






正则表达式学习中,一般有两个普遍的问题
第一个,贪婪问题:
var str="kpidfdffhp";
var tmp=/pi/; //不从头开始,只是找字串
//alert(tmp.test(str));
//alert(str.match(tmp));
var ts="sad<hkkk1>wwwww<h1ppp/>ppp>";
var pp=/<.*>/; // * 贪婪 尽可能匹配更多的字符
alert(ts.match(pp)); // . 匹配除/n之外的任意字符
pp=/<.*?>/; //非贪婪 最小匹配
alert(ts.match(pp));
//对子匹配的引用 \x x表示对之前的第x个子匹配已匹配的字符串的再次复制引用
var hp="ppp is IS pp sod of of of sdsp";
var op=/\b([a-z]+) \1\b/ig;
alert(hp.match(op));贪婪问题可以理解为 取{0,1,2,3,4,5}中能取到的最大值,如上所示,sad<h1>wwwww<h1/>ppp> 其中>存在三个,那么按照 /<.*>/ 会取到能取到的最大位置处,即最后一个>,那么此时 * 代表了{0,1,}中能取到的最大值 16,但是若按照 /<.*?>/ 会取第一个,那么 *代表了能取到的最小值,即 2 ,就是非贪婪.
第二个,正反向问题:
var s4="window2020-sdsdp023",s5="window3.1";
var pt=/window(?=2018|2019|2020)2020/; //?= 正向 肯定 预查 ,预查匹配后面的字符成功后,实际上既不匹配也不获取,只是检测
document.write("<br/>"+s4.match(pt)+" "+s5.match(pt));
pt=/window(?!2018|2019|2020)3.1/; //?= 正向 否定 预查 ,预查匹配 非 后面的字符成功后,实际上既不匹配也不获取,只是检测
document.write("<br/>"+s4.match(pt)+" "+s5.match(pt));
s4="2019window",s5="window3.1";
pt=/2019(?<=2018|2019|2020)window/; //?= 反向 肯定 预查 ,预查匹配后面的字符成功后,实际上既不匹配也不获取,只是检测
document.write("<br/>"+s4.match(pt)+" "+s5.match(pt));字符串为s="abcdefgh";
patt="..(?=cde)..." 这是正向肯定预查, 参考下图
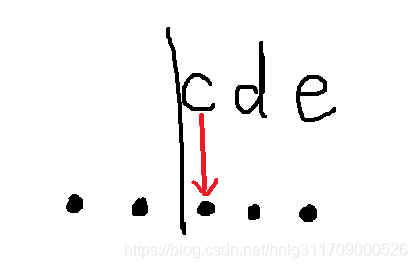
可以理解为 后面三个 ... 真正开始匹配的起始位置为子匹配最左面字符,前面的两个 .. 的结束位置必须在 最左面字符的前面。
patt1="...(?<=cde).." 这是反向肯定预查,参考下图
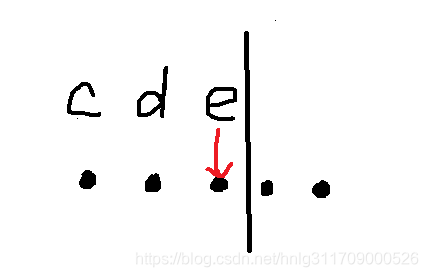
可以理解为 后面两个 .. 真正开始匹配的起始位置为子匹配最右面字符的右面,前面的三个 ... 的结束位置必须是最左面字符。














 941
941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









