






在信息爆炸的时代,我们每天面对大量的文本信息,无论是工作文档、新闻稿件还是社交媒体内容,都需要进行高效、精准的编辑。而XT文本批量编辑器正是您理想的助手,它支持批量高效编辑,更能在文章结尾添加上您想要的相同结语,让您的文本内容更加完美。
第一步:支持批量导入文本进行编辑,进入首助编辑高手的文本批量操作板块,并点击添加文件,将要编辑的文本进行一一导入。可以多个文本一起导入编辑
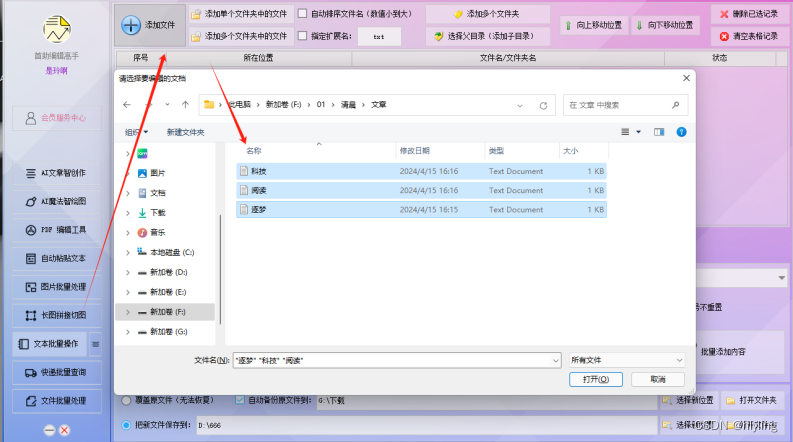
第二步,如何进行添加上相同的结语?导入文本完毕之后,在功能栏里选择添加内容功能

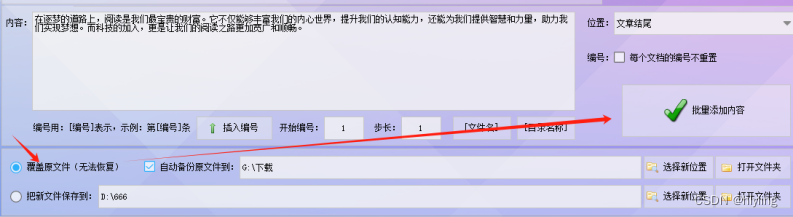
第三步,然后,在添加内容对应的空白框里将要添加的相同文章结语进行输入进去即可

第四步,再去设置添加的位置,下拉旁边的位置列表,选择文章结尾即可

第五步,记得设置好文章的保存位置,小编选择覆盖原文件,并点击批量添加内容
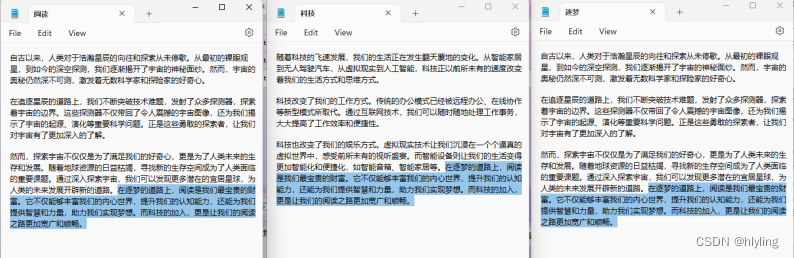
第六步,等提示添加成功之后,我们就可以打开文本进行查看,就能发现每个文章的结尾都添加上了相同的结语。















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









