






简介
使用泛型算法必须包含头文件 ——–# include< algorithm>
标准库还定义了一组泛化的算术算法,其命名习惯与泛型算法相同。使用这些算法必须包含头文件——–#include< numeric>
==================================================================================
使用泛型算法必须包含头文件 ——–# include< algorithm>
标准库还定义了一组泛化的算术算法,其命名习惯与泛型算法相同。使用这些算法必须包含头文件——–#include< numeric>
除了少数情况例外,所有算法都在一段范围内的元素上操作,我们将这段范围称为“输入范围”标记该范围的两个形参,其中一个指向要处理的第一个元素的迭代器,另一个指向最后一个元素的下一个位置的迭代器。
一、只读算法
1、accumulate函数
许多算法只会读取其输入范围内的元素,而不会写这些元素。find 就是这样一个算法,另一个简单的只读算法是 accumulate,该算法在numeric头文件中定义。
- accumulate 带有三个形参,头两个形参指定要累加的元素范围。第三个形参则是累加的初值。
- accumulate函数将它的一个内部变量设置为指定的初值,然后在此初值上累加输入范围内所有元素的值。
- accumulate算法返回累加的结果,其返回类型就是其第三个实参的类型。
- 用于指定累加起始值的第三个实参是必要的,因为accumulate对将要累加的元素类型一无所知,因此,除此之外,没有别的办法创建合适的起始值或者关联的类型。
- accumulate对累加的元素类型一无所知有两层含义:调用函数时必须传递一个起始值,否则,accumulate将不知道使用什么起始值。
- 其次,容器内的元素类型必须与第三个实参的类型匹配,或者可转换为第三个实参的类型。在accumulate内部,第三个实参用作累加的起点:容器内的元素按顺序连续累加到总和之中。因此,必须能够将元素类型加到总和类型上。
//假设vec是一个int型的vector 对象,下面的代码
int sum =accumulate(vec.begin(),vec.end(),42);
//将sum设置为vec的元素之和再加上42//下面的例子,可以使用accumulate把string类型的vector容器中的元素连接起来
string sum=accumulate(v.begin(),v.end(),string(""));
//从空字符串开始,把vec里的每个元素连接成一个字符串。注意:程序显示地创建了一个string对象,用作该函数调用的第三个实参。传递一个字符串字面值,将会导致编译时错误。因为此时,累加和的类型将是const char*,而string 的加法操作所使用的操作数分别是string 和const char *类型,加法的结果将产生一个string 对象,而不是const char*指针2、find_first_of 的使用
- find_first_of 算法带有两对迭代器参数来标记两段元素范围(四个迭代器),在第一段范围内查找与第二段范围中任意元素匹配的元素,然后返回一个迭代器,指向第一个匹配的元素。如果找不到匹配元素,则返回第一个范围的end迭代器。
//假设 roster1和roster2是两个存放名字的list对象,可使用find_first_of统计有多少个名字同时出现在这两个列表中
size_t cnt=0;
list<string>::iterator it=roster1.begin();
while((it=find_first_of(it,roster1.end(),roster2.begin(),roster2.end()))!=roster1.end()){
++cnt;
++it;
}
cout<<"found"<<cnt
<<"names on both rosters"<<endl;
//find_first_of(it,roster1.end(),roster2.begin(),roster2.end()) find函数是这样的,里面有四个参数,分别是两对迭代器,用来标记两段元素范围。第二段元素范围保持不变,第一段元素范围不断变小。执行结果是返回一个迭代器,指向第一个匹配的元素。
//接下来,将find_first_of()函数的执行结果赋给it,it是指向找到的匹配元素的迭代器
//调用find_first_of查找roster2中的每个元素是否与第一个范围内的元素匹配,也就是在it到roster1.end()范围内查找一个元素。该函数返回此范围内第一个同时存在于第二个范围中的元素。在while 的第一次循环中,遍历整个roster1范围,第二次以及后续的循环迭代器则只考虑roster1中尚未匹配的部分。
//循环条件检查find_first_of的返回值,判断是否找到匹配的名字,如果找到一个匹配,则使计算器加1,同时给it加1,使它指向roster1中的下一个元素。很明显可知,当不再有任何匹配时,find_first_of返回roster1.end(),完成统计迭代器实参类型
通常,泛型算法都是在标记容器(或其他序列)内的元素范围的迭代器上操作的。标记范围的两个实参类型必须精确匹配,而迭代器本身必须标记一个范围:它们必须指向同一个容器中的元素(或者超出容器末端的下一个位置),并且如果两者不相等,则第一个迭代器通过不断的自增,必须可以到达第二个迭代器。
有些算法,例如 find_first_of ,带有两对迭代器参数,每对迭代器中,两个实参的类型必须精确匹配,但不要求两对之间的类型匹配,特别是,元素可存储在不同类型的序列中,只要这两个序列的元素可以比较即可。
上述程序中,roster1和roster2的类型不必精确匹配:roster1可以是list对象,而roster2则可以是vector对象、deque对象或者是其他后面要学到的序列。只要这两个序列的元素可使用相等操作符进行比较即可。
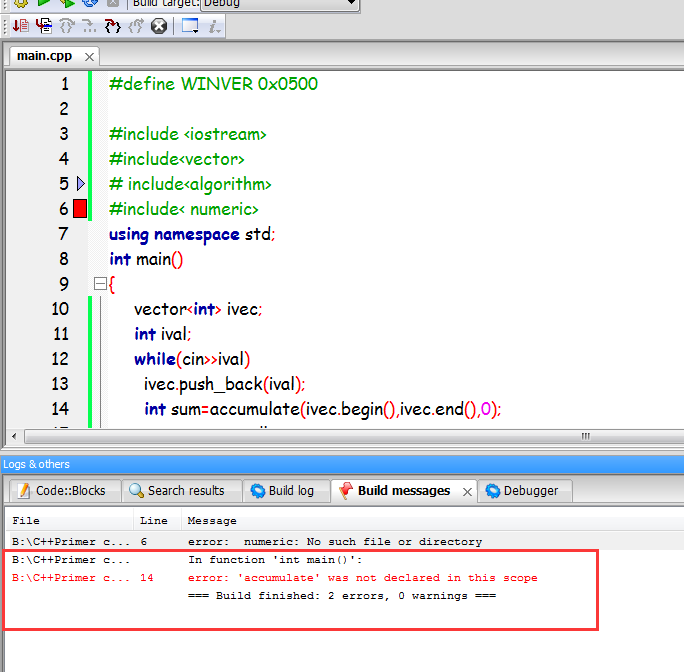
//这个代码总是有错,头文件错,我不知道怎么改
#include <iostream>
#include<vector>
# include<algorithm>
#include< numeric>
using namespace std;
int main()
{
vector<int> ivec;
int ival;
while(cin>>ival)
ivec.push_back(ival);
int sum=accumulate(ivec.begin(),ivec.end(),0);
cout<<sum<<endl;
return 0;
}















 3392
3392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









