







从一个Native调用java方法的实例开始:
(gdb) bt #0 art_quick_invoke_stub () at art/runtime/arch/arm64/quick_entrypoints_arm64.S:667 #1 0x0000007f8265ae54 in art::ArtMethod::Invoke (this=0x7148dd88, self=0x7f75260c00, args=0x7f7a5fedb0, args_size=28, result=0x7f7a5fed90, shorty=0x73654521 "ZIJJI") at art/runtime/art_method.cc:289 #2 0x0000007f829f2b5c in art::InvokeWithArgArray (soa=..., method=<optimized out>, arg_array=<optimized out>, result=<optimized out>, shorty=<optimized out>) at art/runtime/reflection.cc:439 #3 0x0000007f829f4574 in art::InvokeVirtualOrInterfaceWithVarArgs (soa=..., obj=<optimized out>, mid=<optimized out>, args=...) at art/runtime/reflection.cc:557 #4 0x0000007f828e357c in art::JNI::CallBooleanMethodV (env=<optimized out>, obj=<optimized out>, mid=<optimized out>, args=...) at art/runtime/jni_internal.cc:717 #5 0x0000007f8665d97c in _JNIEnv::CallBooleanMethod (this=this@entry=0x7f75302900, obj=<optimized out>, methodID=<optimized out>) at libnativehelper/include/nativehelper/jni.h:620 #6 0x0000007f866b4454 in JavaBBinder::onTransact (this=0x7f752b0780, code=50, data=..., reply=0x7f7a5ff100, flags=17) at frameworks/base/core/jni/android_util_Binder.cpp:265 #7 0x0000007f85d77174 in android::BBinder::transact (this=0x7f752b0780, code=50, data=..., reply=0x7f7a5ff100, flags=17) at frameworks/native/libs/binder/Binder.cpp:126 #8 0x0000007f85d831a8 in android::IPCThreadState::executeCommand (this=0x7f82d06780, cmd=<optimized out>) at frameworks/native/libs/binder/IPCThreadState.cpp:1115 #9 0x0000007f85d82d04 in android::IPCThreadState::getAndExecuteCommand (this=0x7f82d06780) at frameworks/native/libs/binder/IPCThreadState.cpp:447 #10 0x0000007f85d833fc in android::IPCThreadState::joinThreadPool (this=<optimized out>, isMain=<optimized out>) at frameworks/native/libs/binder/IPCThreadState.cpp:517 #11 0x0000007f85da17e8 in android::PoolThread::threadLoop (this=0x7f77b08b80) at frameworks/native/libs/binder/ProcessState.cpp:63 #12 0x0000007f849f093c in android::Thread::_threadLoop (user=<optimized out>, user@entry=0x7f77b08b80) at system/core/libutils/Threads.cpp:751 #13 0x0000007f86655d1c in android::AndroidRuntime::javaThreadShell (args=<optimized out>) at frameworks/base/core/jni/AndroidRuntime.cpp:1201 #14 0x0000007f851a7c58 in __pthread_start (arg=<optimized out>) at bionic/libc/bionic/pthread_create.cpp:198 #15 0x0000007f85150100 in __start_thread (fn=0x1, arg=0x7148dd88) at bionic/libc/bionic/clone.cpp:41 #16 0x0000000000000000 in ?? () (gdb) f 6 #6 0x0000007f866b4454 in JavaBBinder::onTransact (this=0x7f752b0780, code=50, data=..., reply=0x7f7a5ff100, flags=17) at frameworks/base/core/jni/android_util_Binder.cpp:265 warning: Source file is more recent than executable. 265 code, reinterpret_cast<jlong>(&data), reinterpret_cast<jlong>(reply), flags); (gdb) list 263,266 263 //printf("\n"); 264 jboolean res = env->CallBooleanMethod(mObject, gBinderOffsets.mExecTransact, 265 code, reinterpret_cast<jlong>(&data), reinterpret_cast<jlong>(reply), flags); 266
在 f6:android_util_Binder.cpp:265 Native的 JavaBBinder::onTransact 函数中,通过 CallBooleanMethod 来调用 gBinderOffsets.mExecTransact (methodID,其初始化就不做介绍了)这个java 方法;
从 f6 到 f0,仍然都是Native函数,其遵循的仍然是 ARM调用约定,且目前还没有真正跳转到 gBinderOffsets.mExecTransact 这个java函数,
在开始跳转之前,有一点需要关注的是: 线程的状态(这里指该线程在虚拟机中的状态)的切换;
在 f4 中:
(gdb) down #4 0x0000007f86ae357c in art::JNI::CallBooleanMethodV (env=<optimized out>, obj=<optimized out>, mid=<optimized out>, args=...) at art/runtime/jni_internal.cc:717 warning: Source file is more recent than executable. 717 return InvokeVirtualOrInterfaceWithVarArgs(soa, obj, mid, args).GetZ(); (gdb) list 713,718 713 static jboolean CallBooleanMethodV(JNIEnv* env, jobject obj, jmethodID mid, va_list args) { 714 CHECK_NON_NULL_ARGUMENT_RETURN_ZERO(obj); 715 CHECK_NON_NULL_ARGUMENT_RETURN_ZERO(mid); 716 ScopedObjectAccess soa(env); 717 return InvokeVirtualOrInterfaceWithVarArgs(soa, obj, mid, args).GetZ(); 718 }
在 line 716: ScopedObjectAccess soa(env); 中完成了 Thread 状态的切换(具体的切换代码在 ScopedObjectAccess以及其父类的构造函数中完成),
把线程状态切换成了 Runnable状态,并且 Shared Hold mutator_lock_; 即线程在开始执行 Java代码之前已经提前把线程状态切换成了 Runnable 状态;
说明:当线程在虚拟机中对应的状态是 Runnable状态时,才能执行 java 代码;当需要执行 Native 代码时,同样提前切换线程状态到 Native状态;
gdb) down #1 0x0000007f8265ae54 in art::ArtMethod::Invoke (this=0x7148dd88, self=0x7f75260c00, args=0x7f7a5fedb0, args_size=28, result=0x7f7a5fed90, shorty=0x73654521 "ZIJJI") at art/runtime/art_method.cc:289 (gdb) art_get_method_name_by_method_id this android.os.Binder.execTransact "(IJJI)Z" (gdb) list 288,292 288 if (!IsStatic()) { 289 (*art_quick_invoke_stub)(this, args, args_size, self, result, shorty); 290 } else { 291 (*art_quick_invoke_static_stub)(this, args, args_size, self, result, shorty); 292 } private boolean execTransact(int code, long dataObj, long replyObj, int flags);
非 static的java 函数调用前的准备工作是 art_quick_invoke_stub 来做的,而静态的调用,其准备工作是 art_quick_invoke_static_stub负责;
看其参数个数及顺序,发现并无区别;依次是:art::ArtMethod指针,参数指针,参数大小(byte),art::Thread指针,指向栈上存放返回值的指针 result,java函数对应的 short signature;
我们查一下 args这个参数在哪准备的,因为这个args里面保存着 execTransact(int code, long dataObj, long replyObj, int flags);这个java函数的所有参数;
(gdb) f 3 #3 0x0000007f829f4574 in art::InvokeVirtualOrInterfaceWithVarArgs (soa=..., obj=<optimized out>, mid=<optimized out>, args=...) at art/runtime/reflection.cc:557 557 InvokeWithArgArray(soa, method, &arg_array, &result, shorty); (gdb) list 553,557 553 const char* shorty = method->GetInterfaceMethodIfProxy(sizeof(void*))->GetShorty(&shorty_len); 554 JValue result; 555 ArgArray arg_array(shorty, shorty_len); 556 arg_array.BuildArgArrayFromVarArgs(soa, receiver, args); 557 InvokeWithArgArray(soa, method, &arg_array, &result, shorty); @art/runtime/reflection.cc void Append(uint32_t value) { arg_array_[num_bytes_ / 4] = value; num_bytes_ += 4; } void BuildArgArrayFromVarArgs(const ScopedObjectAccessAlreadyRunnable& soa, mirror::Object* receiver, va_list ap) SHARED_REQUIRES(Locks::mutator_lock_) { // Set receiver if non-null (method is not static) if (receiver != nullptr) { Append(receiver); } for (size_t i = 1; i < shorty_len_; ++i) { switch (shorty_[i]) { case 'Z': case 'B': case 'C': case 'S': case 'I': Append(va_arg(ap, jint)); break; case 'F': AppendFloat(va_arg(ap, jdouble)); break; case 'L': Append(soa.Decode<mirror::Object*>(va_arg(ap, jobject))); break; case 'D': AppendDouble(va_arg(ap, jdouble)); break; case 'J': AppendWide(va_arg(ap, jlong)); break; #ifndef NDEBUG default: LOG(FATAL) << "Unexpected shorty character: " << shorty_[i]; #endif } } } 除了 double,long,都是 4byte; // Primitives. case JDWP::JT_BYTE: return 'B'; case JDWP::JT_CHAR: return 'C'; case JDWP::JT_FLOAT: return 'F'; case JDWP::JT_DOUBLE: return 'D'; 8byte case JDWP::JT_INT: return 'I'; case JDWP::JT_LONG: return 'J'; 8byte case JDWP::JT_SHORT: return 'S'; case JDWP::JT_VOID: return 'V'; case JDWP::JT_BOOLEAN: return 'Z'; // Reference types. case JDWP::JT_ARRAY: case JDWP::JT_OBJECT: case JDWP::JT_STRING: case JDWP::JT_THREAD: case JDWP::JT_THREAD_GROUP: case JDWP::JT_CLASS_LOADER: case JDWP::JT_CLASS_OBJECT: return 'L';
参数是通过 ArgArray 的 BuildArgArrayFromVarArgs()这个函数准备的,保存在其成员 arg_array_数组里,通过AppendXXX()来填充数组;
从这个函数里,可以看到数据的顺序:
非static方法时,传递的receiver(java 类对象)不是 nullptr,会把this指针放在 arg_array_的第一个元素里;
而调用static方法时,参数列表中是没有this对象的,arg_array_的第一个元素就是对应 static函数的第一个参数;
对于我们正在分析的函数 private boolean execTransact(int code, long dataObj, long replyObj, int flags);为其构建的 arg_array_的情况是:
|
this(Binder.java)
| code | dataObj | replyObj | flags |
|---|
在接下来的调用 (*art_quick_invoke_stub)(this, args, args_size, self, result, shorty);时, args就是 arg_array_首地址;
我们看下,在art::ArtMethod::Invoke函数跳转到 art_quick_invoke_stub之前的参数:
0x0000007f8265ae38 <+184>: mov x0, x20 ;this(ArtMethod) 0x0000007f8265ae3c <+188>: mov x1, x22 ; args 0x0000007f8265ae40 <+192>: mov w2, w24 ; args_size 0x0000007f8265ae44 <+196>: mov x3, x21 ; self(art::Thread*) 0x0000007f8265ae48 <+200>: mov x4, x19 ; result 0x0000007f8265ae4c <+204>: mov x5, x23 ; shorty 0x0000007f8265ae50 <+208>: bl 0x7f8264daf0 <art_quick_invoke_stub>
ARM64的调用约定,前面的 6个参数依次存放在 x0~x5;
函数 art_quick_invoke_stub ,是为了执行 java 函数之前做一个准备工作;
接下来,我们跳转到 art_quick_invoke_stub:
(gdb) disassemble Dump of assembler code for function art_quick_invoke_stub: => 0x0000007f8264daf0 <+0>: mov x9, sp ;x9保存函数 art::ArtMethod::Invoke 的sp 0x0000007f8264daf4 <+4>: add x10, x2, #0x80 ;x2是 arg_size, x10=x2+0x80 0x0000007f8264daf8 <+8>: sub x10, sp, x10 ;x10=sp - x10 0x0000007f8264dafc <+12>: and x10, x10, #0xfffffffffffffff0 ;x10进行16字节对齐 0x0000007f8264db00 <+16>: mov sp, x10 ;sp移动,相当于开辟了 (x9-x10)byte的栈空间,用来存放:1.args (arg_size byte) 2.ArtMethod(8 byte) 3.保存 callee save register (0x78 byte) 0x0000007f8264db04 <+20>: sub x10, x9, #0x78 ;临近上一个frame的 0x78的栈空间,下面的关于 x10的操作,都是在保存reg到,这个range的栈上 0x0000007f8264db08 <+24>: str x28, [x10,#112] 0x0000007f8264db0c <+28>: stp x26, x27, [x10,#96] 0x0000007f8264db10 <+32>: stp x24, x25, [x10,#80] 0x0000007f8264db14 <+36>: stp x22, x23, [x10,#64] 0x0000007f8264db18 <+40>: stp x20, x21, [x10,#48] 0x0000007f8264db1c <+44>: stp x9, x19, [x10,#32] 0x0000007f8264db20 <+48>: stp x4, x5, [x10,#16] ;其中x4,存放的是 JValue result的地址,最终java函数的返回值要存入 result中 0x0000007f8264db24 <+52>: stp x29, x30, [x10] ;紧邻上一个 frame的 0x78的空间填充完成; 0x0000007f8264db28 <+56>: mov x29, x10 ;记录 frame pointer 0x0000007f8264db2c <+60>: mov x19, x3 ;把 Thread* 放到 x19 来保存 0x0000007f8264db30 <+64>: add x9, sp, #0x8 ;跳过当前frame栈顶的第一个数据,即跳过 ArtMethod,x9指向第二个数据 0x0000007f8264db34 <+68>: cmp w2, #0x0 ; 如果 arg_size 等于 0则跳转,否则从 arg_array 拷贝数据到栈上,直到arg_array中所有数据拷贝到栈上 0x0000007f8264db38 <+72>: b.eq 0x7f8264db4c <art_quick_invoke_stub+92> 0x0000007f8264db3c <+76>: sub w2, w2, #0x4 ; index = arg_size - 4,index = index -4 0x0000007f8264db40 <+80>: ldr w10, [x1,x2] ; 从 arg_array取出index对应的arg,从后向前获取数组元素 0x0000007f8264db44 <+84>: str w10, [x9,x2] ; 将 arg存放到栈上的 args区域,每次拷贝 4 byte,先拷贝到高地址,再拷贝到低地址 0x0000007f8264db48 <+88>: b 0x7f8264db34 <art_quick_invoke_stub+68> ; 继续拷贝 0x0000007f8264db4c <+92>: str xzr, [sp] ; 把栈顶的第一个数据填充0,实际上这个数据对应一个 ArtMethod指针 0x0000007f8264db50 <+96>: adr x11, 0x7f8264dbe0 <art_quick_invoke_stub+240> ; 记录该函数的几个入口 0x0000007f8264db54 <+100>: adr x12, 0x7f8264dc28 <art_quick_invoke_stub+312> 0x0000007f8264db58 <+104>: adr x13, 0x7f8264dc70 <art_quick_invoke_stub+384> 0x0000007f8264db5c <+108>: adr x14, 0x7f8264dcd0 <art_quick_invoke_stub+480> 0x0000007f8264db60 <+112>: mov x8, #0x0 // #0 ; integer offset 0x0000007f8264db64 <+116>: mov x15, #0x0 // #0 ; floating offset 0x0000007f8264db68 <+120>: add x10, x5, #0x1 ; short signatur的地址,+0x1是因为第一个是 return value的shorty,我们是准备参数,所以要跳过: shorty=0x73654521 "ZIJJI" 0x0000007f8264db6c <+124>: ldr w1, [x9],#4 ; x9指向栈上的第一个参数,当函数不是static时,第一个参数是函数对应的类this对象,这里把 this放到 r1作为参数传递 0x0000007f8264db70 <+128>: ldrb w17, [x10],#1 0x0000007f8264db74 <+132>: cbz w17, 0x7f8264dd30 <art_quick_invoke_stub+576>
在此时,art_quick_invoke_stub 的栈空间情况:
由于 arg_size = 28 = 4(append(this)) + (4+8+8+4)"IJJI" (遍历shorty时从1开始,忽略返回值);
所以 x2+0x80 = 28+0x80 = 0x1c+0x80 = 0x9c,所以 framesize = 0xa0 = 160 byte;
讲一下这里的对齐,很显然,x10= sp - 10 过后,要和 #0xfffffffffffffff0 做and运算,运算后会把末尾丢掉,由于栈是从高地址向低地址开辟,所以相当于多开辟了部分空间;
栈空间如下:
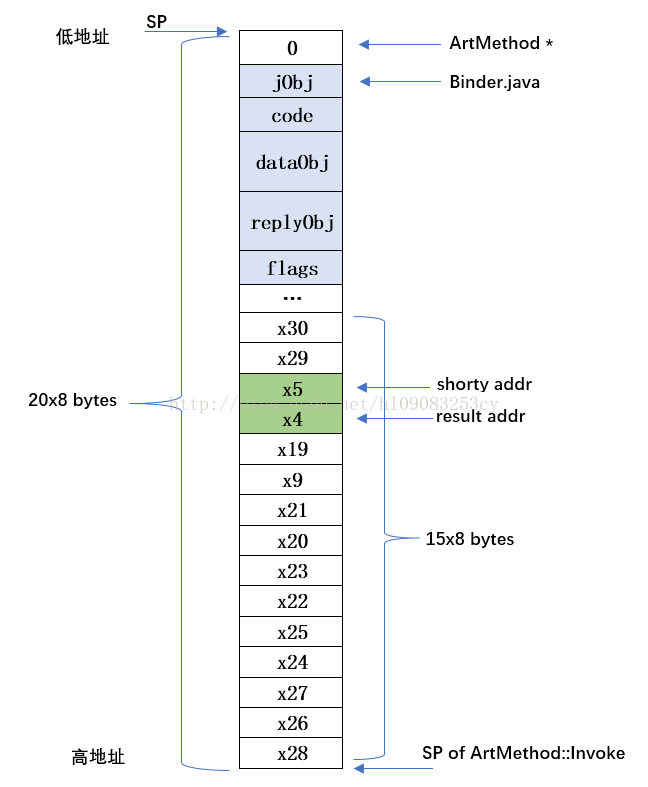
已经贴出来的 art_quick_invoke_stub 的这段代码就已经把栈空间准备好了;
此时的寄存器情况:
x0: ArtMethod*
x1: this (Binder.java)
其余参数还没有完成准备;
ARM64 上 art_quick_invoke_stub调用 java 函数的调用约定:
* Outgoing registers:
* x0 - Method*
* x1-x7 - integer parameters.
* d0-d7 - Floating point parameters.
* xSELF = self
* SP = & of ArtMethod*
* x1 = "this" pointer.
*看起来我们才刚刚准备好 x0,x1 ,xSELF(x19) 和 SP;继续看剩下的部分代码:
0x0000007f8264db68 <+120>: add x10, x5, #0x1 ; short signatur的地址,+0x1是因为第一个是 return value的shorty,我们是准备参数,所以要跳过: shorty=0x73654521 "ZIJJI" 0x0000007f8264db6c <+124>: ldr w1, [x9],#4 ; x9指向栈上的第一个参数,当函数不是static时,第一个参数是函数对应的类this对象,这里把 this放到 r1作为参数传递,并且x9=x9+4,指向arg1 0x0000007f8264db70 <+128>: ldrb w17, [x10],#1 ; 从shorty signature获取一个byte到 w17,并且 x10=x10+1,指向signature下一个字节 0x0000007f8264db74 <+132>: cbz w17, 0x7f8264dd30 <art_quick_invoke_stub+576> ; 0,字符串结束,signature结束,参数准备完成,跳转到 +576位置,准备执行 0x0000007f8264db78 <+136>: cmp w17, #0x46 ; 是否是字符 'F',floating 参数 0x0000007f8264db7c <+140>: b.ne 0x7f8264db90 <art_quick_invoke_stub+160> ; 如果不是字符 'F',进行下一步判断是否字符 'D' 0x0000007f8264db80 <+144>: cmp x15, #0x60 ; 判断 floating register是否用完了 0x0000007f8264db84 <+148>: b.eq 0x7f8264dbd0 <art_quick_invoke_stub+224> ; 如 0x0000007f8264db88 <+152>: add x17, x13, x15 0x0000007f8264db8c <+156>: br x17 0x0000007f8264db90 <+160>: cmp w17, #0x44 ; 是否是字符 'D',double 参数 0x0000007f8264db94 <+164>: b.ne 0x7f8264dba8 <art_quick_invoke_stub+184> ; 如果不是字符 'D',进行下一步判断是否字符 'J' 0x0000007f8264db98 <+168>: cmp x15, #0x60 ; 判断 floating register是否用完了 0x0000007f8264db9c <+172>: b.eq 0x7f8264dbd8 <art_quick_invoke_stub+232> 0x0000007f8264dba0 <+176>: add x17, x14, x15 0x0000007f8264dba4 <+180>: br x17 0x0000007f8264dba8 <+184>: cmp w17, #0x4a ; 是否是字符 'J',long 参数 0x0000007f8264dbac <+188>: b.ne 0x7f8264dbc0 <art_quick_invoke_stub+208> ; 如果不是字符 'J',进入 else分支 0x0000007f8264dbb0 <+192>: cmp x8, #0x48 ; 判断 integer register是否用完了 0x0000007f8264dbb4 <+196>: b.eq 0x7f8264dbd8 <art_quick_invoke_stub+232> 0x0000007f8264dbb8 <+200>: add x17, x12, x8 ; 如果是 long参数,跳转到 x12 + x8(code offset)处,进行load参数;x12= 0x7f8264dc28 <art_quick_invoke_stub+312> 0x0000007f8264dbbc <+204>: br x17 0x0000007f8264dbc0 <+208>: cmp x8, #0x48 ; 不是字符 'F', 'D', 'J',判断 integer register是否用完了 0x0000007f8264dbc4 <+212>: b.eq 0x7f8264dbd0 <art_quick_invoke_stub+224> 0x0000007f8264dbc8 <+216>: add x17, x11, x8 ; 这个实例中,shorty "IJJI",第一个参数进入else分支, x17=x11+0,而x11在上面初始化过,是 0x7f8264dbe0 <art_quick_invoke_stub+240> 0x0000007f8264dbcc <+220>: br x17 0x0000007f8264dbd0 <+224>: add x9, x9, #0x4 ; x9向栈底移动 4byte,(上一个参数是floating,会走到该分支),移动后,x9指向floating参数后的下一个参数 0x0000007f8264dbd4 <+228>: b 0x7f8264db70 <art_quick_invoke_stub+128> ; 跳转到 +128处,获取第二个参数对应的 shorty,并进行过滤 0x0000007f8264dbd8 <+232>: add x9, x9, #0x8 ; x9向栈底移动 8byte,(当上一个参数是 double/long时,会走到该分支),移动后,x9指向 double/long 参数后的下一个参数 0x0000007f8264dbdc <+236>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dbe0 <+240>: ldr w2, [x9],#4 ; load java method的第2个参数, *************当需要load的参数是 4 byte且是integer,对应的分支**************************** 0x0000007f8264dbe4 <+244>: add x8, x8, #0xc ; x8 = x8+12,代码偏移 0x0000007f8264dbe8 <+248>: b 0x7f8264db70 <art_quick_invoke_stub+128> ; 准备下一个参数 0x0000007f8264dbec <+252>: ldr w3, [x9],#4 0x0000007f8264dbf0 <+256>: add x8, x8, #0xc 0x0000007f8264dbf4 <+260>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dbf8 <+264>: ldr w4, [x9],#4 0x0000007f8264dbfc <+268>: add x8, x8, #0xc 0x0000007f8264dc00 <+272>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc04 <+276>: ldr w5, [x9],#4 ; load java method的第5个参数 0x0000007f8264dc08 <+280>: add x8, x8, #0xc 0x0000007f8264dc0c <+284>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc10 <+288>: ldr w6, [x9],#4 0x0000007f8264dc14 <+292>: add x8, x8, #0xc 0x0000007f8264dc18 <+296>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc1c <+300>: ldr w7, [x9],#4 0x0000007f8264dc20 <+304>: add x8, x8, #0xc 0x0000007f8264dc24 <+308>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc28 <+312>: ldr x2, [x9],#8 ; ****************************当需要load的参数是 8 byte且是integer ,对应的分支**************************** 0x0000007f8264dc2c <+316>: add x8, x8, #0xc 0x0000007f8264dc30 <+320>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc34 <+324>: ldr x3, [x9],#8 ; load java method的第3个参数 0x0000007f8264dc38 <+328>: add x8, x8, #0xc ; x8 = x8+12,代码偏移 0x0000007f8264dc3c <+332>: b 0x7f8264db70 <art_quick_invoke_stub+128> ; 准备下一个参数 0x0000007f8264dc40 <+336>: ldr x4, [x9],#8 ; load java method的第4个参数 0x0000007f8264dc44 <+340>: add x8, x8, #0xc 0x0000007f8264dc48 <+344>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc4c <+348>: ldr x5, [x9],#8 0x0000007f8264dc50 <+352>: add x8, x8, #0xc 0x0000007f8264dc54 <+356>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc58 <+360>: ldr x6, [x9],#8 0x0000007f8264dc5c <+364>: add x8, x8, #0xc 0x0000007f8264dc60 <+368>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc64 <+372>: ldr x7, [x9],#8 0x0000007f8264dc68 <+376>: add x8, x8, #0xc 0x0000007f8264dc6c <+380>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc70 <+384>: ldr s0, [x9],#4 ;****************************当需要load的参数是 4 byte且是 floating 时的分支**************************** 0x0000007f8264dc74 <+388>: add x15, x15, #0xc 0x0000007f8264dc78 <+392>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc7c <+396>: ldr s1, [x9],#4 0x0000007f8264dc80 <+400>: add x15, x15, #0xc ---Type <return> to continue, or q <return> to quit--- 0x0000007f8264dc84 <+404>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc88 <+408>: ldr s2, [x9],#4 0x0000007f8264dc8c <+412>: add x15, x15, #0xc 0x0000007f8264dc90 <+416>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dc94 <+420>: ldr s3, [x9],#4 0x0000007f8264dc98 <+424>: add x15, x15, #0xc 0x0000007f8264dc9c <+428>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dca0 <+432>: ldr s4, [x9],#4 0x0000007f8264dca4 <+436>: add x15, x15, #0xc 0x0000007f8264dca8 <+440>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dcac <+444>: ldr s5, [x9],#4 0x0000007f8264dcb0 <+448>: add x15, x15, #0xc 0x0000007f8264dcb4 <+452>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dcb8 <+456>: ldr s6, [x9],#4 0x0000007f8264dcbc <+460>: add x15, x15, #0xc 0x0000007f8264dcc0 <+464>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dcc4 <+468>: ldr s7, [x9],#4 0x0000007f8264dcc8 <+472>: add x15, x15, #0xc 0x0000007f8264dccc <+476>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dcd0 <+480>: ldr d0, [x9],#8 ;****************************当需要load的参数是 8 byte,且是 double 时的分支**************************** 0x0000007f8264dcd4 <+484>: add x15, x15, #0xc 0x0000007f8264dcd8 <+488>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dcdc <+492>: ldr d1, [x9],#8 0x0000007f8264dce0 <+496>: add x15, x15, #0xc 0x0000007f8264dce4 <+500>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dce8 <+504>: ldr d2, [x9],#8 0x0000007f8264dcec <+508>: add x15, x15, #0xc 0x0000007f8264dcf0 <+512>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dcf4 <+516>: ldr d3, [x9],#8 0x0000007f8264dcf8 <+520>: add x15, x15, #0xc 0x0000007f8264dcfc <+524>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dd00 <+528>: ldr d4, [x9],#8 0x0000007f8264dd04 <+532>: add x15, x15, #0xc 0x0000007f8264dd08 <+536>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dd0c <+540>: ldr d5, [x9],#8 0x0000007f8264dd10 <+544>: add x15, x15, #0xc 0x0000007f8264dd14 <+548>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dd18 <+552>: ldr d6, [x9],#8 0x0000007f8264dd1c <+556>: add x15, x15, #0xc 0x0000007f8264dd20 <+560>: b 0x7f8264db70 <art_quick_invoke_stub+128> 0x0000007f8264dd24 <+564>: ldr d7, [x9],#8 0x0000007f8264dd28 <+568>: add x15, x15, #0xc 0x0000007f8264dd2c <+572>: b 0x7f8264db70 <art_quick_invoke_stub+128> ;**************** 准备参数的代码,至此结束,参数已经准备完毕 ***************** 0x0000007f8264dd30 <+576>: ldr x9, [x0,#48] ; x0是 ArtMethod*,48是64bit时METHOD_QUICK_CODE_OFFSET对应的值,这条指令执行结束后,x9的值是 entry_point_from_quick_compiled_code_ 0x0000007f8264dd34 <+580>: blr x9 ; 跳转到 entry_point_from_quick_compiled_code_ 0x0000007f8264dd38 <+584>: ldp x4, x5, [x29,#16] ; 恢复寄存器,准备返回,其中x4 是 JValue result的地址;x5是shorty addr 0x0000007f8264dd3c <+588>: ldr x28, [x29,#112] 0x0000007f8264dd40 <+592>: ldp x26, x27, [x29,#96] 0x0000007f8264dd44 <+596>: ldp x24, x25, [x29,#80] 0x0000007f8264dd48 <+600>: ldp x22, x23, [x29,#64] 0x0000007f8264dd4c <+604>: ldp x20, x21, [x29,#48] 0x0000007f8264dd50 <+608>: ldrb w10, [x5] ;从x5获取 shorty第一个字节(代表返回值) 0x0000007f8264dd54 <+612>: cmp w10, #0x56 ;返回值的shorty是否 'V',即void 0x0000007f8264dd58 <+616>: b.eq 0x7f8264dd80 <art_quick_invoke_stub+656> 0x0000007f8264dd5c <+620>: cmp w10, #0x44 ;'D' 是否 double 返回值 0x0000007f8264dd60 <+624>: b.ne 0x7f8264dd6c <art_quick_invoke_stub+636> 0x0000007f8264dd64 <+628>: str d0, [x4] ;保存double值到 result中 0x0000007f8264dd68 <+632>: b 0x7f8264dd80 <art_quick_invoke_stub+656> 0x0000007f8264dd6c <+636>: cmp w10, #0x46 ;'F' 是否 floating 返回值 0x0000007f8264dd70 <+640>: b.ne 0x7f8264dd7c <art_quick_invoke_stub+652> 0x0000007f8264dd74 <+644>: str s0, [x4] ;保存 floating值到 result中 0x0000007f8264dd78 <+648>: b 0x7f8264dd80 <art_quick_invoke_stub+656> 0x0000007f8264dd7c <+652>: str x0, [x4] ;返回值类型不是 'V','D','F', 保存 x0到result中,不关注 32bit/64bit 0x0000007f8264dd80 <+656>: ldp x2, x19, [x29,#32] 0x0000007f8264dd84 <+660>: mov sp, x2 0x0000007f8264dd88 <+664>: ldp x29, x30, [x29] 0x0000007f8264dd8c <+668>: ret
TODO:
1.从Native调用 java method时,总是跳转到 ArtMethod的 entry_point_from_quick_compiled_code_,假如这个method没有被编译,那么它就没有对应的 native code,那怎么执行呢,后续分析 trampoline;
答:在 ClassLinker::LinkCode的时候,如果一个非static,非jni的method 没有编译 quick code,那么其就会通过:
method→SetEntryPointFromQuickCompiledCode(GetQuickToInterpreterBridge());把 entry_point_from_quick_compiled_code_ 设置为 art_quick_to_interpreter_bridge,
最终调用 art_quick_to_interpreter_bridge时会跳转到 artQuickToInterpreterBridge() → interpreter::EnterInterpreterFromEntryPoint() → interpreter::Execute() → ExecuteMterpImp()进行解释执行代码;
流程图:















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









