











后续会讲到L-BFGS在模式分类中的应用。
L_BFGS.m
x = load('ex3x.dat');
y = load('ex3y.dat');
c=0.6; a=1; roi=0.5; m=10;
x = [ones(size(x,1),1) x];
meanx = mean(x);%求均值
sigmax = std(x);%求标准偏差
x(:,2) = (x(:,2)-meanx(2))./sigmax(2);
x(:,3) = (x(:,3)-meanx(3))./sigmax(3);
itera_num = 1000; %尝试的迭代次数
sample_num = size(x,1); %训练样本的次数
theta_old = zeros(size(x,2),1); %theta的初始值赋值为0
Jtheta_new = zeros(itera_num, 1);
Jtheta = zeros(itera_num, 1);
Jtheta1= zeros(itera_num, 1);
q=zeros(3,itera_num);
M=zeros(3,itera_num);
s=zeros(3,itera_num);
r=zeros(3,itera_num);
A=zeros(1,itera_num);
Jtheta(1) = (1/(2*sample_num)).*(x*theta_old-y)'*(x*theta_old-y);
grad_old= (1/sample_num).*x'*(x*theta_old-y);
q(:,1)=grad_old;
B=eye(3);
H=-inv(B);
d1=H*grad_old;
%grad_new = (1/sample_num).*x'*(x*(theta_old+a*d1)-y);
Jtheta_new=(1/(2*sample_num)).*(x*(theta_old+a*d1)-y)'*(x*(theta_old+a*d1)-y);
while 1
if Jtheta_new<=Jtheta(1)+(c*a)*grad_old'*d1
break;
else
a=roi*a;
end
%grad_new = (1/sample_num).*x'*(x*(theta_old+a*d1)-y);
Jtheta_new=(1/(2*sample_num)).*(x*(theta_old+a*d1)-y)'*(x*(theta_old+a*d1)-y);
end
theta_new=theta_old+a*d1;
for i=2:itera_num %计算出某个学习速率alpha下迭代itera_num次数后的参数
a=0.5;
Jtheta(i) = (1/(2*sample_num)).*(x*theta_new-y)'*(x*theta_new-y);
grad_old=(1/sample_num).*x'*(x*theta_old-y);
grad_new = (1/sample_num).*x'*(x*theta_new-y);
M(:,i-1)=grad_new-grad_old;
s(:,i-1)=theta_new-theta_old;
roiJ(i-1)=1/(M(:,i-1)'*s(:,i-1));
gamma=(s(:,i-1)'*M(:,i-1))/(M(:,i-1)'*M(:,i-1));
HK=gamma*eye(3);
if sqrt(abs(grad_new'*grad_new))<0.0001;
N=i;
break;
end
r=lbfgsloop(i,m,HK,s,M,roiJ,grad_new);
d=-r;
Jtheta1(i) = (1/(2*sample_num)).*(x*(theta_new+a*d)-y)'*(x*(theta_new+a*d)-y);%Jtheta是个行向量
while 1
if Jtheta1(i,1)<=Jtheta(i,1)+(c*a)*grad_new'*d;
break;
else
a=roi*a;
end
% grad_new = (1/sample_num).*x'*(x*(theta_old+a*d1)-y);
Jtheta1(i)=(1/(2*sample_num)).*(x*(theta_new+a*d)-y)'*(x*(theta_new+a*d)-y);
end
theta_old=theta_new;
theta_new = theta_new + a*d;
end
K(1)=Jtheta(500) ;
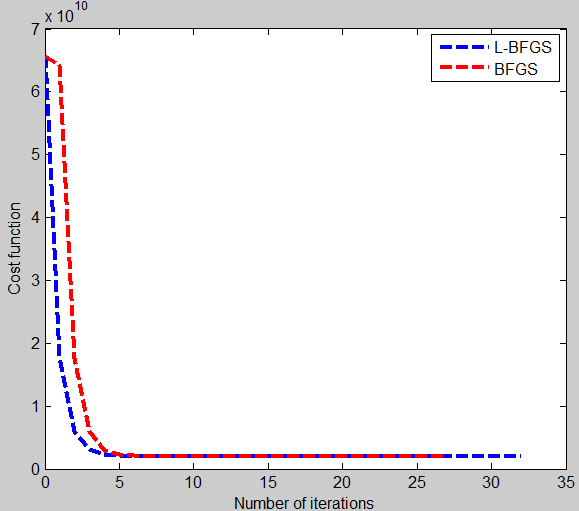
plot(0:N-1, Jtheta(1:N),'b--','LineWidth', 3);
hold on
%%
legend('L-BFGS','BFGS');
xlabel('Number of iterations')
ylabel('Cost function')lbfgsloop.m
function result=lbfgsloop(iteras,length,H_k,STHETA,MGRAD,ROI,grad)
%% 确定搜索方向H_k*f_k
if iteras<=length
deta=0;
else
deta=iteras-length;
end
if iteras<=length
L=iteras;
else
L=length;
end
q=grad;
k=L-1;
%% 向后循环得到A(k)和q
while k>=1
j=k+deta;
A(k)=ROI(j)*STHETA(:,j)'*q;
q=q-A(k)*MGRAD(:,j);
k=k-1;
end
r=H_k*q; %定义初始的方向
%% 前向循环得到r,此时的r为H_k*f_k
for k=1:L-1
j=k+deta;
beta=ROI(j)*MGRAD(:,j)'*r;
r=r+STHETA(:,j)*(A(k)-beta);
end
result=r;














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









