






一、配置环境
1.网络配置
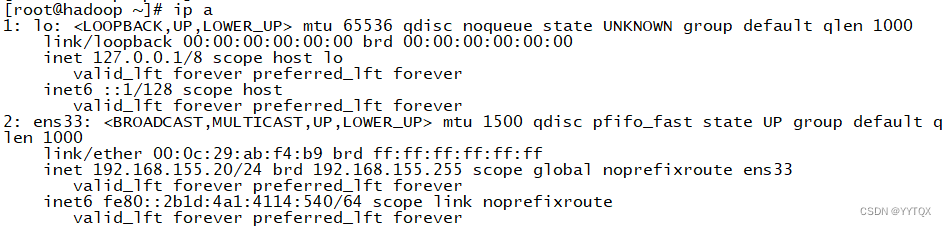
2.网络映射

二、安装jdk
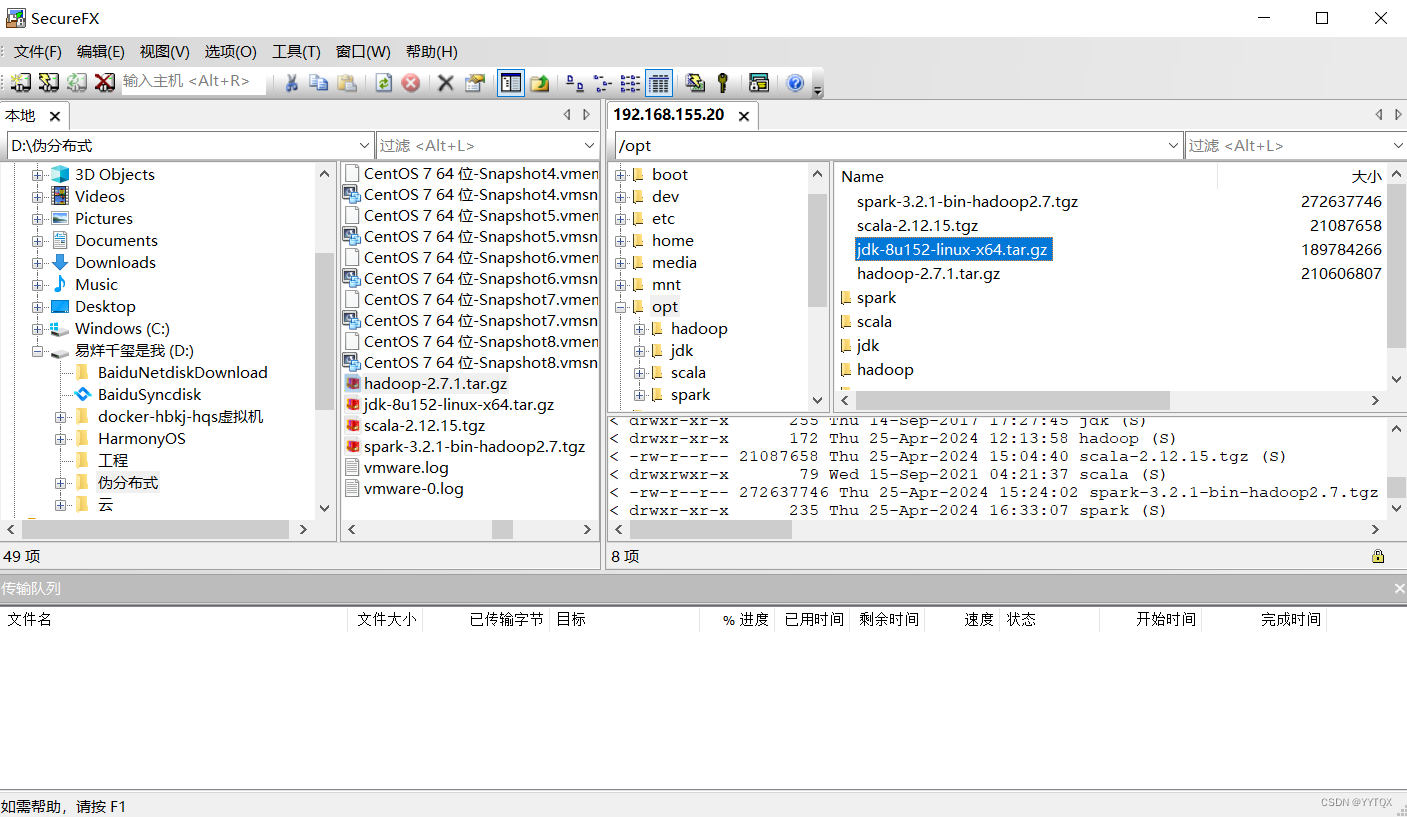
1.上传jdk压缩包
使用SecureFX文件传输工具上传JDK,上传jdk-8u361-linux-x64.tar.gz到/opt目录下
2.查看其他Java版本
查看Linux是否安装java jdk,如果查询有其他java版本,则需要卸载
![]()
如果有就用:
rpm -e --nodeps 版本名卸载
3.解压jdk
![]()
4.重命名为jdk(方便配置环境变量)

5.配置环境变量
在这个文件最后换行添加如下三行:vi /etc/profile
# JDK
export JAVA_HOME=/opt/jdk
export PATH=$JAVA_HOME/bin:$PATH
![]()
6.使这个配置文件生效,查看java的版本
source /etc/profile
java -version

三、安装hadoop
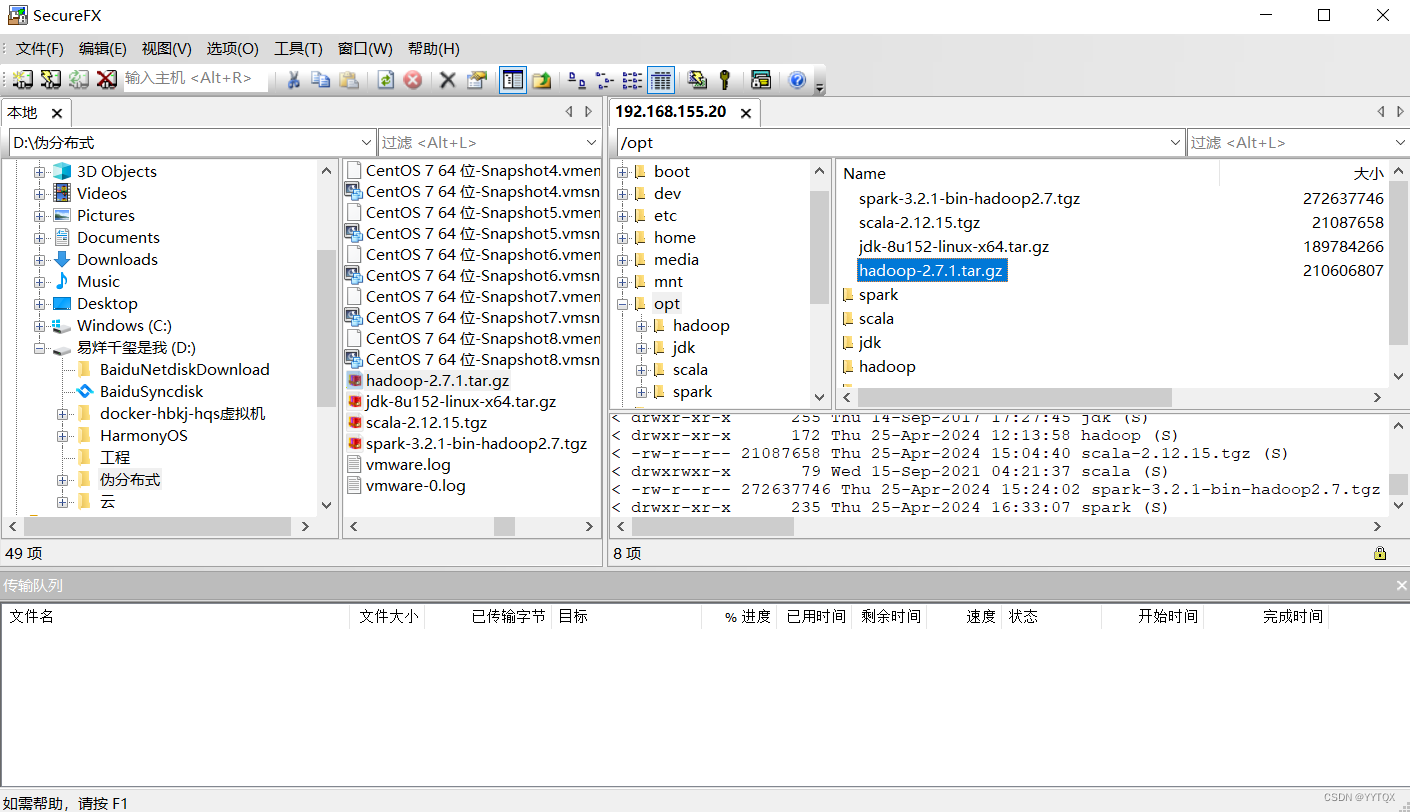
1.上传Hadoop压缩包
使用xshell文件传输工具上传hadoop上传hadoop-2.7.1.tar到/opt目录下
2.解压hadoop
![]()
3.重命名为hadoop(方便配置环境变量)
![]()
4.配置环境变量
在这个文件最后换行添加如下三行:vi /etc/profile
#HADOOP
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

5.使这个配置文件生效,查看hadoop的版本
source /etc/profile
hadoop version

四、Hadoop集群伪分布模式
一、配置免密登录(启动yarn服务需要输入系统密码(节省时间))
1.查看是否安装ssh
进行免密登录需要安装ssh
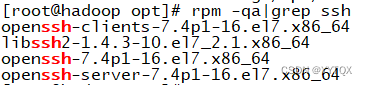
如果有openssh-clients、openssh-server,则不需要安装
如果没有,则需要安装,安装命令如下:yum install -y openssh-clients openssh-server
2.启动ssh服务
![]()
3.本机生成公钥、私钥和验证文件
回车三次即可

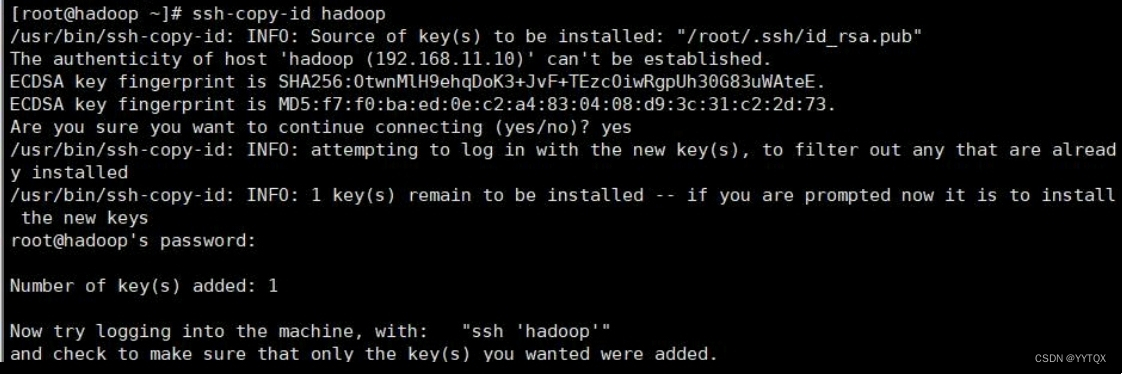
4.将登录信息复制到验证文件
注意:输入该指令后需要自行输入登录密码
这样就配置好免密登录了可以尝试ssh登录命令查看是否配置成功:
二、HDFS的配置
(1)进入Hadoop配置目录:

(2)配置hadoop-env.sh
![]()
在这个配置文件最后换行添加
export JAVA_HOME=/opt/jdk
(3)配置core-site.xml
![]()
将这个配置文件最后的标签内容修改为
<configuration>
<!--配置hdfs文件系统的命名空间-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 配置临时数据存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp/</value>
</property>
</configuration>

(4)配置hdfs-site.xml
![]()
<configuration>
<!--指定HDFS副本的数量-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--设置默认端口,如果不加上会导致启动hadoop-3.1.0后无法访问50070端口查看HDFS管理界面,hadoop-2.7.7可以不加-->
<property>
<name>dfs.http.address</name>
<value>hadoop:50070</value>
</property>
</configuration>

(5)格式化HDFS
配置好HDFS文件系统后首次启动需要进行格式化
注意:不可随意格式化namenode,格式化会删除namenode image和edits文件
再创建新的 image 和 edits,数据将会丢失,需要谨慎使用!!
![]()
格式化成功

格式化成功后,会在hadoop.tmp.dir配置的/opt/hadoop/tmp目录生成目录dfs/name/current/,里面包含几个文件如下:
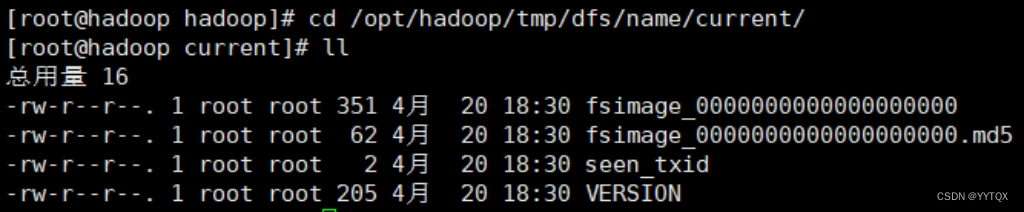
①fsimage_*:
元数据永久性检查点,包含hadoop文件系统中的所有目录和文件inode的序列化信息。②fsimage_*.md5文件:
md5校验文件,用于确保fsimage文件的正确性,可以作用于磁盘异常导致文件损坏的情况。③seen_txid文件
这个文件中保存了一个事务id④VERSION文件
VERSION是java属性文件
三、YARN的配置
1.进入Hadoop配置目录:

2.配置yarn-site.xml
<configuration>
<!--RM的hostname-->
<property>
<name>yarn.resourcemanager.hostsname</name>
<value>hadoop</value>
</property>
<!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>

3.配置mapred-site.xml.template
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

五、启动服务用户定义
1.用户定义
![]()
# HADOOP_USER
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

2.启动hdfs或yarn服务
启动hdfs服务:start-dfs.sh
![]()
三大服务节点:
NameNode:
NameNode 是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。Secondary NameNode:
Secondary NameNode 并不是 NameNode 的热备机,而是定期从 NameNode 拉取 fsimage和editlog文件,并对两个文件进行合并,形成新的 fsimage 文件并传回 NameNode,这样做的目的是减轻 NameNode 的工作压力,本质上 SNN 是一个提供检查点功能服务的服务点。DataNode:
DataNode 负责数据块的实际存储和读写工作,Block 默认是128MB,当客户端上传一个大文件时,HDFS 会自动将其切割成固定大小的 Block,为了保证数据可用性,每个 Block 会以多备份的形式存储,默认是3份。
启动yarn服务start-yarn.sh
![]()
ResourceManager:
ResourceManager 通常在独立的机器上以后台进程的形式运行,它是整个集群资源的主要协调者和管理者。NodeManager
NodeManager 是 YARN 集群中的每个具体节点的管理者。主要负责该节点内所有容器的生命周期的管理,监视资源和跟踪节点健康。
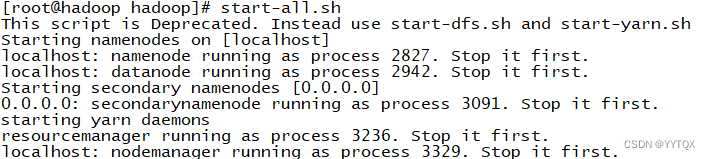
3.同时启动或停止所有服务
启动服务statr-all.sh
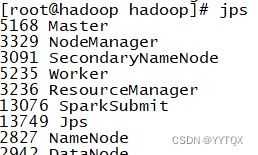
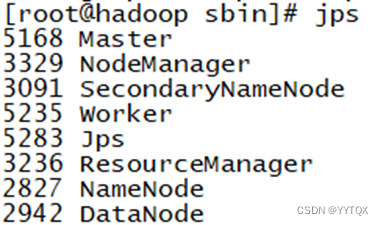
查看结果:jps
停止服务stop-all.sh
六、安装Scala
1.上传Scala安装包
将scala安装包上传到linux虚拟机的/opt目录下
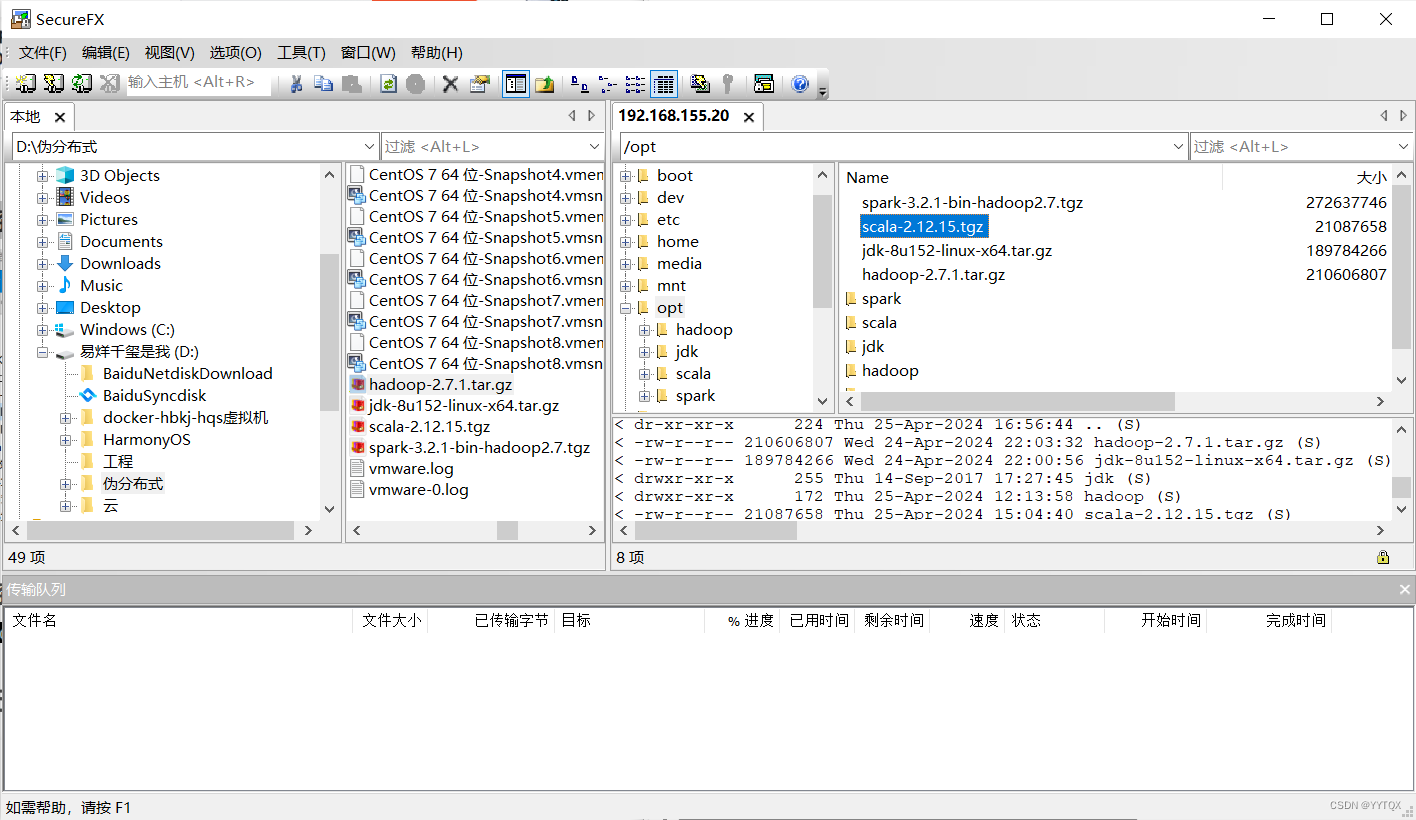
2.将spark安装包解压
![]()
3.配置环境变量
使profile文件更新生效

4.验证

七、安装Spark
1.上传并解压spark安装包
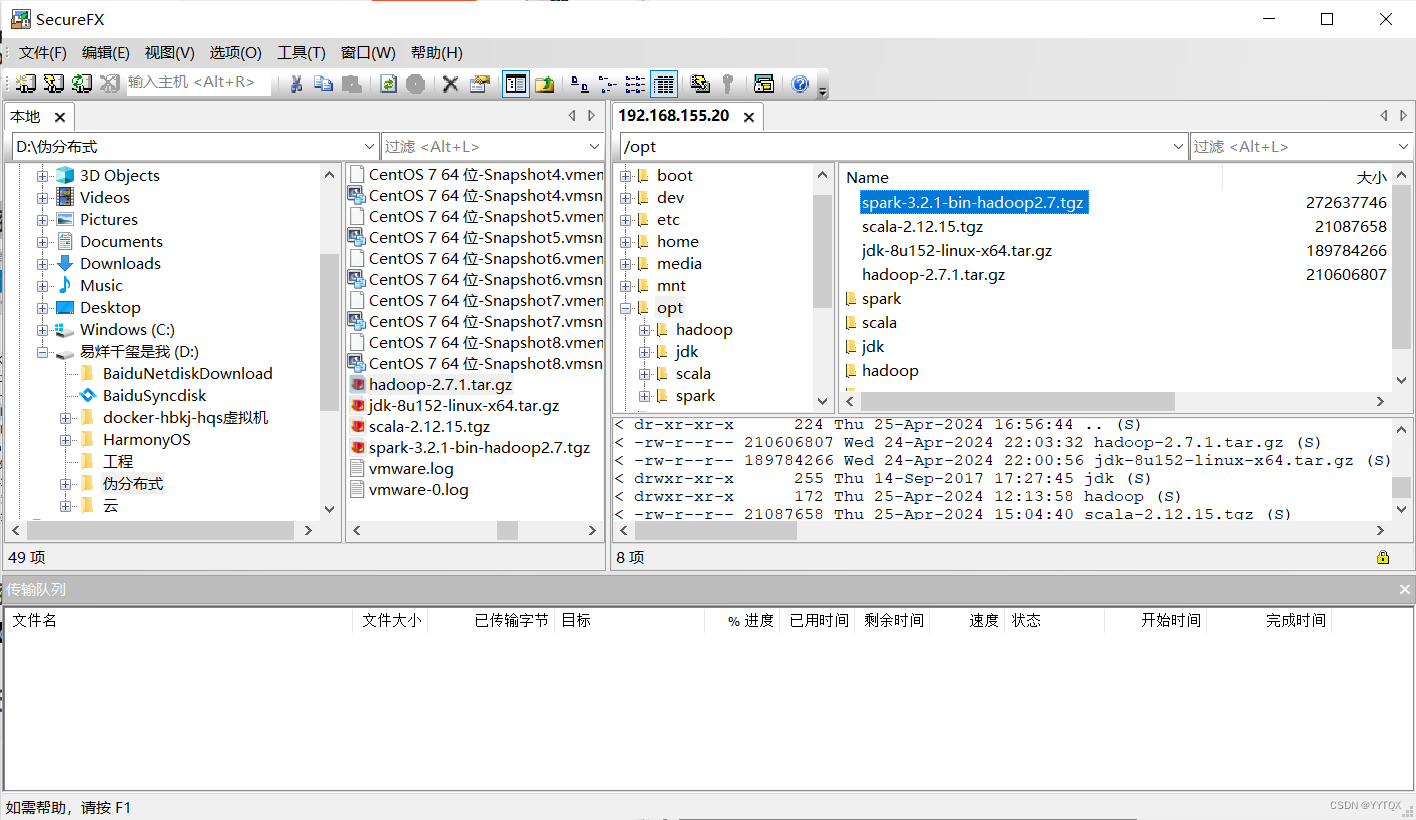

tar解压
![]()
解压完成spark后查看:ls

把文件名改为spark

2.配置spark的环境变量
用vi修改/etc/profile文件:
vi /etc/profile
![]()
在末尾输入
- export SPARK_HOME=/opt/spark //自己的文件路径
- export PATH=$PATH:${SPARK_HOME}/bin
- export PATH=$PATH:${SPARK_HOME}/sbin

保存好后就(重启)source一下配置文件
source /etc/profile
![]()
3.修改配置文件
先备份文件cp spark-env.sh.template文件
进入到/conf目录下
cd /opt/spark/conf/

备份
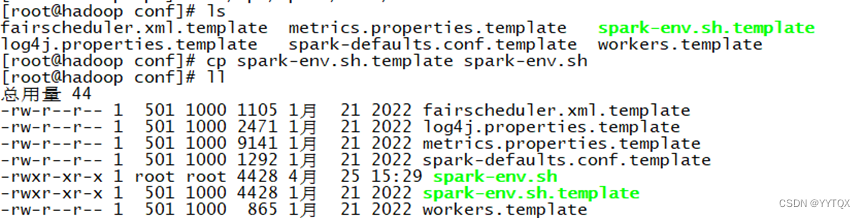
进行配置spark配置文件
进入spark-env.sh文件:vi spark-env.sh
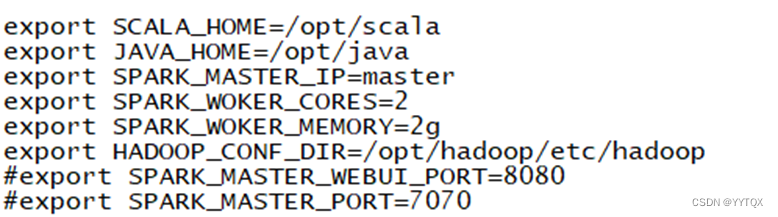
末尾添加:
export SCALA_HOME=/opt /scala
export JAVA_HOME=/opt/java
export SPARK_MASTER_IP=master
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop
#export SPARK_MASTER_WEBUI_PORT=8080
#export SPARK_MASTER_PORT=7070
4.进入spark/sbin 启动spark ./start-all.sh
- cd /opt/ spark/sbin
- ./start-all.sh

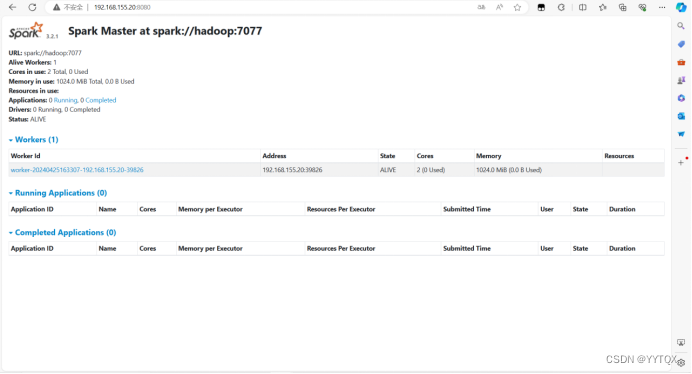
5.查看一下
./bin/spark-shell
















 1201
1201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









