







python中使用正则表达式的方法:
1、match(): 默认匹配开头, 满足匹配就返回, 如果要匹配结尾需要手动加上 $ 符号;
2、search(): 不匹配开头,而是从开头往后进行搜索,只要匹配到了(一个)满足条件的数据就返回,之后的就不再管了;
3、findall(): 不匹配开头,而是从开头往后进行搜索, 匹配到所有满足条件的数据,返回一个列表,不能使用group();
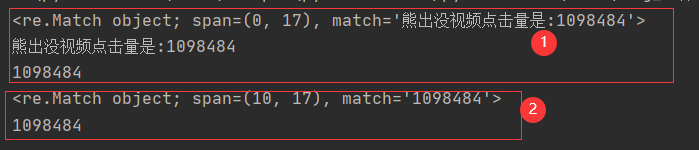
案例1:使用match()或者search(), 数据的提取(1个)熊出没视频点击量:1098484
str_='熊出没视频点击量是:1098484'
result = re.match(r'熊出没视频点击量是:(\d+)$',str_)
print(result)
print(result.group())
print(result.group(1))
# 目标: 不想要从头开始匹配视频点击量:1098484
str_='熊出没视频点击量是:1098484'
result =re.search(r'\d+',str_)
print(result)
print(result.group())
案例2:使用match()或者search(), 数据的提取(多个) 熊出没视频点击量是:1098484,下载量:168,转发量:987
str_='熊出没视频点击量是:1098484,下载量:168,转发量:987'
#注意“,”不能使用中文哦!
result = re.match(r'熊出没视频点击量是:(\d+),下载量:(\d+),转发量:(\d+)$',str_)
print(result.group(1))
print(result.group(2))
print(result.group(3))
#使用search()只能查找到1个,就返回,之后的数据不管。
str_='熊出没视频点击量是:1098484,下载量:168,转发量:987'
result = re.search(r'\d+',str_)
print(result.group())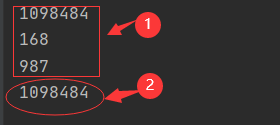
案例3:使用findall()查找所有的数据匹配,返回是列表[],如果没有,则返回空列表[]。
str_='熊出没视频点击量是:1098484,下载量:168,转发量:987'
result = re.findall(r'\d+',str_)
#如果匹配不成功时,那么就返回空列表[]
#result = re.findall(r'[a-z]+',str_)
print(result)![]()
案例4:爬虫提取 : 使用findall 与 分组 进行数据提取
str_='''<div class="font"><p>位置:F-G(23号)</p>
<p>身高:2.06米/6尺9</p><p>体重:113公斤/250磅</p>
<p>生日:1984-12-30</p>
<p>球队:<a target="_blank" title="洛杉矶湖人" style="color:red" href="https://nba.hupu.com/teams/lakers">洛杉矶湖人</a></p>
<p>选秀:2003年第1轮第1顺位</p>
<p>国籍:美国</p>
</div>
'''
result =re.findall(r'<p>(.*?)</p>',str_)
print(result)
说明:
1.把想要提取的部分用括号括起来, .*? 非贪婪 (.*?) > 代表的是想要被提前的数据
2.<p>"(.*?)"</p> 想要提取的部分前面的数据是<p> , 后面的数据是</p>
re正则表达式:
(1) 贪婪: 默认是贪婪的,能取多少就取多少。=>(.*)
(2) 非贪婪: 变成不贪婪的,尽量少取。 =>(.*?)
import re
#只提取第一个a后面的mike,第二个a不需要。
#<img>,<p>,<h1>,<ul>....
str_='<a>mike<a>http'
# .* (1) 正则表达式默认的是贪婪的: 能取多少就取多少
# result = re.match(r'<.*>\w+',str_)
# .*? (2) 非贪婪的: 能少取尽量少取
result = re.match(r'<.*?>\w+',str_)
print(result.group()) ![]()
![]()
r的作用: 原生字符串
#起到转义效果
str_='c:\\pic\\demo\\one'
print(str_)
#r就是原生的效果,不起转义哦!
str_=r'c:\\pic\\demo\\one'
print(str_)
补充:sub()替换 和split()切割的使用
'''
sub(正则表达式,替换值,原字符串) >替换 如:str.replace()
先正则定位,再替换数据哦!
'''
# str_='熊出没视频点击量是:1098484'
# result = re.sub(r'\d+','123569',str_)
# print(result)
'''
split(正则表达式,原字符串) >切割 如:str.split()
'''
# str_='peanut>butter,pervent,tattoo>accident>perspective'
# result=re.split(r',|>',str_)
# print(result)















 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









