







一、哈希表
哈希表(hash table)也叫作散列表,这种数据结构提供了键(Key)和值(Value)的映射关系。只要给出一个Key,就可以高效查找到它所匹配的Value,时间复杂度接近于O (1) 。


我们需要一个“中转站”,通过某种方式,把Key和数组下标进行转换。这个中转站就叫作哈希函数。

在不同的语言中,哈希函数的实现方式是不一样的,在Python语言中,哈希表对应的集合叫作字典 ( dict)。来看看哈希函数是如何实现的。
在Python及大多数面向对象的语言中,每一个对象都有属于自己的hash值,这个hash值是区分不同对象的重要标识。无论对象自身的类型是什么,它们的hash值都是一个整型变量。
既然都是整型变量,想要转化成数组的下标也就不难实现了。最简单的转化方式是什么呢?是按照数组长度进行取模运算。
index=hash (key)% size
通过哈希函数,可以把字符串或其他类型的Key,转化成数组的下标index。
当key=oo1121时,index= hash (oo1121")% size=14200367o3%8=7
size是一个长度为8的数组
二、哈希表读写操作
1、写操作(set)
写操作就是在哈希表中插入新的键值对(也被称为Entry)。 如调用dict[oo2931”]=“王五”,是插入一组Key为o02931、Value为王五的键值对。
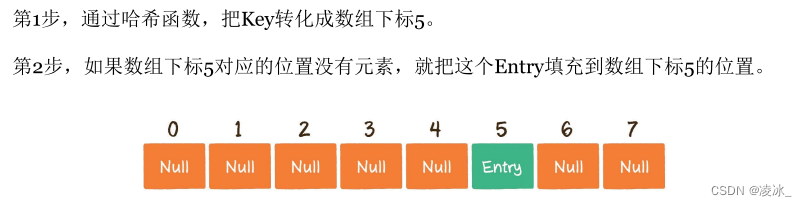
但是,由于数组的长度是有限的,当插入的Entry越来越多时,不同的Key通过哈希函数获得的下标有可能是相同的。
如: 002936这个Key对应的数组下标是2;
002947这个Key对应的数组下标也是2。

这种情况,就叫作哈希冲突。
解决哈希冲突主要有两种
- 开放寻址法
- 链表法
1. 开放寻址法的原理很简单,当一个Key通过哈希函数获得对应的数组下标已被占用时,我们可以“另谋高就”,寻找下一个空当位置。

哈希表数组的每一个元素不仅是一个Entry对象,还是一个链表的头节点。每一个Entry对象通过next指针指向它的下一个Entry节点。当新来的Entry映射到与之冲突的数组位置时,只需要插入对应的链表中即可。
 (2) 读操作(get)
(2) 读操作(get)
通过给定的Key,在哈希表中查找对应的Value。
第1步,通过哈希函数,把Key转化成数组下标2。
第2步,找到数组下标2所对应的元素,如果这个元素的Key是o02936,那么就找到了;如果这个Key不是oo2936也没关系,由于数组的每个元素都与一个链表对应,我们可以顺着链表慢慢往下找,看看能否找到与Key相匹配的节点。

在图中,首先查到的节点Entry6的Key是o02947,和待查找的Keyo02936不符。接着定位到链表的下一个节点Entry1,发现Entry1的Keyoo2936正是我们要寻找的,所以返回Entry1的Value即可。
class HashTable:
def __init__(self, size):
self.size = size #哈希表的大小
self.table = [None]*size #数组
def _hash(self, key):
return hash(key) % self.size #获得数组的下标index
'''设置k-v'''
def set(self, key, value):
hash_index = self._hash(key)
self.table[hash_index] = (key, value)
'''获取数据v'''
def get(self, key):
#获得索引
hash_index = self._hash(key)
#判断数组中是否存在为空
if self.table[hash_index] is not None:
return self.table[hash_index][1]
#发生异常
raise KeyError(f'键Key {key} 不存在!')
if __name__ == '__main__':
#创建对象
table=HashTable(8)
#写入数据
table.set("001121","张三")
table.set("002123","李四")
table.set("002931","王五")
table.set("003278","赵六")
#获取数据
print(table.get("002931"))
# print(table.get("003272"))
哈希表优点
- 在哈希表中,是根据哈希值(即索引)来寻找数据,所以可以快速定位到数据在哈希表中的位置,使得检索、插入和删除操作具有常数时间复杂度 O(1) 的性能
- 与其他数据结构相比,哈希表因其效率而脱颖而出
- 不但如此,哈希表可以存储不同类型的键值对,还可以动态调整自身大小














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









