







首先,要明白一点,高偏差High bias就是欠拟合underfit,高方差High variance就是过拟合overfit,如下图所示:
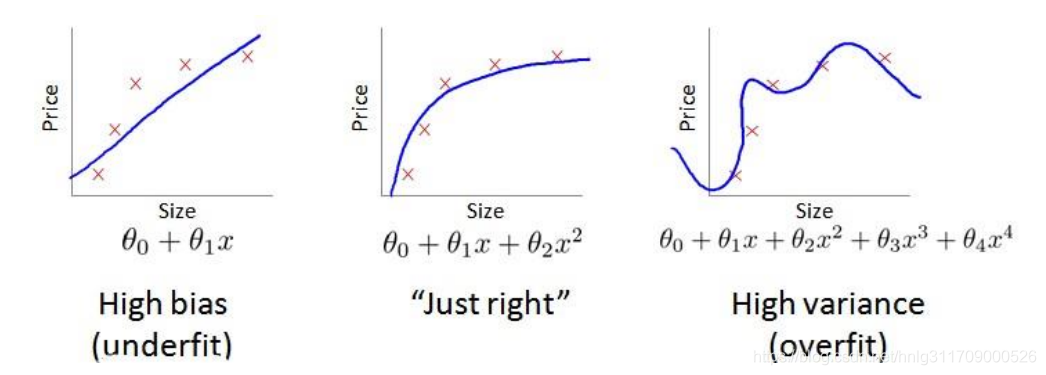
从图示,我们当然可以明显看出区别,区分出哪一个是高偏差 ,哪一个是高方差。但是,这只是肉眼所观察到的,对于计算机而言,需要一个标准,来进行区分,看图是看出不来的。这就用到了训练集和验证集。
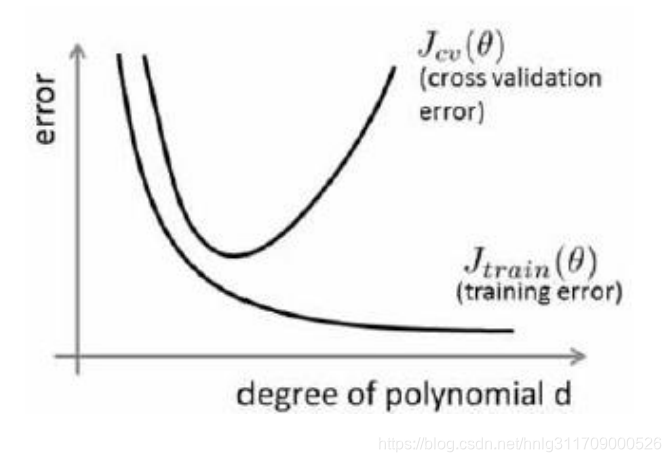
从图中可以看到,随着函数的最高次越来越大,训练集拟合效果越来越好,训练误差越来越低,而得到的模型应用到验证集,其验证误差先有大变小,再由小变大,其原因就是,一开始次数小,拟合效果差,也就是欠拟合,使得验证误差很大,随着次数增加,拟合效果变好,验证误差随之降低,但是,当次数太大时,会出现过拟合的情况,在用训练集训练模型时,得到的训练误差当然很低,因为可以说经过了每一个样本点,但是用验证集时误差就会很高,因为不能再保证经过新的样本点了。
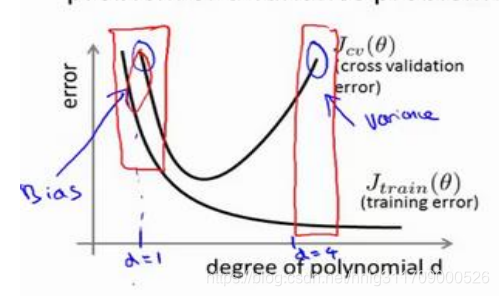
从这幅图,也就区分了高偏差和高分差。如下图所示:

















 2165
2165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









