







 本文详细介绍了Java集合框架,包括List、Map、Set接口及其各种实现类,如ArrayList、HashMap、LinkedList等。同时,讨论了并发容器如ConcurrentHashMap和CopyOnWriteArrayList的特点和适用场景,强调了它们在多线程环境下的性能优势。此外,文章还涵盖了Collections工具类的功能,如不可修改包装、同步包装和动态类型检查包装。
本文详细介绍了Java集合框架,包括List、Map、Set接口及其各种实现类,如ArrayList、HashMap、LinkedList等。同时,讨论了并发容器如ConcurrentHashMap和CopyOnWriteArrayList的特点和适用场景,强调了它们在多线程环境下的性能优势。此外,文章还涵盖了Collections工具类的功能,如不可修改包装、同步包装和动态类型检查包装。
JAVA集合框架可以是说是JAVA开发中使用次数最高的一套类,是JAVA对各种数据结构的实现。一个集合代表一组对象,使用集合框架可以独立于实现细节来操作这一组对象,而不用自己再造轮子。
集合接口概要:
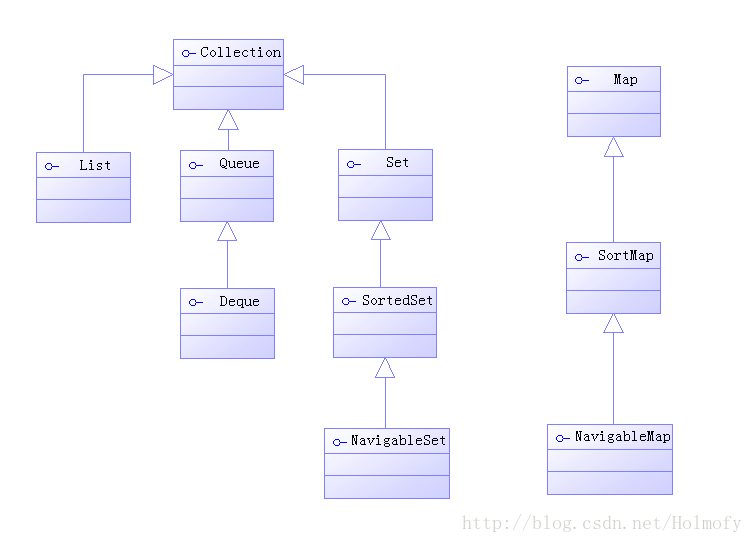
再加上并发库中的集合接口:
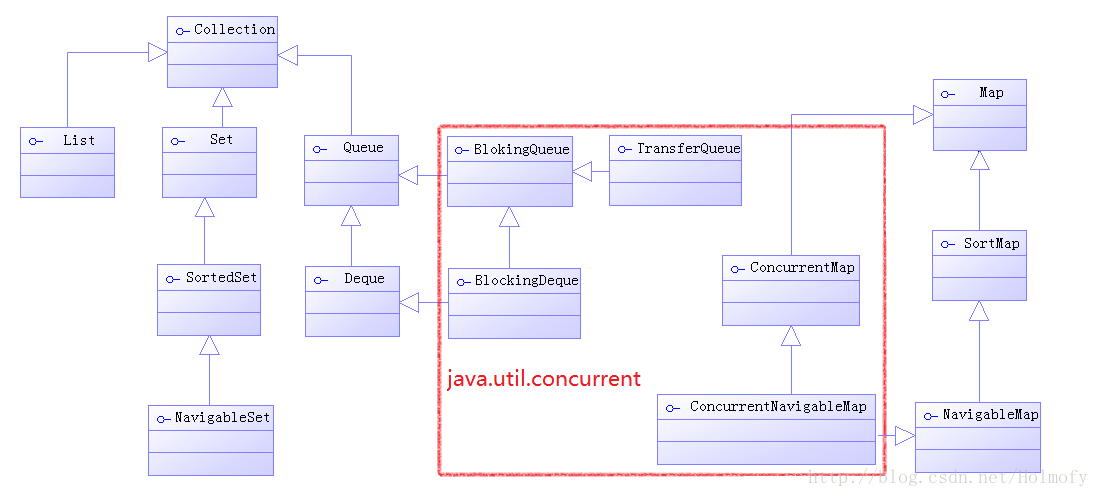
在下面的标题中用concurrent标记这个类是
java.util.concurrent包中的集合
List (since 1.2)
有序列表,代表一组有序可重复对象。
实现类:
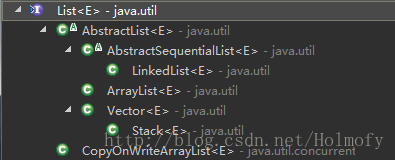
Vector(since 1.0):
与ArrayList实现基本类似,都是用Object数组存储,区别在于Vector是线程安全的,而且Vector扩容策略也比较老式:
newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity) (容量成倍增加)
如果构造时指定了capacityIncrement 扩容增量,则每次增加capacityIncrement (线性增加)。
该类完全可以使用Collections.synchronizedList(new ArrayList())代替。
JDK1.0当初的集合设计主要模仿C++的STL,可惜1.0的时候没有泛型(Java泛型与C++的模板本质上是不同的,不可相提并论),同时又为了线程安全加了
synchronized锁,重点是当初没有面向接口设计整个集合框架,最终导致了这个不伦不类的设计。
Stack(since 1.0):
“后进先出(LIFO)”的栈式结构,继承自Vector,这也决定了它被淘汰的命运:因为Deque接口的实现类可以作为栈使用
查看Deque接口
ArrayList(since 1.2):
数组实现的List,自动扩容,Java8.0中一般扩容策略为newCapacity = oldCapacity + (oldCapacity >> 1),也就是说每次扩容新容量为原始容量的1.5倍,另外在第一次添加元素的时候才申请内存(默认初始容量为10)。
ArrayList绝对是集合框架中使用次数最多的类。
LinkedList(since 1.2):
双向链表实现的List,在后续Java版本中又相继实现了Queue,Deque接口,所以该类可以当作链表、队列、栈使用。
因为LinkedList使用双向链表实现,所以作为List使用其查找元素效率不如ArrayList,但是在中间插入元素的效率比ArrayList高。
CopyOnWriteArrayList(since 1.5,concurrent):
通过拷贝数组来保证写线程不会影响到读线程(实现所谓的读写分离),所以该类允许读写同时进行;
同时使用ReentrantLock来实现多线程执行写操作的同步。
但是拷贝数组毕竟耗时,因此该类不适合用在写操作频繁的情况。
Map (since 1.2)
把Map放在前面是因为,Set的实现类是基于Map或List实现的。
表示一系列键值对映射(Key-Value)的集合,由于Map通过Key来查找Value,所以Key不能重复。
实现类:
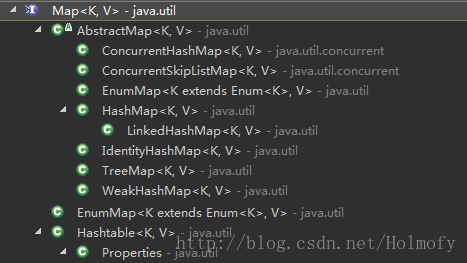
Hashtable(since 1.0):
哈希表,与HashMap实现原理相同,都是使用链式地址法解决哈希碰撞的。
与HashMap的区别:
- Hashtable使用synchronize关键字实现线程安全的,而HashMap不能保证线程安全;这一点与Vector相同
- Hashtable不允许Key为null(会抛空指针异常),而HashMap允许。
Hashtable基本被淘汰,Java的后续版本都没有对其升级。
更多相关内容可以查看HashMap
Propreties(since 1.0):
严格的说,这个类不能算是容器类。这个类一般用于存取属性配置文件的,该类实际上是一个Hashtable<Object,Object>对象。
public class Properties extends Hashtable<Object,Object>HashMap(since 1.2):
HashMap在集合框架中的地位举足轻重,所以Java在每个版本中都对它进行了大大小小的性能优化。
HashMap对计算hash值的优化
哈希表,根据Key生成hashCode从而确定存储位置,时间复杂度为1,获取哈希值方法如下:
static final int hash(Object key) {
int h;
// 低位与高位异或,目的是让HashMap的bucket较小时,高位也能参与哈希取余
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}对于hash相同的元素(也就是哈希碰撞)使用链表(拉链法)进行延伸存储,拉链使用头插法。
当总体容量达到数组长度的0.75倍这个默认阈值后,重新定容,将数组长度扩大到原来的两倍,并将原来的数据重新计算hash存入新表中,这个过程叫做rehash。
HashMap重新定容耗时耗资源,所以如果能确定存取元素的最大容量,最好在构造时通过initialCapacity参数来指定容量,默认初始容量为16( 24 2 4 )。
同时也可以通过构造方法中的loadFactor参数来自定义扩容因子,默认扩容因子为0.75。
另外,HashMap的容量始终保持为 2n 2 n 。这样设计为了方便直接根据哈希值定位索引(用&位运算取代%取余运算):
index = (length - 1) & hash
当 length=2n l e n g t h = 2 n 时, length−1 l e n g t h − 1 的二进制为全
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 137
137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









