









 本文介绍了笛卡尔树的起源、构建步骤,强调了其结合二叉查找树和小根堆特性的双重结构。同时,详细解析了构建过程中使用单调栈优化算法的时间复杂度,并提到了快读函数在大数据量场景的应用。
本文介绍了笛卡尔树的起源、构建步骤,强调了其结合二叉查找树和小根堆特性的双重结构。同时,详细解析了构建过程中使用单调栈优化算法的时间复杂度,并提到了快读函数在大数据量场景的应用。
● 笛卡尔树结构由 Vuillmin(1980) 在解决范围搜索的几何数据结构问题时提出。笛卡尔树是一种非常特殊的二叉查找树(BST)。每个结点有两个信息 (pri, val),如果只考虑 pri,它是一棵二叉查找树,如果只考虑 val,它是一个小根堆。其中,pri 是结点插入顺序,或称优先级。val 是结点的值。也就是说,笛卡尔树具有二叉查找树和堆的双重特性。
简言之,一棵笛卡尔树,val 决定了结点的值,pri 决定了结点的位置。
● 如何构建笛卡尔树?(参考于:https://wansuanfa.com/index.php/776)
笛卡尔树的构建步骤如下:(构建前需对 pri 递增排序,或选择数组元素的默认递增下标)
(1)用数组中的第一个元素创建根结点。
(2)遍历数组中剩下的元素,如果新元素比根结点小,让根结点成为新结点的左子结点,然后新结点成为根结点。
(3)如果新结点比根结点大,就从根结点沿着最右边这条路径一种往右走,直到找到比新结点大的结点 node ,也可能没找到。如果找到,就让新结点替换 node 结点的位置,让 node 结点变成新结点的左子结点。如果没找到,就让新结点成为最后查找的那个结点的右子结点。
(4)重复上面步骤(2),(3),直到元素全部遍历完。
● 构建笛卡尔树的关键点解析(参考于:https://wansuanfa.com/index.php/776)
(1)如果新结点比根结点小,根据小根堆(元素的值满足小根堆)的性质,那么新结点一定是根结点的父节点。又因为根结点的下标比新结点小,根据二叉查找树(元素的下标满足二叉查找树)的性质,根结点只能是新结点的左子树。
(2)如果新结点比根结点大,那么新结点只能往右边查找,不能往左边,如果往左边就不满足二叉查找树的性质了。如果比右子结点还大,就继续往右,所以只要比右子结点大就会一直往右。如果比右子结点小,根据小根堆的性质,新结点就会成为这个右子结点的父结点,根据二叉查找树的性质,这个右子结点要成为新结点的左子结点(因为右子结点的下标比新结点小)。
下图为构建笛卡尔树的过程示意图。通过构建过程,易知如何维护笛卡尔树每个结点的两个信息 (pri, val),以及如何保障笛卡尔树具有二叉查找树和堆的双重特性。由图可知,构建方法为以 val 值作为结点,并用其构建小根堆。当需要调整时,以结点插入顺序(或称优先级 pri)为依据,将对应结点置于左子树或右子树,从而保证“如果只考虑 pri,它是一棵二叉查找树”的特性。
简言之,一棵笛卡尔树,val 决定了结点的值,pri 决定了结点的位置。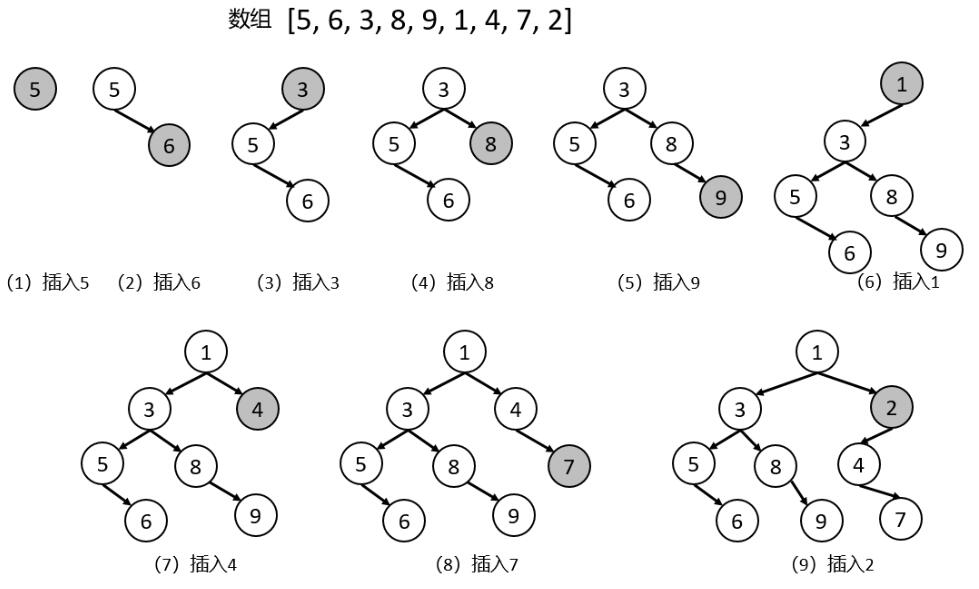
● 单调栈:https://blog.csdn.net/hnjzsyjyj/article/details/117370314
单调栈是一种非常适合处理“下一个更大元素(Next Greater Number)”问题的数据结构。
笛卡尔树的构建过程中,常还需借助“单调栈”这种数据结构,以保证在线性时间内完成笛卡尔树的构建。单调栈中保存的始终是笛卡尔树的右链,即由笛卡尔树的“根结点、根结点的右儿子、根结点的右儿子的右儿子、……”组成的链。并且,为了维护笛卡尔树的小根堆特性,单调栈中的元素值从栈顶到栈底需依次递减,且栈底存储的是根结点。由于每个元素最多进出站各一次,所以时间复杂度为 O(n)。
● 快读:https://blog.csdn.net/hnjzsyjyj/article/details/120131534
在数据量比较大的时候,即使使用 scanf 函数读入数据也会超时,这时就需要使用“快读”函数了。“快读”函数之所以快,是因为其中的 getchar 函数要比 scanf 函数快。 网传,“快读”函数能以比 scanf 函数快5倍的速度读入任意整数。
貌似,笛卡尔树问题常用到快读。
快读代码如下:
int read() { //fast read
int x=0,f=1;
char c=getchar();
while(c<'0' || c>'9') { //!isdigit(c)
if(c=='-') f=-1;
c=getchar();
}
while(c>='0' && c<='9') { //isdigit(c)
x=x*10+c-'0';
c=getchar();
}
return x*f;
}















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









