






以下是 Hadoop 伪分布式模式(Pseudo-Distributed Mode)的环境搭建步骤。伪分布式模式下,Hadoop 的各个组件(如 HDFS、YARN、MapReduce)以独立进程运行,但所有服务均部署在单台机器上,模拟多节点集群的行为。这是学习和开发中最常用的模式。
环境准备
操作系统:Linux(如 Ubuntu/CentOS)或 macOS(Windows 需通过 WSL 或虚拟机)。
前置条件:
(1)完成 Hadoop 单机模式 的安装(JDK 和 Hadoop 解压配置)。
单机模式可以参考本人博客:
Hadoop 单机模式(Standalone Mode)部署与 WordCount 测试-CSDN博客
(2) 配置 SSH 免密登录(用于启动 Hadoop 服务)。
配置 SSH 免密登录:
Hadoop 需要通过 SSH 启动本地进程
# 生成 SSH 密钥(如果已有密钥可跳过)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 将公钥添加到授权列表
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 测试免密登录本机
ssh localhost
# 输入 exit 退出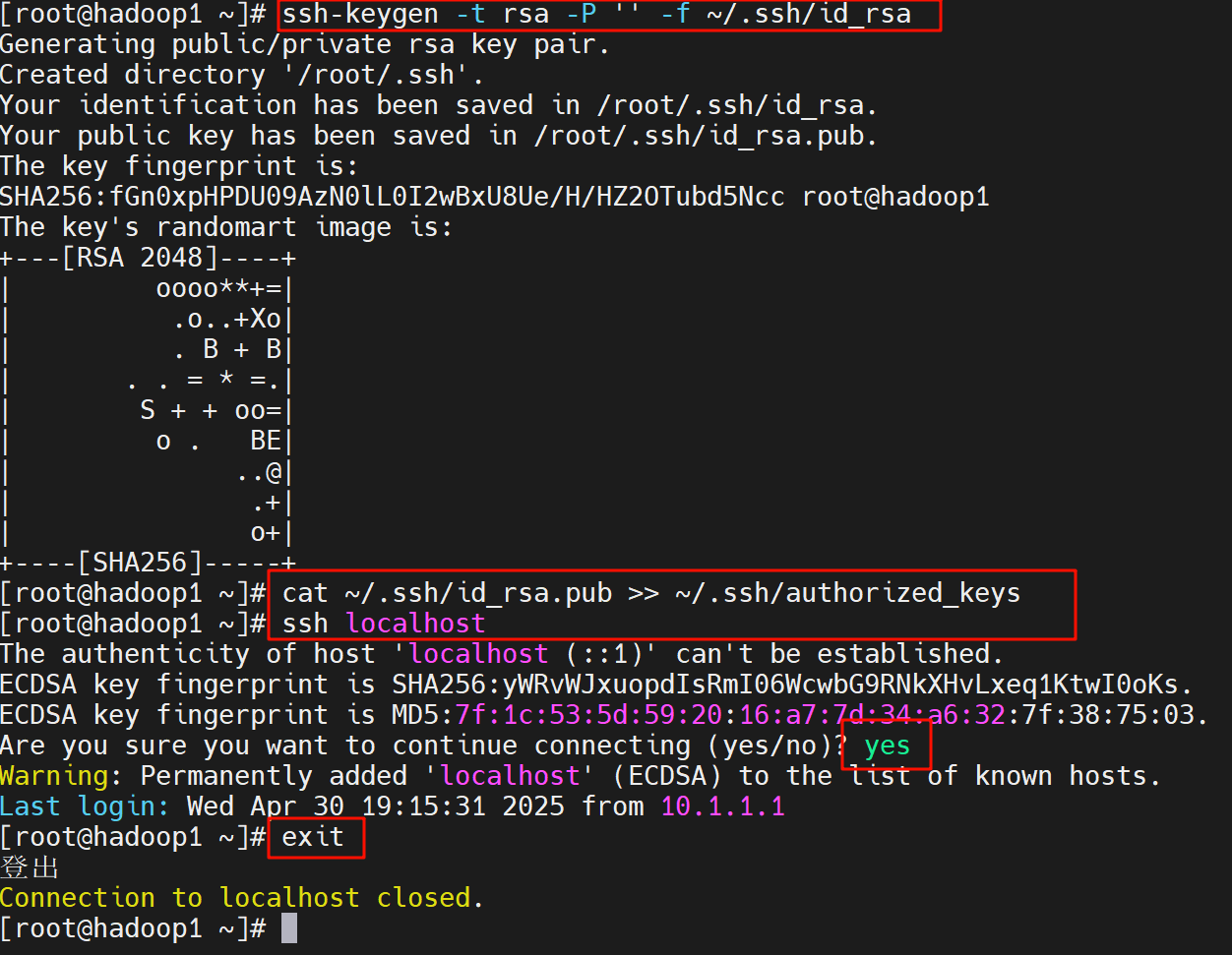
1.修改 Hadoop 配置文件
注意:
接下来配置四个文件,格式严谨,一定不能配置错,否则初始化会出问题,第一次启动hadoop需要初始化,只有一次机会,出现下图即是成功

(1)进入配置目录
cd /opt/hadoop/etc/hadoop(2)编辑 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-tmp</value>
</property>
</configuration>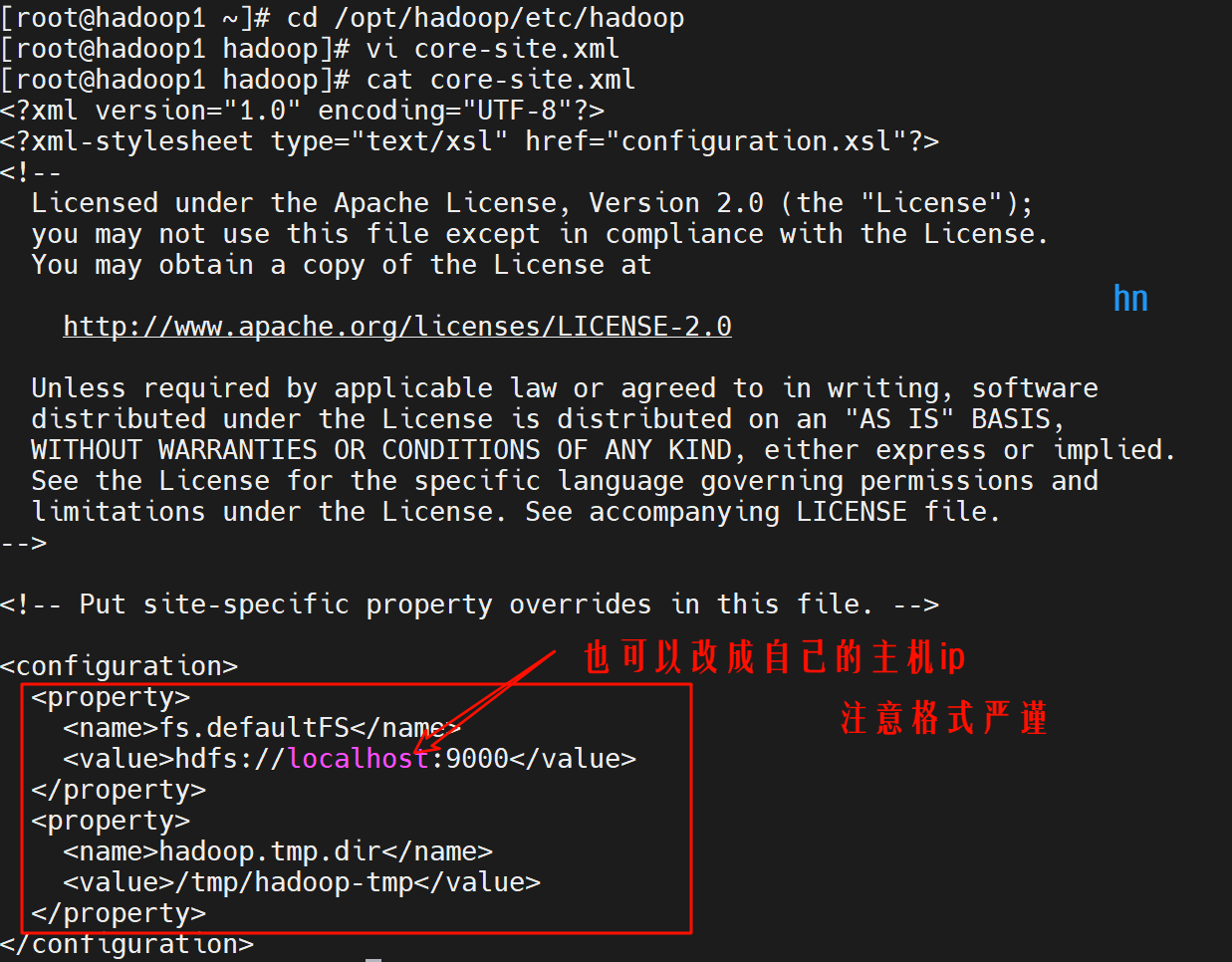
(3)编辑 hdfs-site.xml
配置 HDFS 副本数(伪分布式设为 1):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 启用 Web 访问接口 -->
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:9870</value>
</property>
</configuration>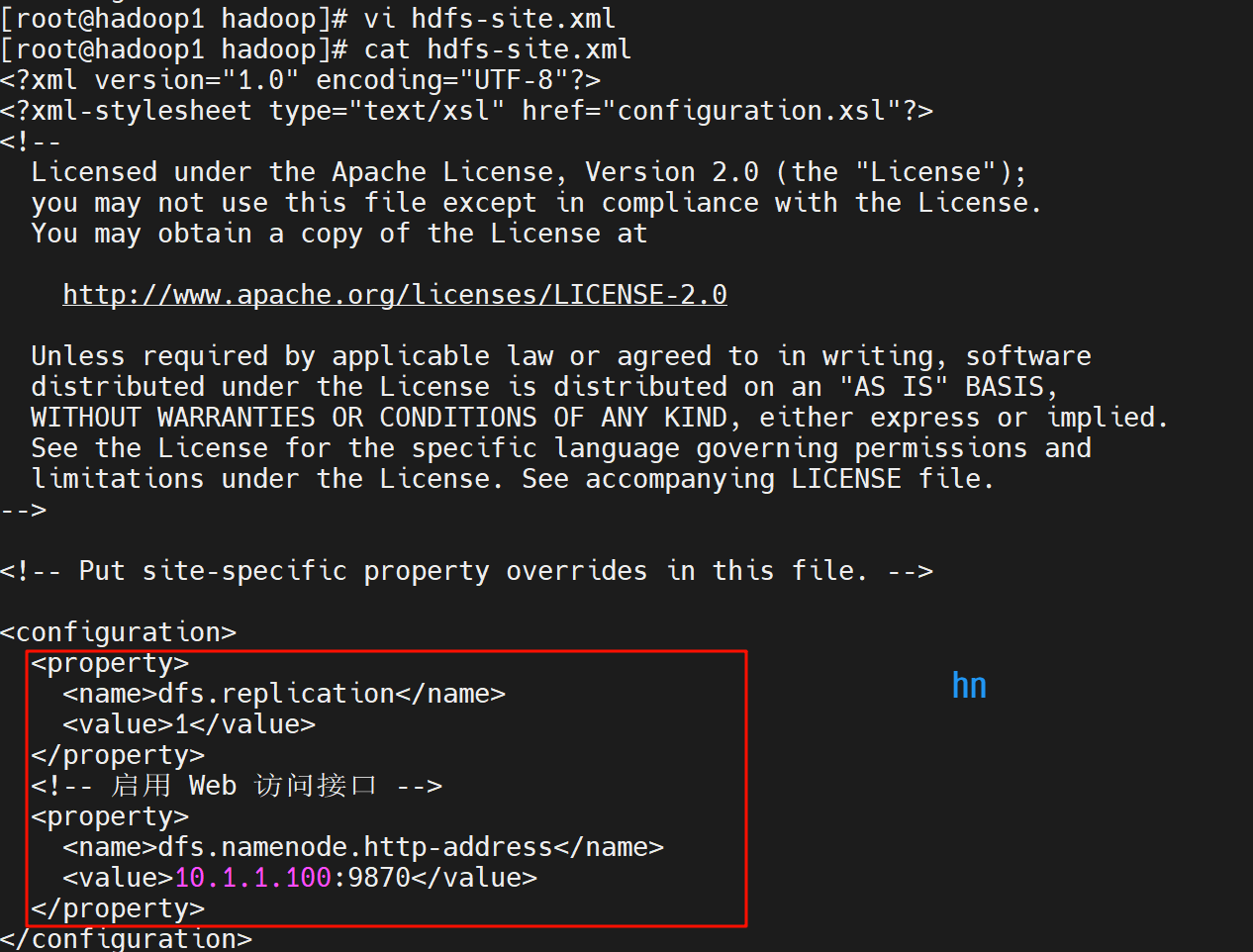
(4)编辑 mapred-site.xml
指定 MapReduce 使用 YARN 框架
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>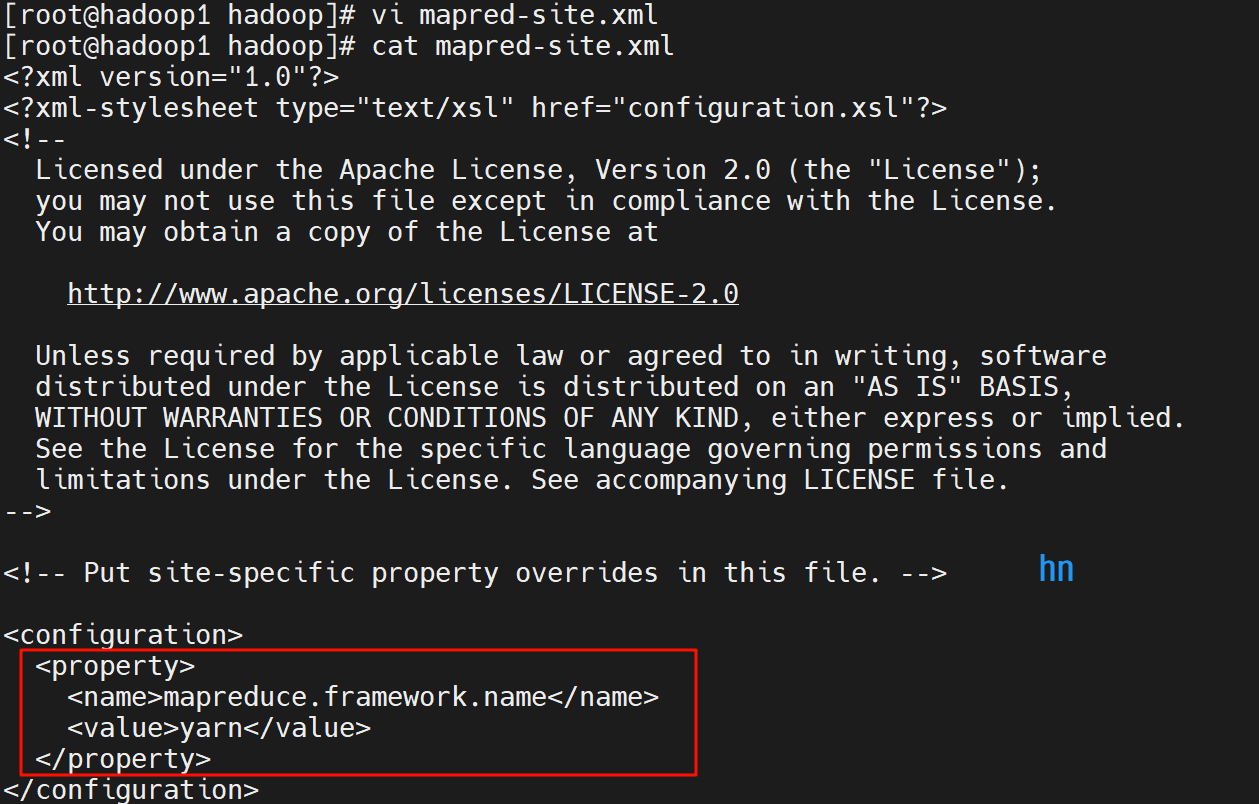
(5)编辑 yarn-site.xml
配置 YARN 资源管理:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>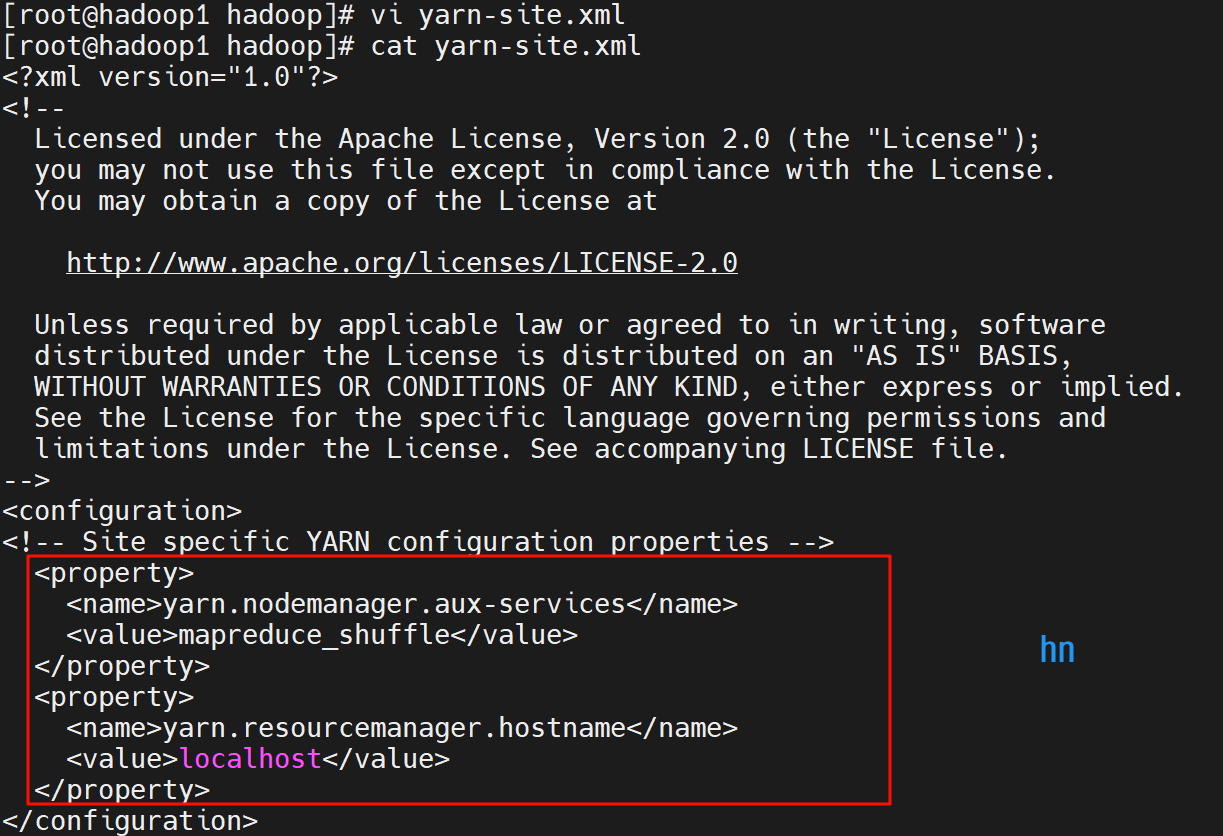
2.初始化 HDFS(*)
首次启动前需格式化 NameNode:
hdfs namenode -format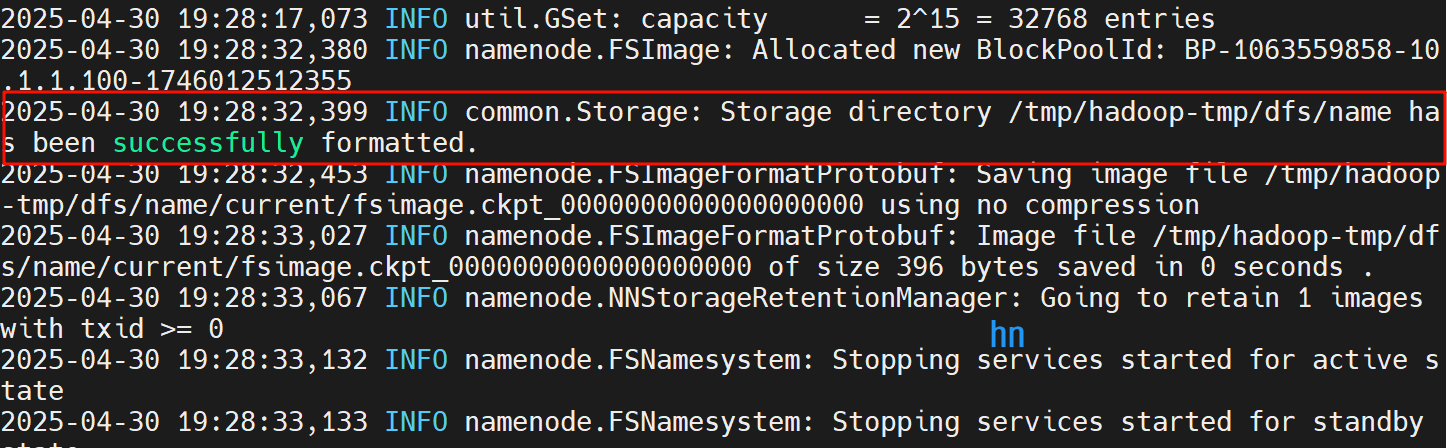
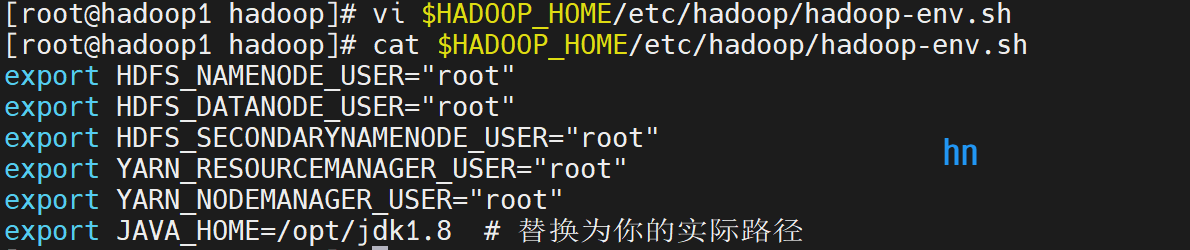
3.编辑 Hadoop 环境配置文件
里面原本的内容全部删掉,修改成下面这个
vi $HADOOP_HOME/etc/hadoop/hadoop-env.shexport HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
export JAVA_HOME=/opt/jdk1.8 # 替换为你的实际路径
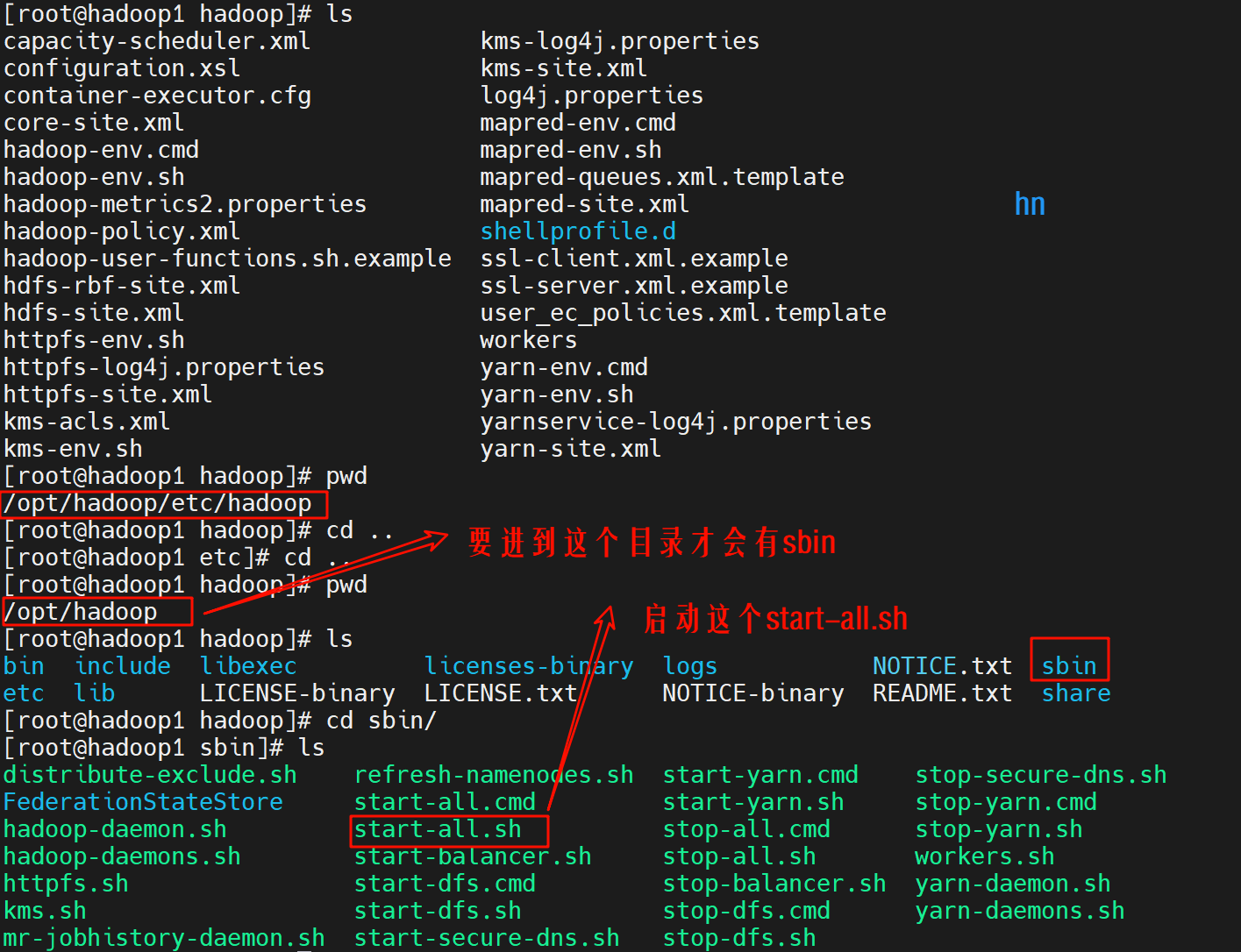
4.启动或停止服务的相关命令
# 启动 hdfs服务
$HADOOP_HOME/sbin/start-dfs.sh
# yarn启动
$HADOOP_HOME/sbin/start-yarn.sh
# 启动所有服务
$HADOOP_HOME/sbin/start-all.sh
# 停止所有服务
$HADOOP_HOME/sbin/stop-all.sh
# 停止 YARN
$HADOOP_HOME/sbin/stop-yarn.sh
# 停止 HDFS
$HADOOP_HOME/sbin/stop-dfs.sh
# 验证进程是否终止
jps
# 应仅剩余 Jps 进程(或无 Hadoop 相关进程)停止启动命令存放位置
补充:linux里是sh,windows里是cmd
5.启动并查看
根据上一步进入到sbin中,启动所有服务:
./start-all.sh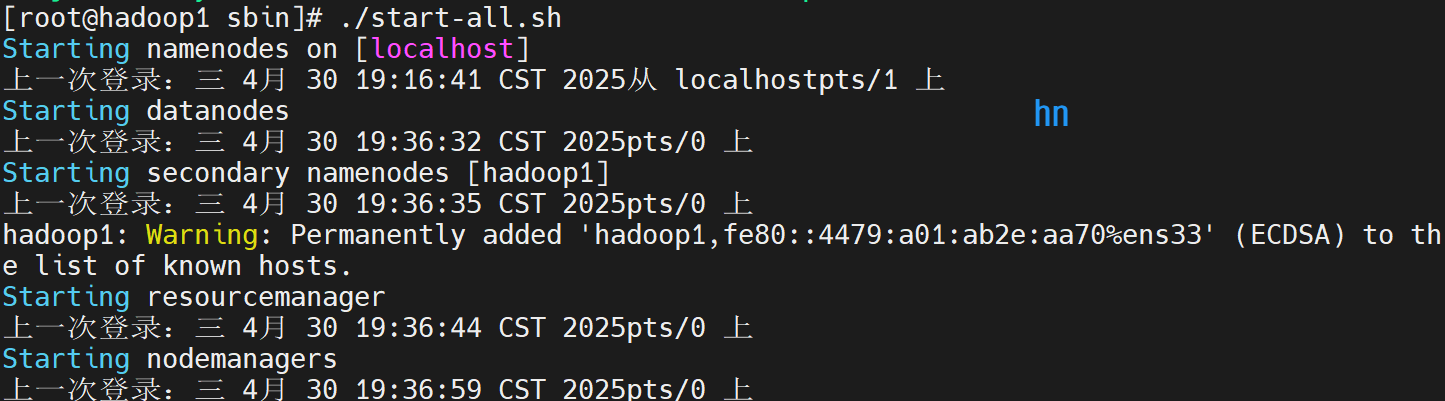
查看:输入jps
(jps就是java里面的进程)

6.网页验证
https://10.1.1.100:9870
hdfs安装成功就可以进入下面页面(因为前面的一个配置文件hdfs-site.xml)
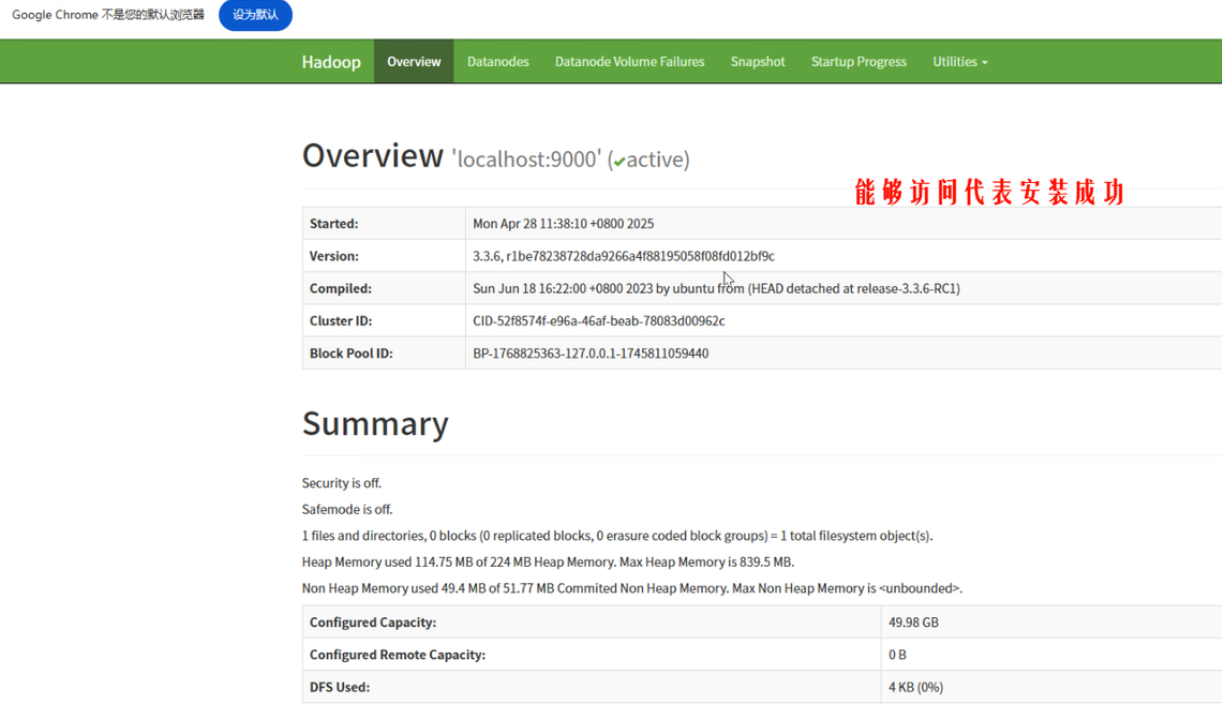
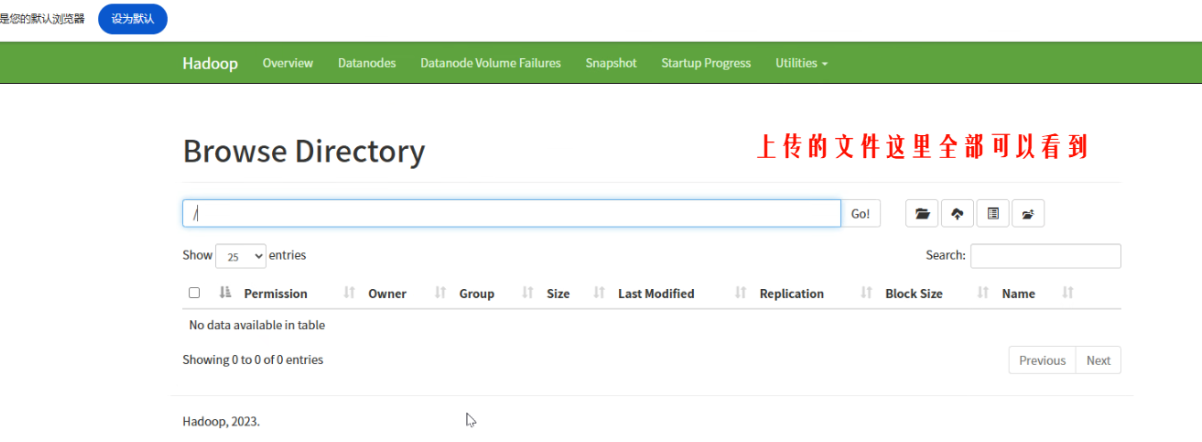
目前为止,hadoop的伪分布式环境部署完成

问题与解决
-
问题 1:首次格式化后启动失败,日志报错
Cannot lock storage directory。
原因:重复格式化导致存储目录冲突。
解决:删除/tmp/hadoop-tmp目录后重新格式化。 -
问题 2:Web UI 端口无法访问。
原因:防火墙未关闭或 SELinux 限制。
解决:执行systemctl stop firewalld和setenforce 0临时禁用安全策略。 -
问题 3:
jps缺少某些进程(如 SecondaryNameNode)。
原因:未正确配置hdfs-site.xml中的辅助节点地址。
解决:添加<dfs.namenode.secondary.http-address>配置并重启服务。
实验结论
-
成功部署:Hadoop 伪分布式环境所有服务(HDFS、YARN、MapReduce)均正常运行,验证了分布式存储和计算的基本功能。
-
配置文件关键性:核心配置文件(如
hdfs-site.xml)的格式和参数必须严格匹配,否则会导致服务启动失败。 -
网络与权限:SSH 免密登录和防火墙/SELinux 设置是服务正常访问的前提条件。
-
适用场景:伪分布式模式适合开发测试,但需注意单点故障风险(如所有进程运行在同一台机器)。

















 119
119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









