.08 0.34 0.38 0.38 0.51 0.51 0.53 0.62 0.56 0.71 0.88 0.95 0.98
0.16 0.18 0.21 0.08 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.62 0.71 0.88 0.95 0.98
0.16 0.18 0.08 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.62 0.71 0.88 0.95 0.98
0.16 0.08 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.62 0.71 0.88 0.95 0.98
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.62 0.71 0.88 0.95 0.98 
- 插入排序
/*
原理:从左往右依次对每个元素进行以下操作
1.如果元素大于等于左边元素,则不操作,转到下一个。
2.如果元素小于左边元素,将其从左开始依次与其左边的元素进行比较,如果找到一个位置,元素恰好大于左边元素,小于右边元素(这里的“等于”情况单独考虑进去),则将元素插入这里。
3.继续从已经操作完的元素位置往后操作。
插入排序由于在将数据插入两个数据之间时要移动后续全部的数据,采用链表来操作会提高效率。
*/
#include <iostream>
#include <cstdlib>
using namespace std;
int N = 17;
struct DATA{
float data;
DATA *link;
};
DATA *array = NULL;
void PRINT(DATA *ptr)
{
float t;
DATA *p;
p = ptr;
while(1){
cout << (p->data) << " ";
if (NULL == (p->link)) break;
else p = p->link;
}
cout << "\n";
}
void SORT(DATA *ptr)
{
float t;
int n;
DATA *p, *temp, *head, *cache;
head = p = temp = ptr;
// Insertion
while (NULL != (p->link)){
if ((p->data) > ((p->link)->data)){
t = (p->link)->data;
temp = head;
//if ((t > (head->data)) && (t <= ((head->link)->data))){
if (t <= (head->data)){
cache = p->link;
p->link = (p->link)->link;
free(cache);
cache = (DATA *)malloc(sizeof(DATA));
cache -> data = t;
cache -> link = head;
head = cache;
}
else{
while (t > ((temp->link)->data)) {temp = temp->link;}
cache = p->link;
p->link = (p->link)->link;
free(cache);
cache = (DATA *)malloc(sizeof(DATA));
cache -> data = t;
cache -> link = temp -> link;
temp -> link = cache;
}
}
else
p = p->link;
PRINT(head);
}
}
int main()
{
float data = 0.0;
DATA *ptr, *head;
FILE *fp;
fp = fopen("data","r");
for(int i=0; i<N; i++){
fscanf(fp, "%f", &data);
ptr = (DATA *)malloc(sizeof(DATA));
ptr -> data = data;
ptr -> link = NULL;
if (NULL == array){
head = ptr;
array = ptr;
}
else{
array -> link = ptr;
array = ptr;
}
}
PRINT(head);
SORT(head);
fclose(fp);
return 0;
}
OUTPUT:
0.38 0.16 0.53 0.24 0.18 0.38 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.16 0.38 0.53 0.24 0.18 0.38 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.16 0.38 0.53 0.24 0.18 0.38 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.16 0.24 0.38 0.53 0.18 0.38 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.16 0.18 0.24 0.38 0.53 0.38 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.16 0.18 0.24 0.38 0.38 0.53 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.16 0.18 0.24 0.38 0.38 0.51 0.53 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.16 0.18 0.21 0.24 0.38 0.38 0.51 0.53 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.18 0.21 0.24 0.38 0.38 0.51 0.53 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.53 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.71 0.95 0.98 0.62 0.88 0.56
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.71 0.95 0.98 0.62 0.88 0.56
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.62 0.71 0.95 0.98 0.88 0.56
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.62 0.71 0.88 0.95 0.98 0.56
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.62 0.71 0.88 0.95 0.98 
用数组也可以顺利地进行插入排序,而且可以方便地从后往前比较,直到找到“谷地”:
#include <iostream>
#include <cstdlib>
using namespace std;
int N = 17;
void PRINT(float *data)
{
float *p;
p = data;
for (int i=0; i<N; i++){
cout << p[i] << " ";
}
cout << "\n";
}
void SORT(float *data)
{
float t, *p;
int n;
p = data;
// Insertion
for (int i=1; i<N; i++){
if (p[i] < p[i-1]){
for (int j=i; j>0; j--){
if (p[j-1] > p[j]){
t = p[j];
p[j] = p[j-1];
p[j-1] = t;
}
else
break;
}
}
PRINT(p);
}
}
int main()
{
float data[N];
FILE *fp;
fp = fopen("data","r");
for(int i=0; i<N; i++){
fscanf(fp, "%f", data+i);
}
PRINT(data);
SORT(data);
fclose(fp);
return 0;
}
由于希尔排序要把局部的数据排成正序,所以用数组来进行从后往前的插入排序更为有效。
- 希尔排序
/*
将一组数据按间隔h提取出来进行排序称为"h排序",构建一个收敛到1的h序列,依次进行h排序,最终可以得到一个有序数列。希尔排序就是依据于此。那么,提高排序效率的关键就成为:找到一个较好的h序列。一般地用以下法则就可以:
1. h1=1
2. h_{s+1} = 3*h_{s} + 1,最大的h<=N/9(N是整个数组长度)
分好块之后,调用普通的插入排序就可以了,注意把插入排序的元素间隔调整为h(只要把原来的"1"改为"h"就可以了,没有想像的那么复杂~)
*/
#include <iostream>
#include <cstdlib>
using namespace std;
int N = 17;
void PRINT(float *data)
{
float *p;
p = data;
for (int i=0; i<N; i++){
cout << p[i] << " ";
}
cout << "\n";
}
void SORT(float *data)
{
float t, *p;
int n, h;
p = data;
for (h=1; h<=N/9; h=3*h+1);
for (; h>0; h/=3){
for (int start=0; start<h; start++){
// Insertion
for (int i=start+h; i<N; i+=h){
if (p[i] < p[i-h]){
for (int j=i; j>0; j-=h){
if (p[j-h] > p[j]){
t = p[j];
p[j] = p[j-h];
p[j-h] = t;
}
else
break;
}
}
PRINT(p);
}
}
}
}
int main()
{
float data[N];
FILE *fp;
fp = fopen("data","r");
for(int i=0; i<N; i++){
fscanf(fp, "%f", data+i);
}
PRINT(data);
SORT(data);
fclose(fp);
return 0;
}
OUTPUT:
0.38 0.16 0.53 0.24 0.18 0.38 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.18 0.16 0.53 0.24 0.38 0.38 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.53 0.24 0.18 0.38 0.51 0.21 0.38 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.53 0.24 0.18 0.38 0.51 0.21 0.38 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.53 0.24 0.18 0.38 0.51 0.21 0.38 0.34 0.51 0.95 0.56 0.98 0.62 0.88 0.71
0.08 0.16 0.53 0.24 0.18 0.38 0.51 0.21 0.38 0.34 0.51 0.95 0.56 0.98 0.62 0.88 0.71
0.08 0.16 0.53 0.24 0.18 0.34 0.51 0.21 0.38 0.38 0.51 0.95 0.56 0.98 0.62 0.88 0.71
0.08 0.16 0.53 0.24 0.18 0.34 0.51 0.21 0.38 0.38 0.51 0.95 0.56 0.98 0.62 0.88 0.71
0.08 0.16 0.51 0.24 0.18 0.34 0.53 0.21 0.38 0.38 0.51 0.95 0.56 0.98 0.62 0.88 0.71
0.08 0.16 0.51 0.24 0.18 0.34 0.51 0.21 0.38 0.38 0.53 0.95 0.56 0.98 0.62 0.88 0.71
0.08 0.16 0.51 0.24 0.18 0.34 0.51 0.21 0.38 0.38 0.53 0.95 0.56 0.98 0.62 0.88 0.71
0.08 0.16 0.51 0.21 0.18 0.34 0.51 0.24 0.38 0.38 0.53 0.95 0.56 0.98 0.62 0.88 0.71
0.08 0.16 0.51 0.21 0.18 0.34 0.51 0.24 0.38 0.38 0.53 0.95 0.56 0.98 0.62 0.88 0.71
0.08 0.16 0.51 0.21 0.18 0.34 0.51 0.24 0.38 0.38 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.51 0.21 0.18 0.34 0.51 0.24 0.38 0.38 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.51 0.21 0.18 0.34 0.51 0.24 0.38 0.38 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.21 0.51 0.18 0.34 0.51 0.24 0.38 0.38 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.51 0.34 0.51 0.24 0.38 0.38 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.34 0.51 0.51 0.24 0.38 0.38 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.34 0.51 0.51 0.24 0.38 0.38 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.51 0.51 0.38 0.38 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.51 0.51 0.38 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.88 0.56 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.88 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.88 0.98 0.62 0.95 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.62 0.88 0.98 0.95 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.62 0.88 0.95 0.98 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.62 0.71 0.88 0.95 0.98 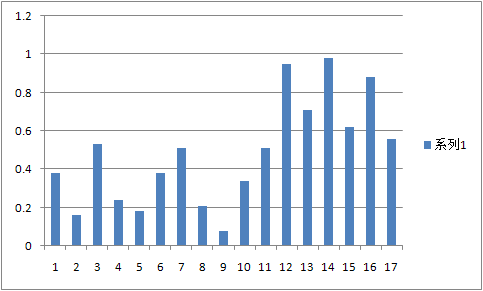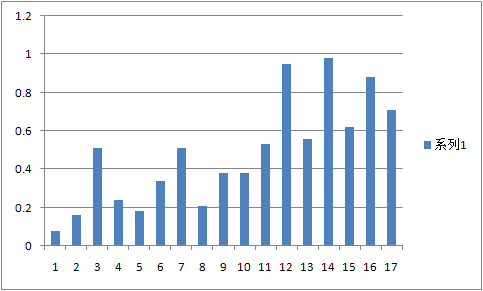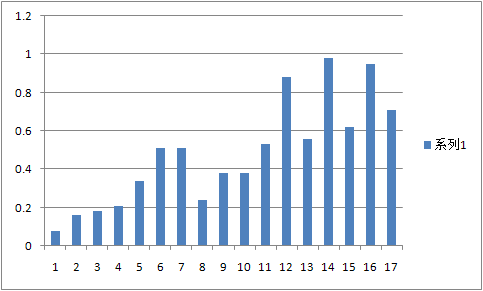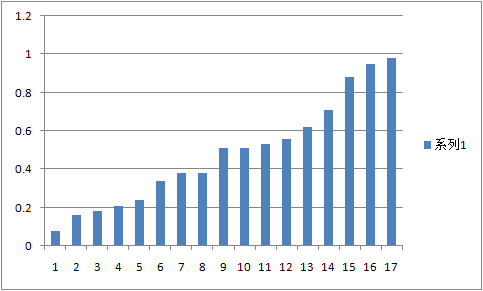
- 快速排序
#!/usr/bin/env python
'''
本快排的原理:
把数列的第一个作为pivot,然后从两头往中间比较,如果data[i]>pivot>data[j],就把data[i]与data[j]交换。最后i、j相遇时,把pivot和i处的值比较交换。
这样一次处理之后,数列分成了 [A] - pivot - [B] 三部分,A中的元素都小于pivot,B中的元素都大于pivot,然后递归对A和B进行同样的操作。
用python来写程序可以简化代码
'''
def qsort(DATA):
data = DATA[:]
n = len(data)
if n == 0:
return []
elif n == 1:
print data
return data
elif n == 2:
if data[0] > data[1]:
print [data[1], data[0]]
return [data[1], data[0]]
else:
print data
return data
pivot = data[0]
i = 1
j = n - 1
while (i < j): #完成该循环之后,i == j,而且data[i] > pivot,data[i-1] <= pivot
while (data[i] <= pivot) and (i < j): i += 1
while (data[j] > pivot) and (i < j): j -= 1
t = data[i]
data[i] = data[j]
data[j] = t
if data[i] < pivot:
pivot_i = i
else:
pivot_i = i - 1
t = data[pivot_i]
data[pivot_i] = data[0]
data[0] = t
print data[:pivot_i],[pivot],data[pivot_i+1:]
return qsort(data[:pivot_i]) + [pivot] + qsort(data[pivot_i+1:])
data = []
count = 0
for item in open('data','r').readlines():
if count == 17:
break
item = item.replace('\n','')
item = eval(item)
data.append(item)
count += 1
print data
data = qsort(data)
print dataOUTPUT:
0.38 0.16 0.53 0.24 0.18 0.38 0.51 0.21 0.08 0.34 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.21 0.16 0.34 0.24 0.18 0.38 0.08 0.38 0.51 0.53 0.51 0.95 0.71 0.98 0.62 0.88 0.56
0.18 0.16 0.08 0.21 0.24 0.38 0.34 0.51 0.51 0.53 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.18 0.24 0.38 0.34 0.51 0.53 0.95 0.71 0.98 0.62 0.88 0.56
0.08 0.16 0.34 0.38 0.88 0.71 0.56 0.62 0.95 0.98
0.62 0.71 0.56 0.88 0.98
0.56 0.62 0.71
0.56 0.71
0.08 0.16 0.18 0.21 0.24 0.34 0.38 0.38 0.51 0.51 0.53 0.56 0.62 0.71 0.88 0.95 0.98
希尔排序与快速排序在性能上的比较
希尔排序的复杂度设为O(n^1.25),快排的复杂度设为O(k*n*ln(n))
下表是不同的k值对应的两种排序在速度上相当的n值。比如:k=2.0时,n=463584,表示n<463584时,希尔排序会比较快,n>463584时,快排比较快。
由于快排k的典型值为2,从结果来看,当数据量小于50万时,用希尔排序比较好。即小数据量用希尔排序,大数据量用快排。
| K | T(Shell) ~ T(Quick) |
|---|---|
| 1.0 | 5504 |
| 1.1 | 10963 |
| 1.2 | 19912 |
| 1.3 | 33762 |
| 1.4 | 54257 |
| 1.5 | 83500 |
| 1.6 | 123983 |
| 1.7 | 178623 |
| 1.8 | 250787 |
| 1.9 | 344322 |
| 2.0 | 463584 |
| 2.1 | 613468 |
- 堆排序
# -*- coding: utf-8 -*-
#!/usr/bin/env python
'''
堆排序是将数据构成一棵二叉树,再通过像比赛一样的方法从下而上地选出各级冠军(较大的数),接着,将最上面的父节点提出(它是最大的),换上数据的最后一个。然后就继续从最上面的父节点出发,利用类似贪心算法的方法将剩下的最大数选出来。循环这个贪心的过程,就可以从大到小把全部的数据都选出来。
'''
import math
def preHeap(DATA):
data = DATA[:]
N = len(DATA)
n = math.log(N) / math.log(2)
n = (int)(n // 1)
for k in range(n-1,-1,-1):
for parent in range(2**k-1, 2**(k+1)-1):
data = heap(data, parent)
return data
def heap(DATA, INDEX):
data = DATA[:]
N = len(data)
n = INDEX
parent = n
child = 2*n + 1
while child < N:
if child + 1 < N:
if data[child] < data[child+1]:
child += 1
if data[parent] >= data[child]:
break
else:
t = data[parent]
data[parent] = data[child]
data[child] = t
parent = child
child = 2*parent + 1
return data
if __name__ == '__main__':
Data = []
sortedData = []
count = 0
for item in open('data', 'r'):
item = item.replace('\n','')
Data.append(eval(item))
count += 1
if count == 17: break
print Data
# 自下而上地“比赛”,把胜者往父节点推选出来
Data = preHeap(Data)
n = len(Data)
while 1:
if n == 1:
break
DataCache = heap(Data[:n], 0)
t = DataCache[n-1]
DataCache[n-1] = DataCache[0]
DataCache[0] = t
Data = DataCache[:n] + Data[n:]
print Data
n -= 1
OUTPUT:
[190, 697, 531, 897, 60, 47, 599, 172, 149, 243, 73, 552, 100, 588, 476, 653, 683]
[172, 697, 599, 683, 243, 552, 588, 653, 149, 60, 73, 47, 100, 531, 476, 190, 897]
[172, 683, 599, 653, 243, 552, 588, 190, 149, 60, 73, 47, 100, 531, 476, 697, 897]
[476, 653, 599, 190, 243, 552, 588, 172, 149, 60, 73, 47, 100, 531, 683, 697, 897]
[531, 476, 599, 190, 243, 552, 588, 172, 149, 60, 73, 47, 100, 653, 683, 697, 897]
[100, 476, 588, 190, 243, 552, 531, 172, 149, 60, 73, 47, 599, 653, 683, 697, 897]
[47, 476, 552, 190, 243, 100, 531, 172, 149, 60, 73, 588, 599, 653, 683, 697, 897]
[73, 476, 531, 190, 243, 100, 47, 172, 149, 60, 552, 588, 599, 653, 683, 697, 897]
[60, 476, 100, 190, 243, 73, 47, 172, 149, 531, 552, 588, 599, 653, 683, 697, 897]
[149, 243, 100, 190, 60, 73, 47, 172, 476, 531, 552, 588, 599, 653, 683, 697, 897]
[149, 190, 100, 172, 60, 73, 47, 243, 476, 531, 552, 588, 599, 653, 683, 697, 897]
[47, 172, 100, 149, 60, 73, 190, 243, 476, 531, 552, 588, 599, 653, 683, 697, 897]
[73, 149, 100, 47, 60, 172, 190, 243, 476, 531, 552, 588, 599, 653, 683, 697, 897]
[60, 73, 100, 47, 149, 172, 190, 243, 476, 531, 552, 588, 599, 653, 683, 697, 897]
[47, 73, 60, 100, 149, 172, 190, 243, 476, 531, 552, 588, 599, 653, 683, 697, 897]
[60, 47, 73, 100, 149, 172, 190, 243, 476, 531, 552, 588, 599, 653, 683, 697, 897]
[47, 60, 73, 100, 149, 172, 190, 243, 476, 531, 552, 588, 599, 653, 683, 697, 897]原理图:

Andrew Binstock, John Rex. 程序员实用算法. 2009.















 1959
1959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









