






Hadoop 常用端口号
- Hadoop 3.X
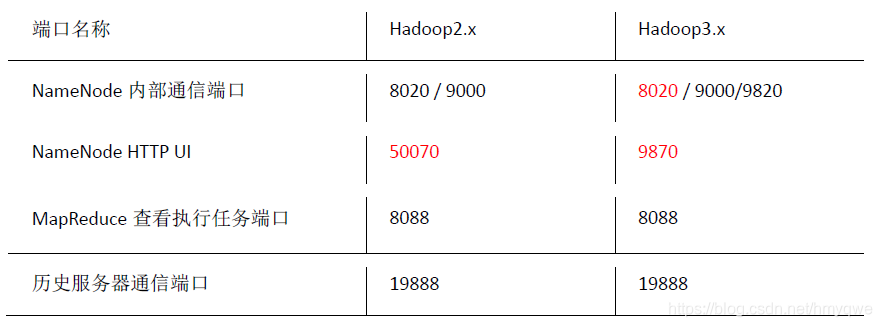
HDFS NameNode 内部通信端口:8020/9000/9820
HDFS NameNode HTTP UI:9870
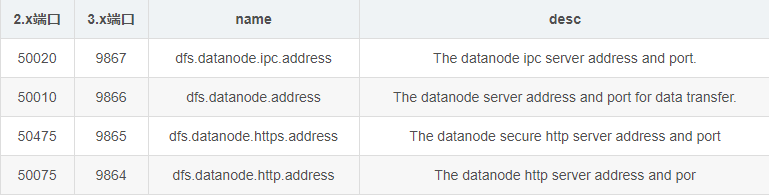
HDFS DataNode HTTP UI:9864
Yarn 查看任务执行端口:8088
历史服务器通信端口:19888 - Hadoop 2.X
HDFS NameNode 内部通信端口:8020/9000
HDFS NameNode HTTP UI:50070
HDFS DataNode HTTP UI:50075
Yarn 查看任务执行端口:8088
历史服务器通信端口:19888



Hadoop 常用配置文件
- Hadoop 3.X
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
workers - Hadoop 2.X
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
slaves

















 3184
3184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









