







系统学习深度学习(二十)--ResNet,DenseNet,以及残差家族
转自:http://blog.csdn.net/cv_family_z/article/details/50328175
CVPR2016
https://github.com/KaimingHe/deep-residual-networks
这是微软方面的最新研究成果, 在第六届ImageNet年度图像识别测试中,微软研究院的计算机图像识别系统在几个类别的测试中获得第一名。
本文是解决超深度CNN网络训练问题,152层及尝试了1000层。
随着CNN网络的发展,尤其的VGG网络的提出,大家发现网络的层数是一个关键因素,貌似越深的网络效果越好。但是随着网络层数的增加,问题也随之而来。
首先一个问题是 vanishing/exploding gradients,即梯度的消失或发散。这就导致训练难以收敛。但是随着 normalized initialization [23, 9, 37, 13] and intermediate normalization layers[16]的提出,解决了这个问题。
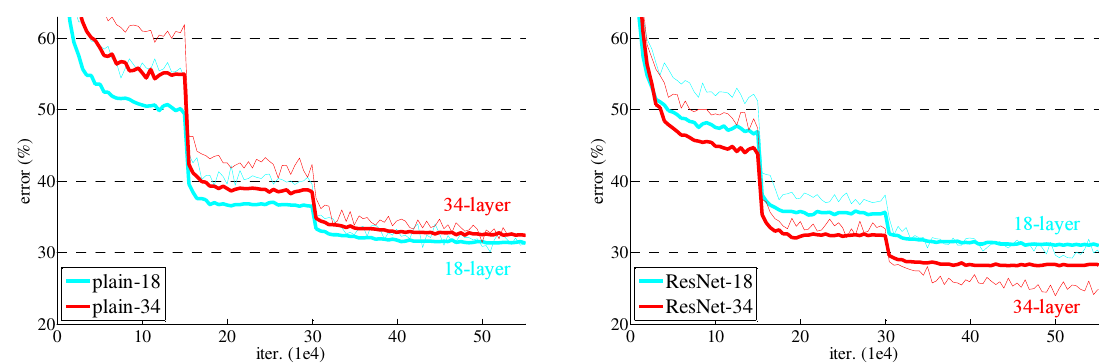
当收敛问题解决后,又一个问题暴露出来:随着网络深度的增加,系统精度得到饱和之后,迅速的下滑。让人意外的是这个性能下降不是过拟合导致的。如文献 [11, 42]指出,对一个合适深度的模型加入额外的层数导致训练误差变大。如下图所示:
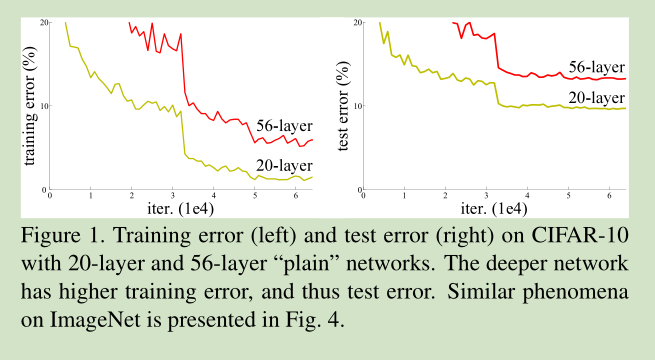
如果我们加入额外的 层只是一个 identity mapping,那么随着深度的增加,训练误差并没有随之增加。所以我们认为可能存在另一种构建方法,随着深度的增加,训练误差不会增加,只是我们没有找到该方法而已。
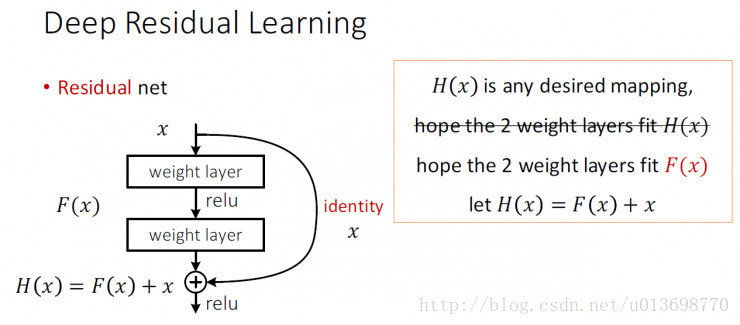
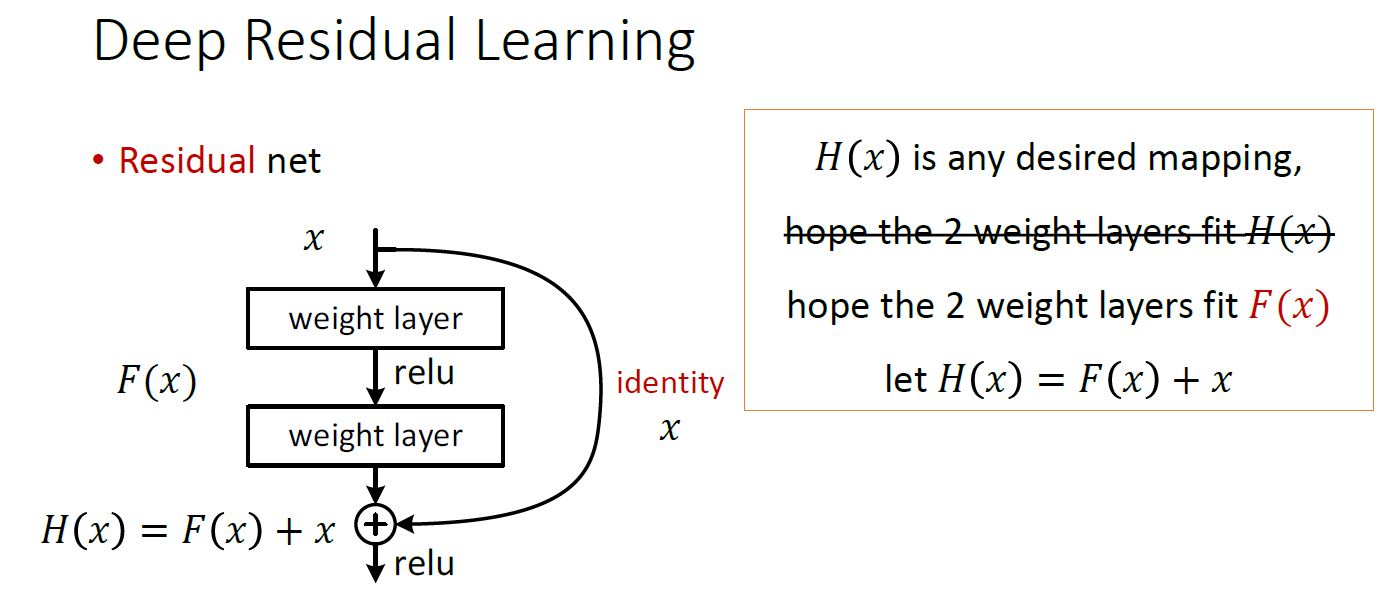
这里我们提出一个 deep residual learning 框架来解决这种因为深度增加而导致性能下降问题。 假设我们期望的网络层关系映射为 H(x), 我们让 the stacked nonlinear layers 拟合另一个映射, F(x):= H(x)-x , 那么原先的映射就是 F(x)+x。 这里我们假设优化残差映射F(x) 比优化原来的映射 H(x)容易。
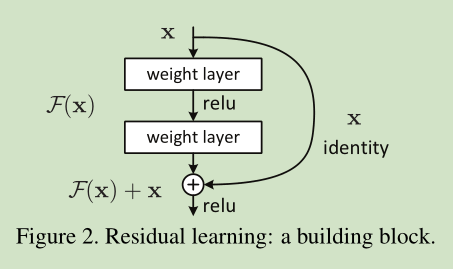
F(x)+x 可以通过shortcut connections 来实现,如下图所示:
2 Related Work
Residual Representations
以前关于残差表示的文献表明,问题的重新表示或预处理会简化问题的优化。 These methods suggest that a good reformulation or preconditioning can simplify the optimization
Shortcut Connections
CNN网络以前对shortcut connections 也有所应用。
3 Deep Residual Learning
3.1. Residual Learning
这里我们首先求取残差映射 F(x):= H(x)-x,那么原先的映射就是 F(x)+x。尽管这两个映射应该都可以近似理论真值映射 the desired functions (as hypothesized),但是它俩的学习难度是不一样的。
这种改写启发于 图1中性能退化问题违反直觉的现象。正如前言所说,如果增加的层数可以构建为一个 identity mappings,那么增加层数后的网络训练误差应该不会增加,与没增加之前相比较。性能退化问题暗示多个非线性网络层用于近似identity mappings 可能有困难。使用残差学习改写问题之后,如果identity mappings 是最优的,那么优化问题变得很简单,直接将多层非线性网络参数趋0。
实际中,identity mappings 不太可能是最优的,但是上述改写问题可能对问题提供有效的预先处理 (provide reasonable preconditioning)。如果最优函数接近identity mappings,那么优化将会变得容易些。 实验证明该思路是对的。
3.2. Identity Mapping by Shortcuts
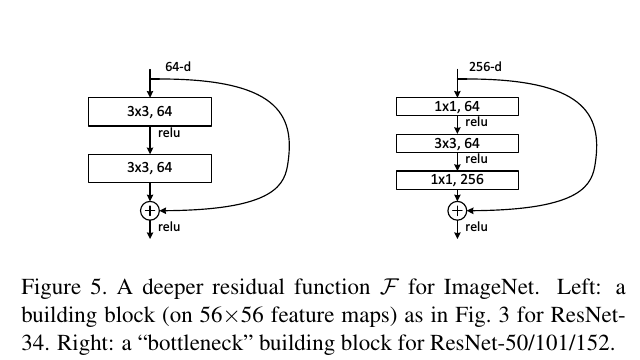
图2为一个模块。A building block
公式定义如下:
这里假定输入输出维数一致,如果不一样,可以通过 linear projection 转成一样的。
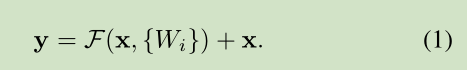
3.3. Network Architectures
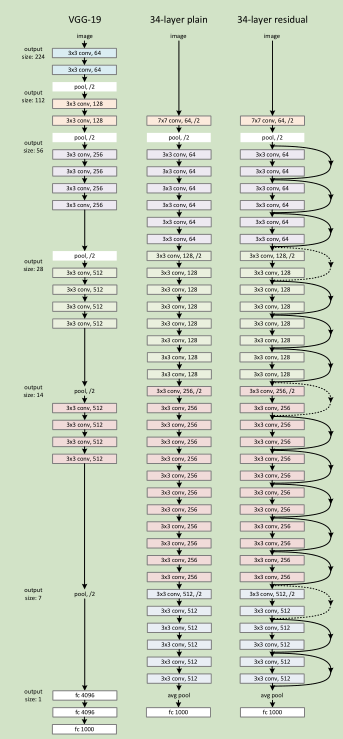

Plain Network 主要是受 VGG 网络启发,主要采用3*3滤波器,遵循两个设计原则:1)对于相同输出特征图尺寸,卷积层有相同个数的滤波器,2)如果特征图尺寸缩小一半,滤波器个数加倍以保持每个层的计算复杂度。通过步长为2的卷积来进行降采样。一共34个权重层。
需要指出,我们这个网络与VGG相比,滤波器要少,复杂度要小。
Residual Network 主要是在 上述的 plain network上加入 shortcut connections
3.4. Implementation
针对 ImageNet网络的实现,我们遵循【21,41】的实践,图像以较小的边缩放至[256,480],这样便于 scale augmentation,然后从中随机裁出 224*224,采用【21,16】文献的方法。
4 Experiments
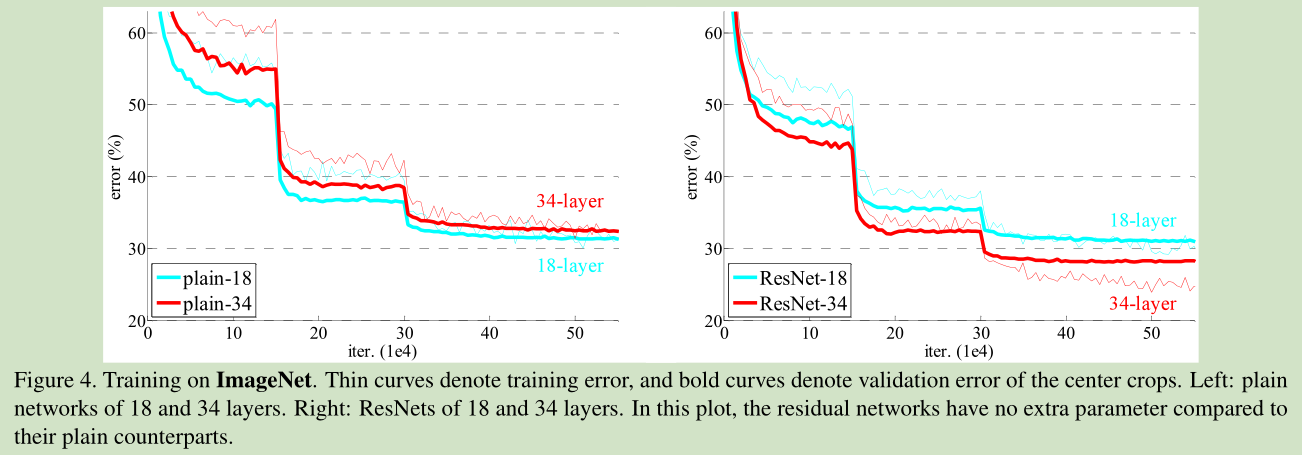
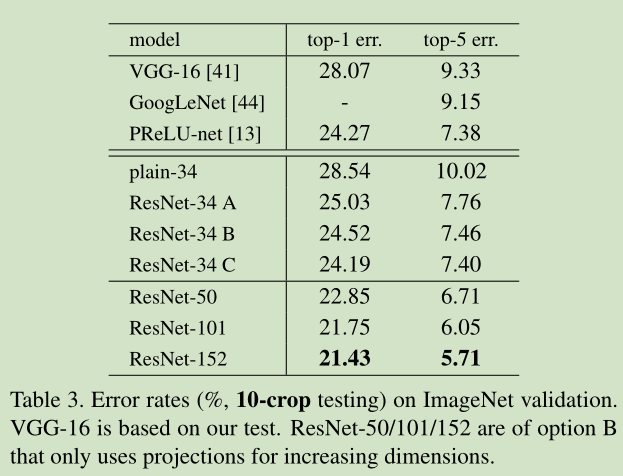
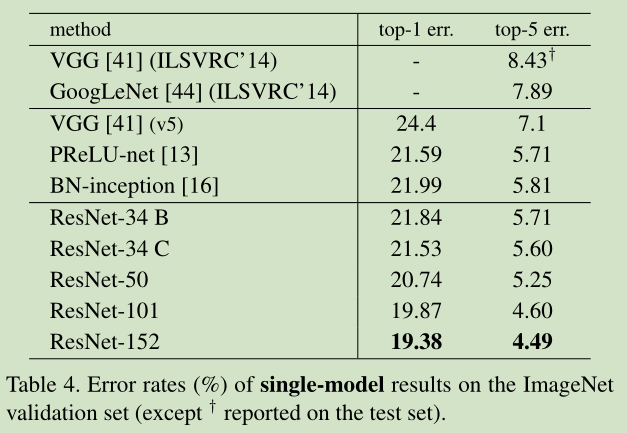
补充1:http://blog.csdn.net/buyi_shizi/article/details/53336192
对ResNet的解读
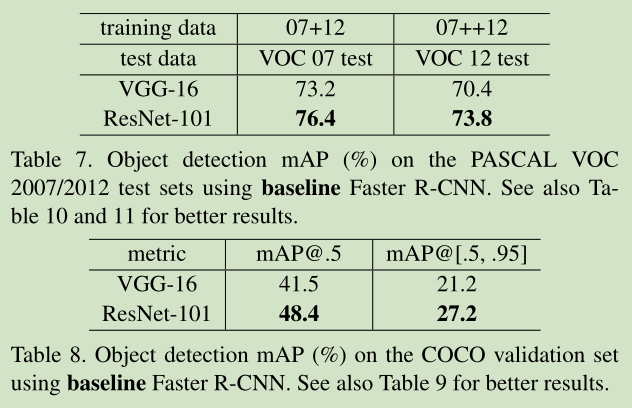
基本的残差网络其实可以从另一个角度来理解,这是从另一篇论文里看到的,如下图所示:
残差网络单元其中可以分解成右图的形式,从图中可以看出,残差网络其实是由多种路径组合的一个网络,直白了说,残差网络其实是很多并行子网络的组合,整个残差网络其实相当于一个多人投票系统(Ensembling)。下面来说明为什么可以这样理解
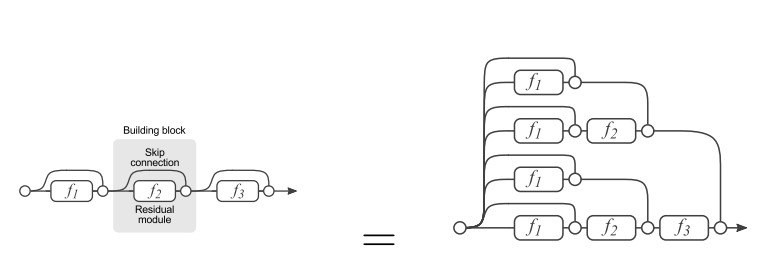
删除网络的一部分
如果把残差网络理解成一个Ensambling系统,那么网络的一部分就相当于少一些投票的人,如果只是删除一个基本的残差单元,对最后的分类结果应该影响很小;而最后的分类错误率应该适合删除的残差单元的个数成正比的,论文里的结论也印证了这个猜测。
下图是比较VGG和ResNet分别删除一层网络的分类错误率变化
下图是ResNet分类错误率和删除的基本残差网络单元个数的关系
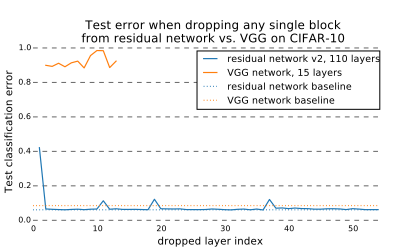
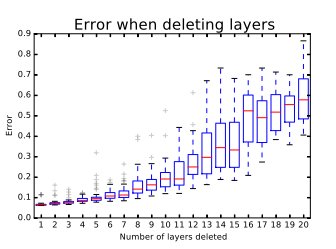
ResNet的真面目
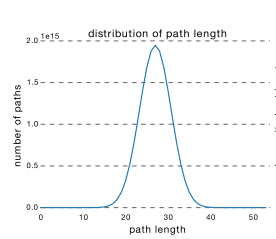
ResNet的确可以做到很深,但是从上面的介绍可以看出,网络很深的路径其实很少,大部分的网络路径其实都集中在中间的路径长度上,如下图所示:
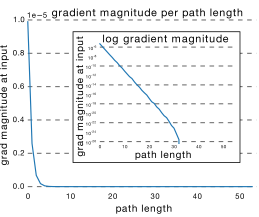
从这可以看出其实ResNet是由大多数中度网络和一小部分浅度网络和深度网络组成的,说明虽然表面上ResNet网络很深,但是其实起实际作用的网络层数并没有很深,我们能来进一步阐述这个问题,我们知道网络越深,梯度就越小,如下图所示
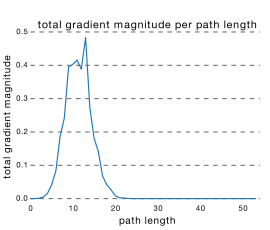
而通过各个路径长度上包含的网络数乘以每个路径的梯度值,我们可以得到ResNet真正起作用的网络是什么样的,如下图所示
我们可以看出大多数的梯度其实都集中在中间的路径上,论文里称为effective path。
从这可以看出其实ResNet只是表面上看起来很深,事实上网络却很浅。
所示ResNet真的解决了深度网络的梯度消失的问题了吗?似乎没有,ResNet其实就是一个多人投票系统。
补充2:http://blog.csdn.net/u013698770/article/details/57977482
resnet是通过什么方式来解决问题的
resnet的出现就是来解决这个问题的。
一般情况下我们的网络如下图所示,相较于resnet,我们称之为plaint net,经过两个神经层之后,输出的如下所示:

但是,在残差的网络中,用,
而输出的,那么,为什么要这么设置呢?
Residual Net 核心思想是,去拟合残差函数 ,选 时效果最好。
因此,
补充3:blog.csdn.net/gavin__zhou/article/details/53445539
这篇博客讲现在很流行的两种网络模型,ResNet和DenseNet,其实可以把DenseNet看做是ResNet的特例
文章地址:
[1]Deep Residual Learning for Image Recognition,CVPR2015
[2]Densely Connected Convolutional Networks,CVPR2016
本篇博客不讲论文的内容,只讲主要思想和我自己的理解,细节问题请自行看论文
Introduction
When it comes to neural network design, the trend in the past few years has pointed in one direction:deeper. 但是问题是:
Is learning better networks as easy as stacking more layers ??
让我们看看在ImageNet上分类winner的网络的深度:
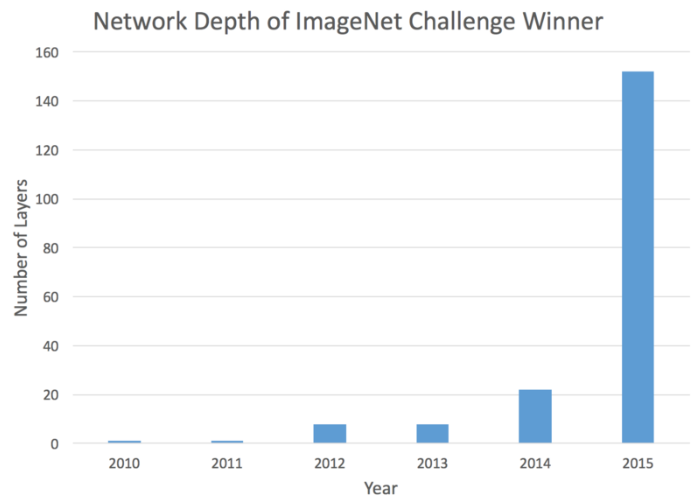
是不是我们通过简单的stack的方式把网络的深度增加就可以提高performance??
答案是NO,存在两个原因
- vanishing/exploding gradients
- degradation problem
Residual
其实思想很简单:
Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. Formally, denoting the desired underlying mapping as H(x),we let the stacked nonlinear layers fit another mapping of F(x): H(x)-x. The original mapping is recast into F(x)+x.
那么学习到的F(x)就是残差.
Shortcut Connections
思想起源于HighWay Nets,shortcut的好处是:
a few intermediate layers are directly connected to auxiliary classifiers for addressing vanishing/exploding gradients.
通过shortcut的方式(Residual)进行stack的nets(ResNet),可以在加深layers上获得更好的效果
对比在ImageNet上的效果:
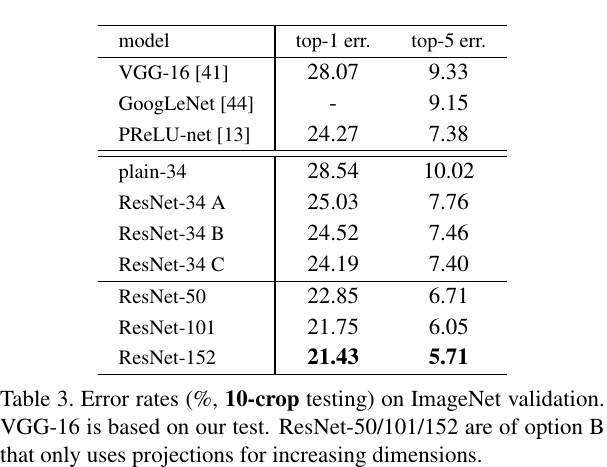
再来个表格对比,更加明显:
DenseNet
一个词概括网络的结构特点就是Dense,一句话概括的话:
For each layer, the feature maps of all preceding layers are treated as separate inputs whereas its own feature maps are passed on as inputs to all subsequent layers.
结构如下所示:
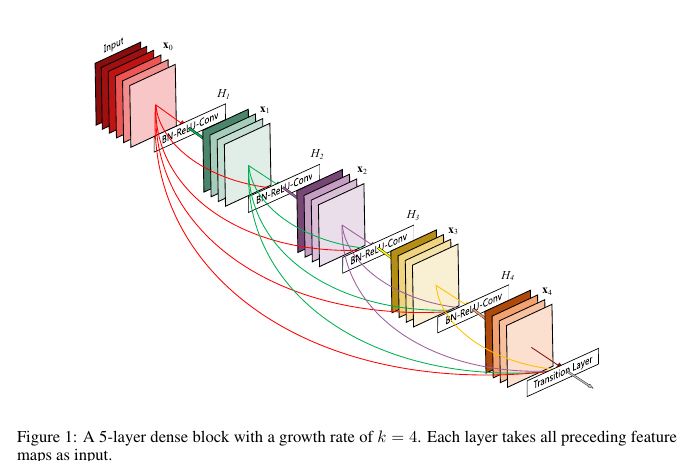
和ResNet相比,最大的区别在于:
Never combine features through summation before they are passed into a layer, instead we provide them all as separate inputs.
对于此网络来说,很明显number of connections适合depth成平方的关系,所以问题是当depth很大的时候是不是已经无法训练了?? 作者是这么说的:
Although the number of connections grows quadratically with depth, the topology encourages heavy feature reuse.
对比ResNet来说:
Prior work has shown that there is great redundancy within the feature maps of the individual layers in ResNets. In DenseNets, all layers have direct access to every feature map from all preceding layers, which means that there is no need to re-learn redundant feature maps. Consequently, DenseNet layers are very narrow (on the order of 12 feature maps per layer) andonly add a small set of feature maps to the “collective knowledge” of the whole network.
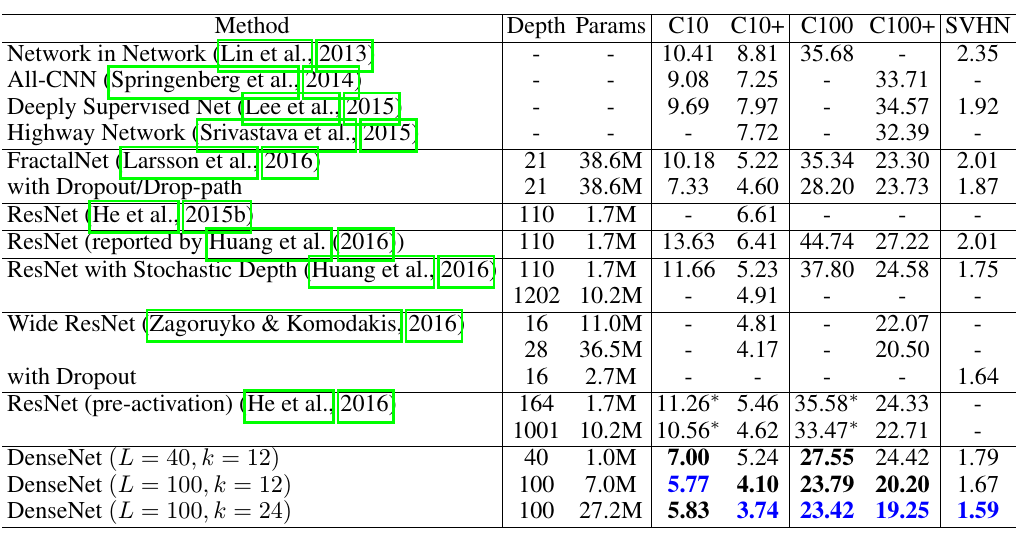
在Cifar 10等上做分类的网络模型是:

结果:
Conclusion
其实无论是ResNet还是DenseNet,核心的思想都是HighWay Nets的思想:
就是skip connection,对于某些的输入不加选择的让其进入之后的layer(skip),从而实现信息流的整合,避免了信息在层间传递的丢失和梯度消失的问题(还抑制了某些噪声的产生).
下面是作者2016年更新的 ResNet,
论文题目:Identity Mappings in Deep Residual Networks
--Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
Abstract
文章分析了 ResNet 中 Identity mapping 为什么比较好,为何能让梯度在网络中顺畅的传递而不会爆炸或消失,实验方面 1001层的 ResNet 在CIFAR10上4.62%的错误率,在CIFAR100和ImageNet上也做了实验。
Introduction
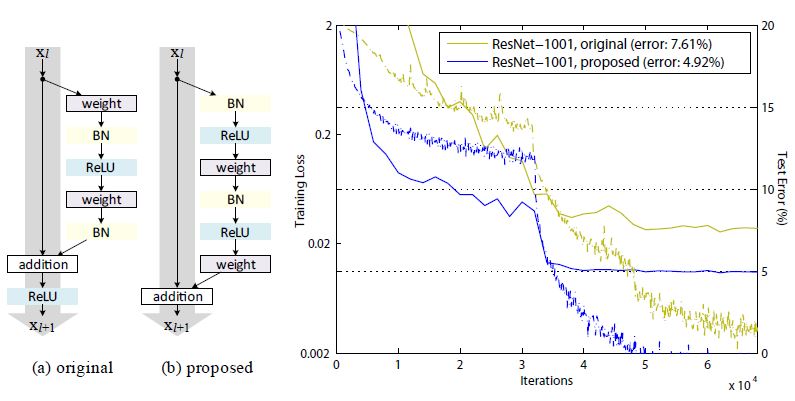
先回顾下ResNet中的 Residual Units:
Residual Units可以如下表示:上图中的H与下面的h不是一个东西,别管上图了,从两篇文章截的图,有点不一样。
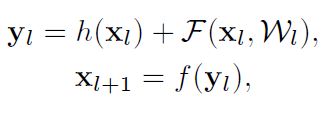
上面公式中:h 表示 shortcut 使用什么形式的变换(Resdual Net论文[1]中给出了A,B,C3种,最后用的 Identity map,也就是 h(x)= x,这篇文章进一步分析了 Identity map 为什么好)
F 是 residual function。F= y-h(x)
f 为Residual Units输出处使用的函数,[1] 中用的ReLU,即上图中最下面那个relu。
本文提出 f 也该用 Identity map。y 为原本应该拟合的输出。
Residual Net 核心思想是,去拟合残差函数 F (F = y - h(x)),选 h(x)=x 时效果最好。
本文分析得出:当 h(x) 和 f(y) 都取 Identity Map 时,signal could be directly propagatedfrom one unit to any other units, in bothforward and backwardpasses。这使训练更容易。
文章实验了各种 h(x) 的选择(Figure 2),发现 Identity map 是最佳选择,achieves the fastest error reduction and lowest training loss
右图虚线是训练误差,实线是测试误差。
Analysis of Deep Residual Networks
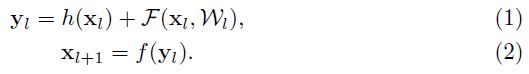
当 h(x) 和 f(y) 都取 Identity Map 时,有

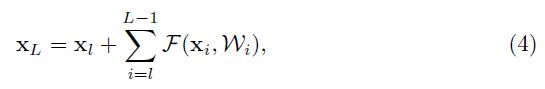
L 为 任意深的 Residual Units
公式(4)在反向求导的过程中有很好的特性:
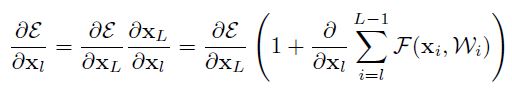
公式(5)有两项:第一项直接把深层的梯度传递到任意浅层,可以看出浅层的梯度很难为0,应该括号内第二项不可能一直为 -1,所以不管参数多小,梯度也不会消失!

注意:[1] 中有些 Residual Units 会增加或减少 feature map 数量,上面的公式就不成立了,这种层在 CIFAR上只有2个,ImageNet上只有3个,取决于图片大小,作者认为对本文结论影响不大。
On the Importance of Identity Skip Connections
本节主要是说明 shortcut 取其他非 Identity map 的变换时,为什么不好。
1.如果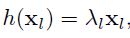
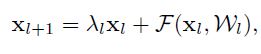
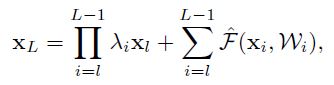
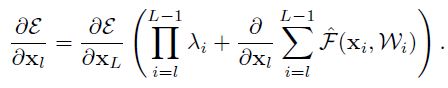
对比公式(8)和(5),第一项不再是 1 了,在很深的网络中,如果 λ>1,括号内第一项会很大,如果 λ<1,会很小或者消失,然后就堵塞了 shortcut,
反向传导的信号只能从第二项传递,网络优化会困难很多(因为第二项是复杂的非线性变换)
2.如果 h(x)取更复杂的变换,如 gating 或 1*1 卷积层 ,也会阻碍信号反向传播的通畅。
Experiments on Skip Connections
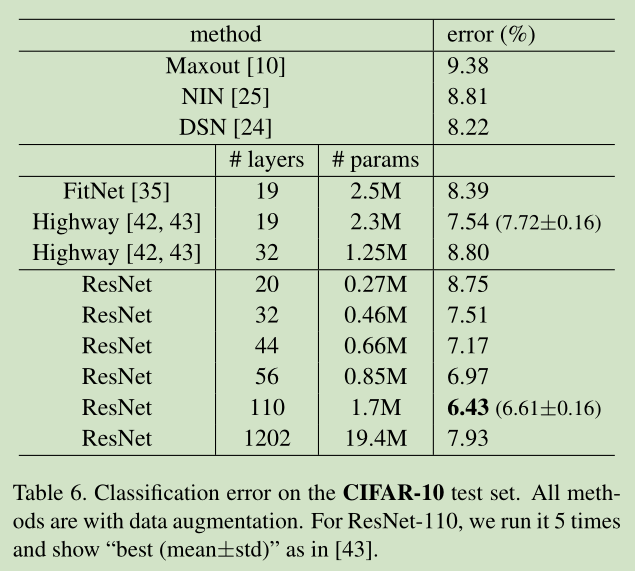
1. 110-layer ResNet on CIFAR-10 ,包含 54个2层的Residual Units(每层为3*3卷积层)。详细实现见 论文appendix
跑了5次,取了准确率的中值。
尽管之前的分析是基于 f 为 Identity 的,但是实验取的 f 为 ReLU as in [1],实验分别证明了 Figure 2中的所有 h(x)的选择都不如 Identity map :h(x)=x
实验详见论文。
补充一份:残差家族的最新论文:http://blog.csdn.net/sunbaigui/article/details/51702563
在2015年残差网络Deep Residual Learning for Image Recognition出来之后,2016年出现了大批量的达到与之相应效果的加深网络的方法。加深网络会带来如下三大类问题:1. 后向传播梯度消失;2. 前向传播信息量减少;3. 训练时间加长。为了缓解以上三大类问题,2016上半年已经有各式各样的加深网络的方法,让我们来看下下面五篇文章,前四篇文章主要注重与如何去使用各种方法加深网络,最后一篇文章对最近出现的残差网络家族做了一个深入的分析与思考,指出残差与其说是加深网络不如说是隐式的多网络叠加。
一、Deep Networks with Stochastic Depth
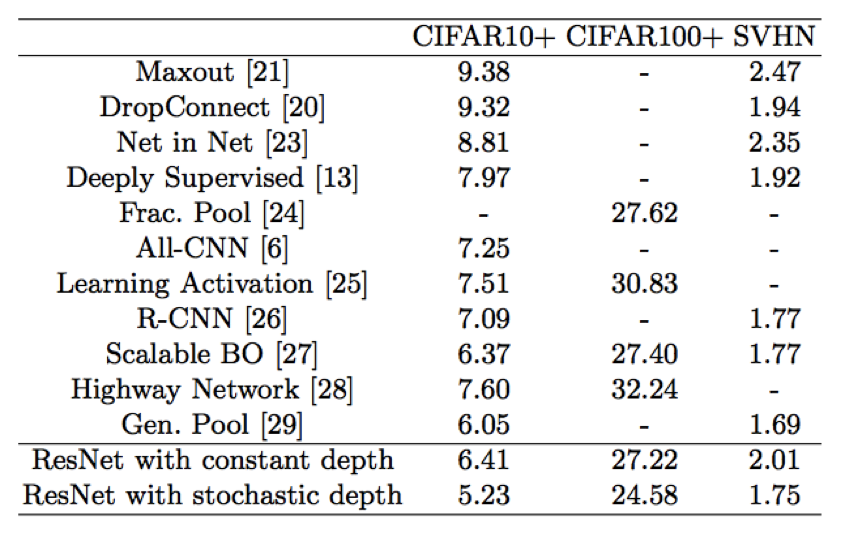
该文章将CIFAR-100刷到了24.58。代码:https://github.com/yueatsprograms/Stochastic_Depth。该文章基于Deep Residual Learning for Image Recognition做了实验,提升效果如下表所示(重点看constant与stochastic的比较):
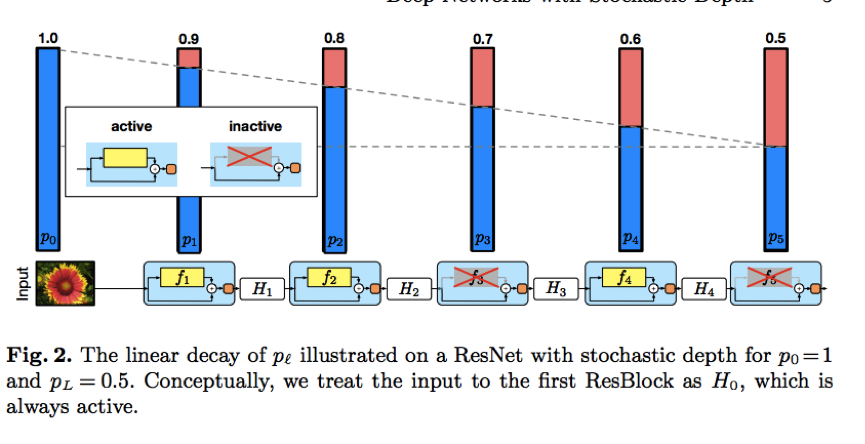
文章提出在层出现概率是线性衰减到0.5的情况下,如下图所示:
则有L个block的network每次训练时有期望3/4L个block参与训练。在预测端也相应的需要做些改变如下:
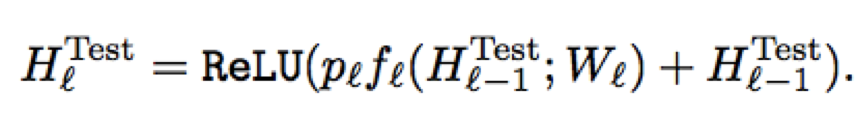
。该加深网络方法的缺点是:虽然减少了训练的时间,但确不能减少前向的时间。不过它是一个非常有效的类似于dropout、drop connection的regularization的方法,能有效采用这样的加深网络的方式来提升模型性能。
二、FractalNet:Ultra-Deep Neural Networks without Residuals
该文章将CIFAR-100刷到了22.85。该文章不同与第一篇drop layer,它提出了分形网络(fractal network)的概念,基于fractal network的基础上,采用drop path来进行训练。其样例结构如下:
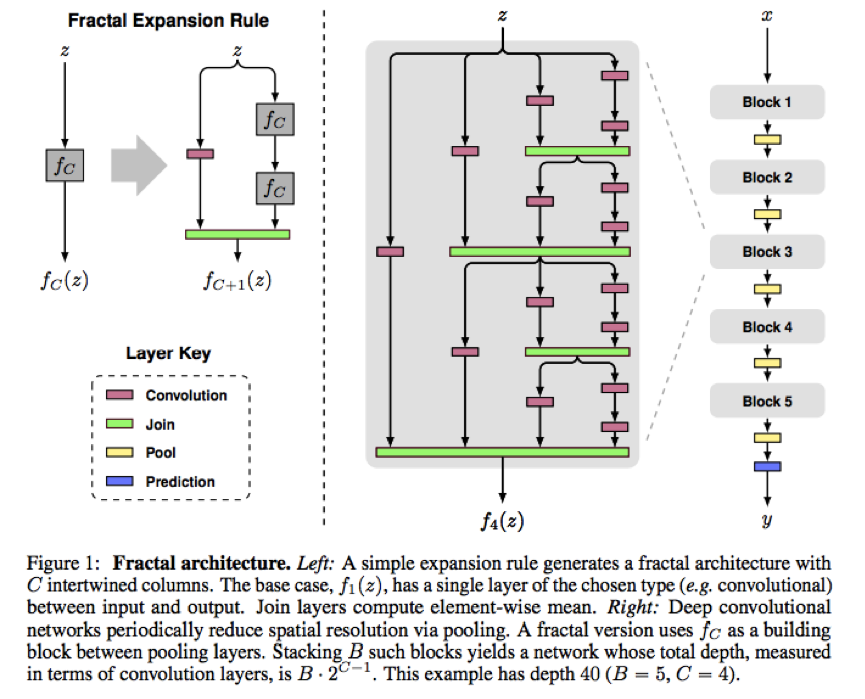
文章提出了的drop path方法如下:
1. local:join模块一定概率drop每个输入,但确保每个join至少一个输入留下。
2. global:对分形网络(fractal network)只留下一列
其示意图如下:
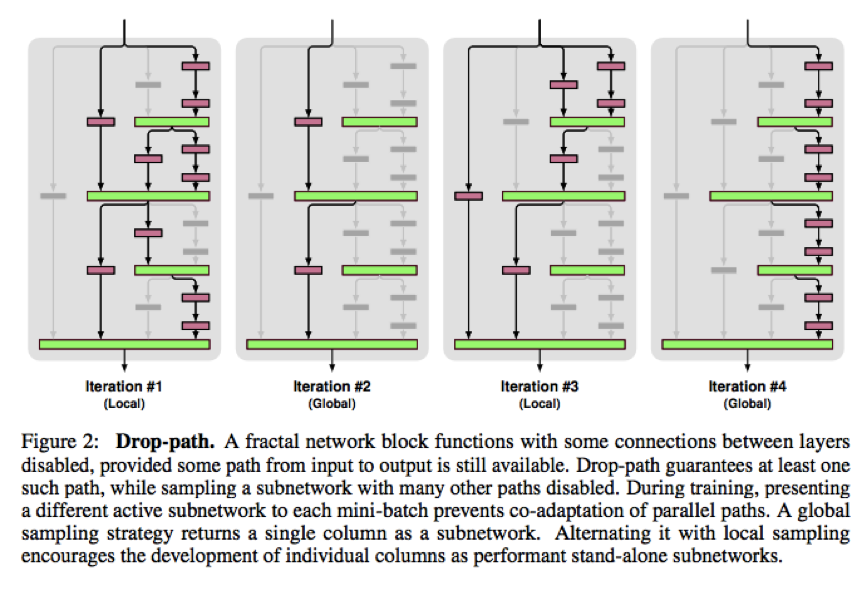
三、Identity Mappings in Deep Residual Networks
该文将CIFAR-100刷到了22.71。代码:https://github.com/KaimingHe/resnet-1k-layers。该文章主要对原文Deep Residual Learning for Image Recognition的残差单元做了两方面做了详尽的实验:1. shortcut类型 2. 激活函数顺序。shortcut类型的实验如下:
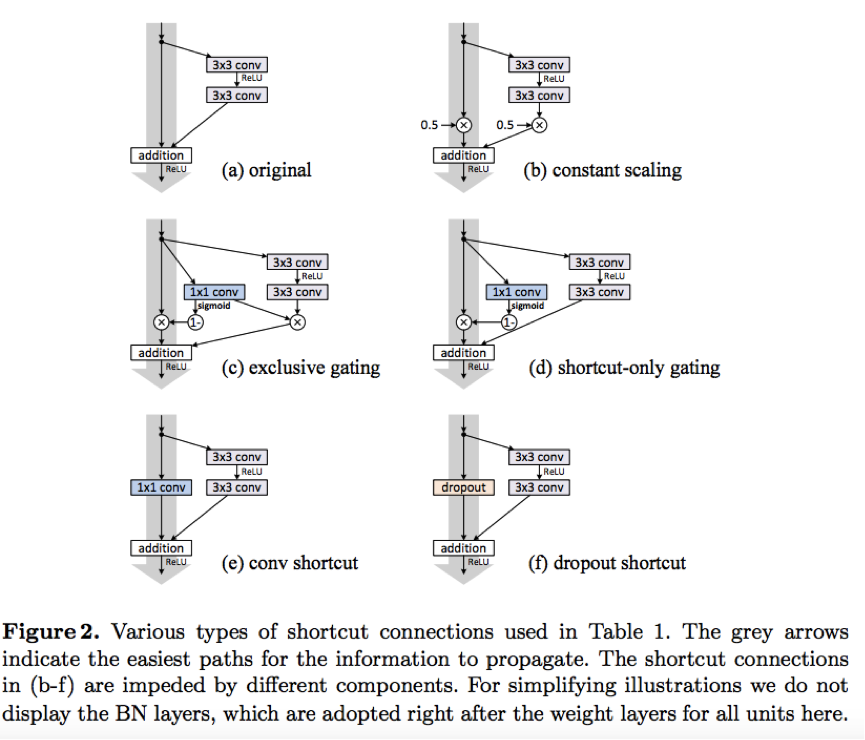
最后证明还是原先的第一种更好。激活函数顺序的实验如下:
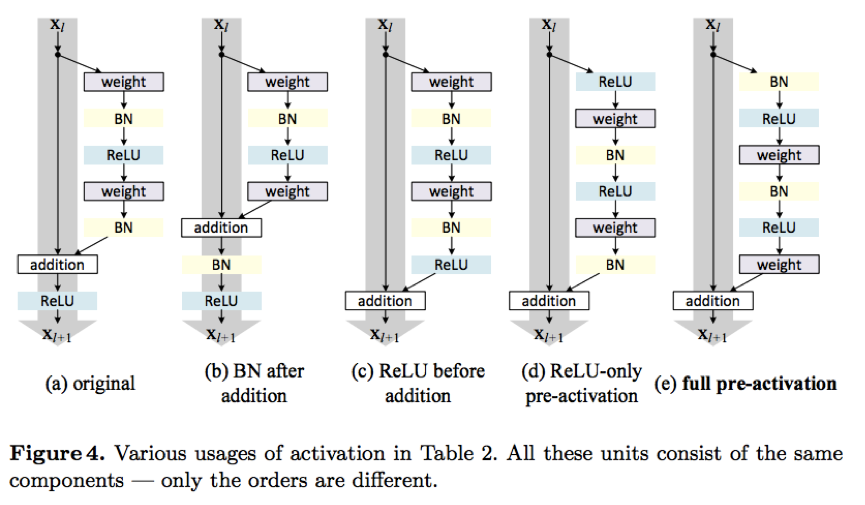
最后证明是最后一种好,将激活函数都放在weight之前。
四、RESNET IN RESNET:GENERALIZING RESIDUAL ARCHITECTURES
该文章将CIFAR-100刷到了22.90。其核心结构如下:
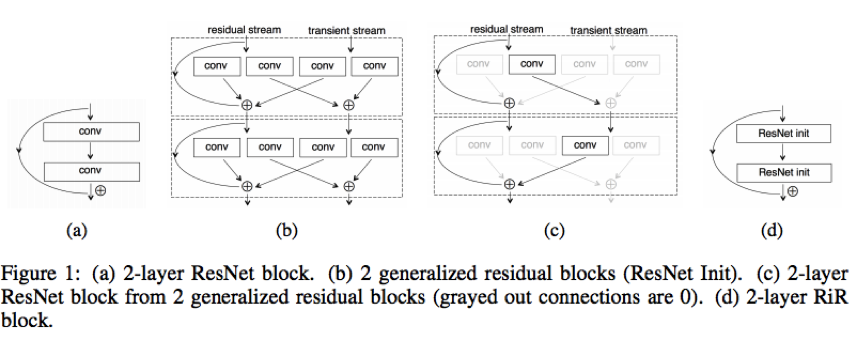
五、Residual Networks are Exponential Ensembles of Relatively Shallow Networks
该文章提出了在残差网络风行的时候,给出了一个创新的观点,并附上了一些理论+实验观测上的证明。具体的观点如下:残差网络并不是一个真正意义上极深的网络,而是隐式地由指数个大部分为浅层网络叠加而成的。由此该论文指出,查看网络之后除了可以看width和depth,其实还有另外一个维度就是multiplicity。该文章中比较关键的一个理论证明插图如下:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









