import requests
from bs4 import BeautifulSoup
import os
url = "https://www.wenjingketang.com/bookHome"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
pic_list = soup.find_all("img", src=lambda x: x and x.endswith(".gif"))
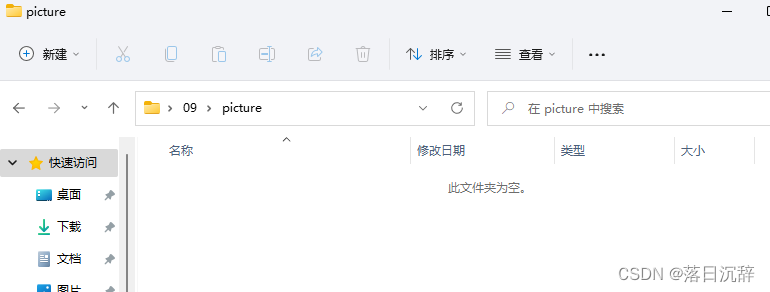
if not os.path.exists("picture"):
os.mkdir("picture")
for pic in pic_list:
pic_url = pic["src"]
pic_name = pic_url.split("/")[-1]
pic_data = requests.get(pic_url).content
with open("picture/" + pic_name, "wb") as f:
f.write(pic_data)
print("图片下载完成")























 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









