







目录
一、删除文件,文件改名函数
int ret = rename("copy.txt" , "copy2.avi"); //旧名 , 新名
int ret = remove("paste.txt");
两者都是成功返回0,失败返回-1;
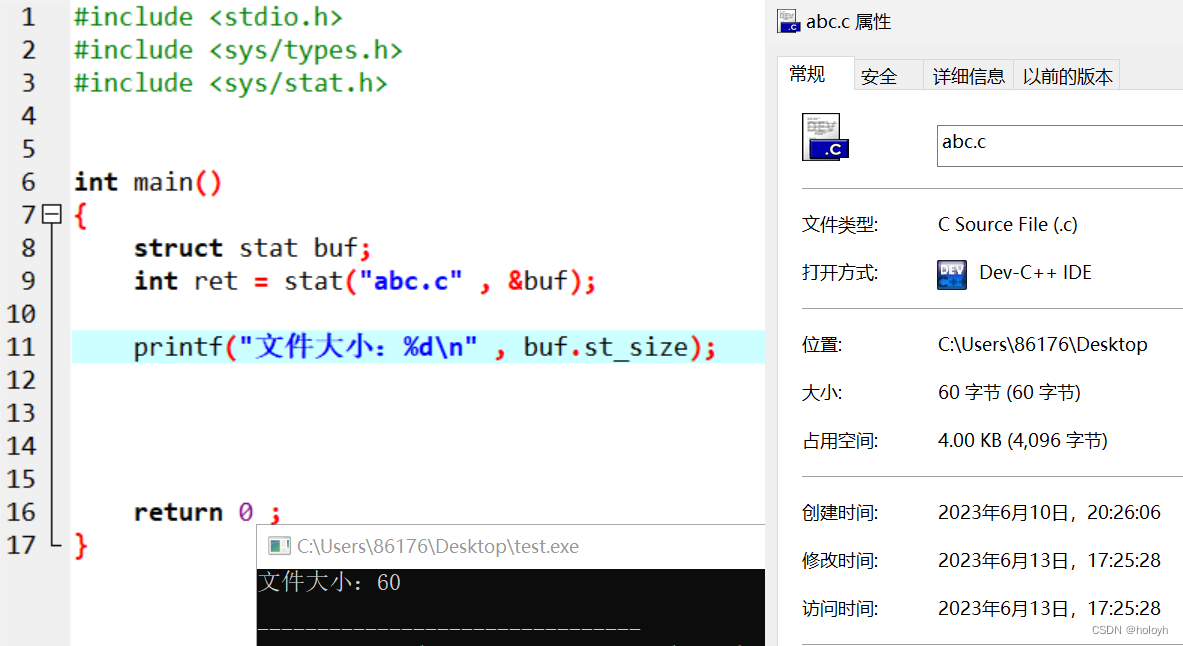
二、察看文件大小
1.不打开文件
下图是linux下的结构体,windows下可能稍有不同。

2.打开文件察看文件大小
`ftell` 是一个标准库函数,用于获取文件流指针的当前位置(即指针相对于文件开头的偏移量)。
具体用法如下
long ftell(FILE *stream);`ftell` 函数接受一个文件流指针 `stream` 作为参数,并返回一个 `long` 类型的值,表示当前指针位置相对于文件开头的偏移量。
请注意,`ftell` 函数返回的值是相对于文件开头的偏移量,以字节为单位。如果发生错误,`ftell` 函数将返回一个特殊的值 `EOF`。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
FILE *fp = fopen("abc.c" , "r");
fseek(fp , 0 , SEEK_END);
int len = ftell(fp);
printf("文件大小:[%d]\n",len); //60
fclose(fp);
return 0 ;
}
三、linux和windows下文件的区别

四、刷新缓冲区
就是指把缓冲区的数据放到输入设备或者输出设备里。

#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
FILE *fp = fopen("abc.c" , "w+");
if(fp == NULL){
perror("open error");
return;
}
char ch = 0;
while(1){
scanf("%c" , &ch);
fflush(fp);
if(ch == ':'){
break;
}
fputc( ch , fp);
}
fclose(fp);
return 0 ;
} 
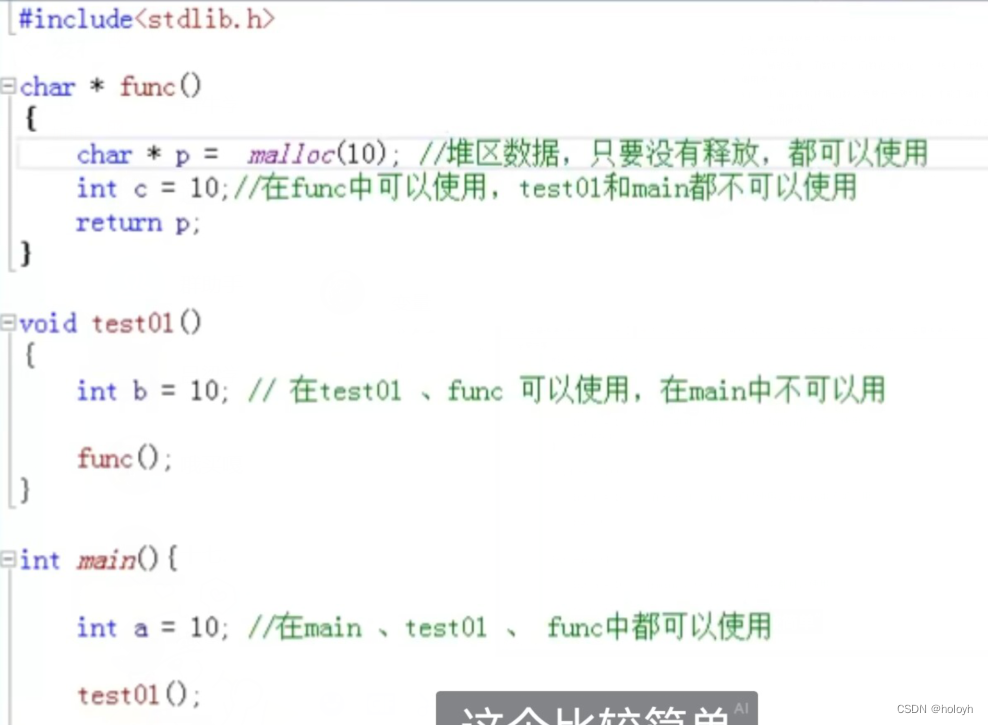
五、函数调用模型(调用惯例)
主调函数与被调函数之间统一的约定,成为调用惯例。

六、宏函数的特点

七、函数调用的变量
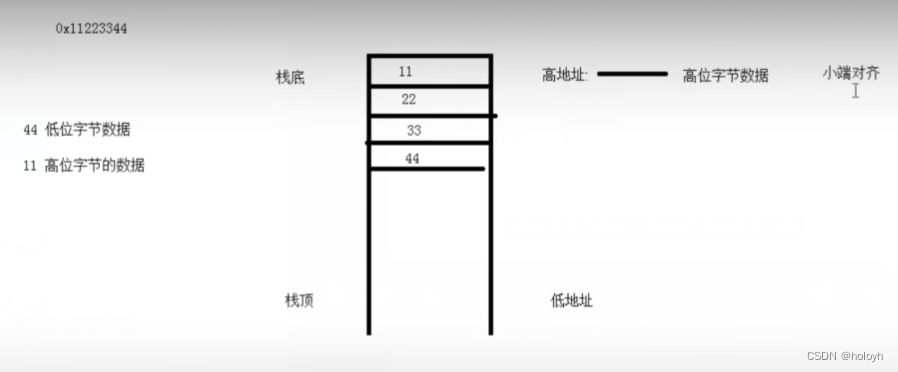
八、内存存放方向
小端对齐
#include <stdio.h>
void test01(){
int a = 0x11223344;
char *p = (char *)&a;
printf("%x\n" , *p); //44 低位字节数据 低地址
printf("%x\n" , *(p+1)); //33 高位字节数据 高地址
}
int main(){
test01();
} 
九、指针步长的两个作用
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <stddef.h> //offserof 的 头文件
//指针步长 代表 解引用后,解出的字节数量
void test01(){
char buf[1024] = {0};
int a = 1000;
memcpy(buf+1 , &a , sizeof(int)); //dst arc size
char *p = buf;
printf("%d\n" , *(int *)(p+1)); //1000
}
//指针步长 代表 指针+1后跳跃的字节数
void test02(){
char *p = NULL;
printf("%d\n" , p); //0
printf("%d\n" , p+1); //1
double *p2 = NULL;
printf("%d\n" , p2); //0
printf("%d\n" , p2+1); //8
}
//步长练习 , 自定义数据类型练习
struct Person{
char a; //0~3
int b; //4~7
char buf[64]; //8~71
int d; //72~75
};
void test03(){
struct Person p = {'a' , 10 , "hello world" , 20};
printf("d属性的偏移量:%d\n" , offsetof(struct Person , d)); //72
//返回成员变量d在结构体Person起始地址的偏移量。
//offsetof宏用于处理底层的内存操作,如在结构体中访问特定位置的数据。
//返回前面三个成员变量所占用的字节数之和,表示成员变量d相对于结构体起始地址的偏移量。
printf("d属性的值为:%d\n" , *(int *)((char *)&p+72)); //20
}
int main(){
test03();
}
十、malloc和calloc
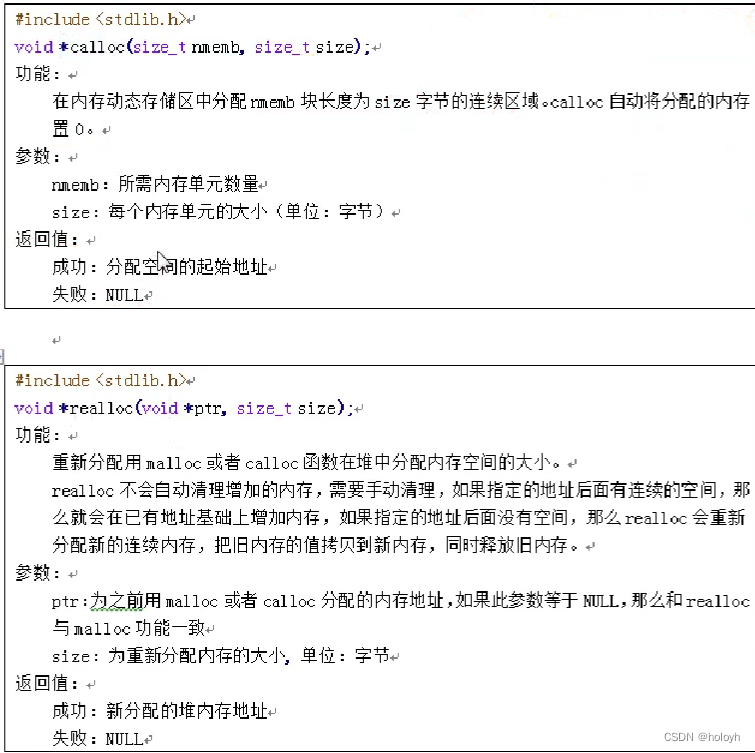
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <malloc.h>
int *p = NULL;
void test01(){
p = (int *)calloc(10 , sizeof(int));
p[0] = 1;
p[1] = 2;
}
int main(){
test01();
for(int i=0; i<4; i++){
printf("p[%d] == [%d]\n" , i , p[i]);
}
return 0;
} p[0] == [1]
p[1] == [2]
p[2] == [0]
p[3] == [0]
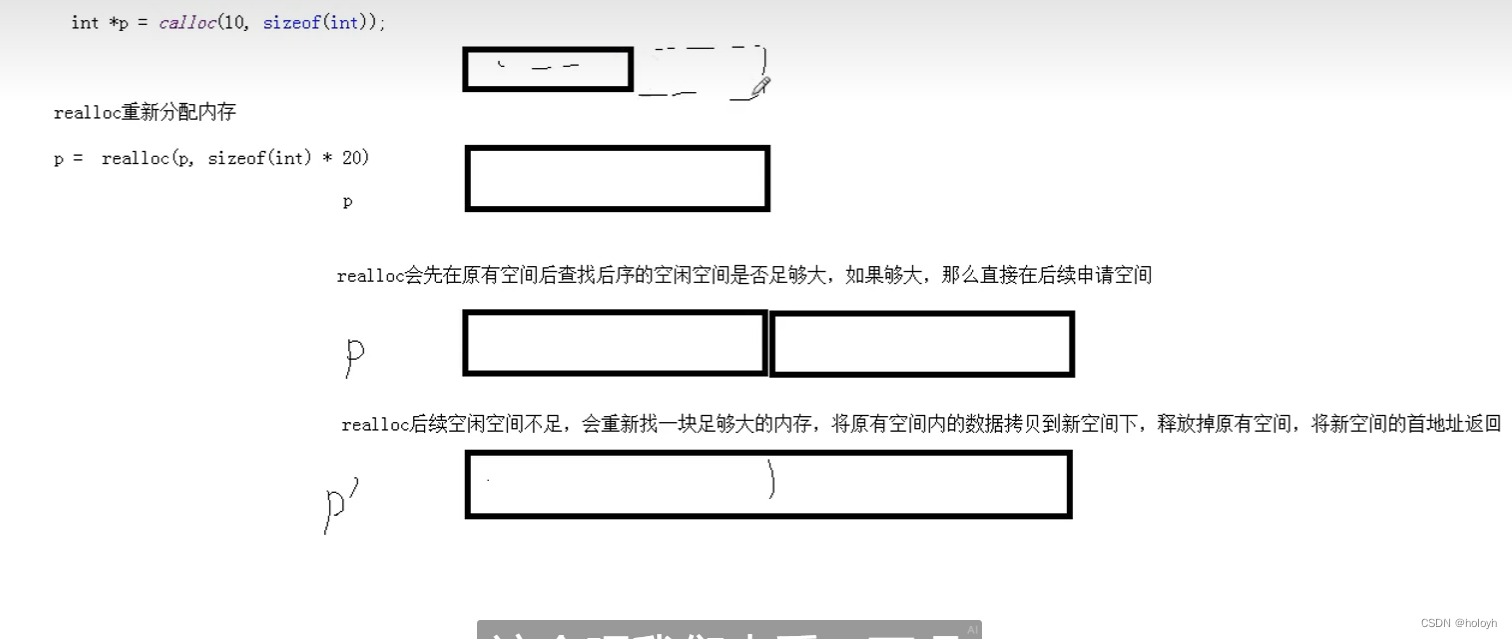
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <malloc.h>
int *p = NULL;
void test01(){
p = (int *)calloc(10 , sizeof(int));
p[0] = 1;
p[1] = 2;
// for(int i=0; i<4; i++){
// printf("p[%d] == [%d]\n" , i , p[i]);
// }
printf("%d\n",p);
}
void test02(){
p = (int*)realloc(p , sizeof(int)*20);
for(int i=0; i<20; i++){
printf("p[%d] == [%d]\n" , i , p[i]);
}
printf("%d\n",p);
}
int main(){
test01();
test02();
return 0;
} 7738336
p[0] == [1]
p[1] == [2]
p[2] == [0]
p[3] == [0]
p[4] == [0]
p[5] == [0]
p[6] == [0]
p[7] == [0]
p[8] == [0]
p[9] == [0]
p[10] == [-1191182151]
p[11] == [28457]
p[12] == [7733584]
p[13] == [0]
p[14] == [7763376]
p[15] == [0]
p[16] == [1634887535]
p[17] == [1766203501]
p[18] == [544433516]
p[19] == [909670440]
7738336


十一、sscanf函数
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void test01(){
char *str = "12345abcde";
char buf[1024] = {0};
memset(buf , 0 , sizeof(buf));
sscanf(str , "%*d%s" ,buf); //忽略数字
// printf("%s\n",buf); //abcde
// str = "abcde 12345"; //遇到空格或者\t都代表忽略结束。
str = "abcde12345";
memset(buf , 0 , sizeof(buf));
sscanf(str , "%*[a-z]%s" ,buf); //把a-z都忽略
printf("%s\n",buf);
str = "abcdea12345";
memset(buf , 0 , sizeof(buf));
sscanf(str , "%6s" ,buf); //取前6个字符
printf("%s\n",buf); //abcdea
sscanf(str , "%[a-c]" ,buf); //取a-c
printf("%s\n",buf); //abc
str = "1234aB5e";
memset(buf , 0 , sizeof(buf));
sscanf(str , "%[0-9]" ,buf); //取数字
printf("%s\n",buf); //1234
sscanf(str , "%*d%[aBc]" ,buf); //取a或B或c
printf("%s\n",buf); //aB
sscanf(str , "%[^5]" ,buf); //取非5
printf("%s\n",buf); //1234aB
sscanf(str , "%[^b-z]" ,buf); //取非a-z
printf("%s\n",buf); //1234aB5
}
void test02(){
char str[100] = "127.0.0.1";
int n1,n2,n3,n4;
sscanf(str , "%d.%d.%d.%d" , &n1 , &n2 , &n3 , &n4);
printf("[%d][%d][%d][%d]",n1,n2,n3,n4); //[127][0][0][1]
}
void test03(){
char str[100] = "anasd#holo@123";
char buf[1024];
sscanf(str , "%*[^#]#%[^@]" , buf); //holo
printf("%s\n" , buf);
strcpy(str , "helloworld@holo.cn") ;
char buf1[1024] , buf2[1024];
sscanf(str , "%[^@]%*@%s" , buf1 , buf2);
printf("[%s]\n[%s]" , buf1 , buf2); //[helloworld] [holo.cn]
}
int main(){
test03();
return 0;
} 十二、配置文件读写案例
config.txt
#英雄ID 注释
heroId:1
#英雄姓名
heroName:亚瑟
#英雄攻击力
heroAtk:1000
#英雄防御力
heroDef:1000
#英雄简介
heroInfo:前排坦克
config.c
这段代码是一个简单的配置文件解析程序。它读取指定文件中的文本内容,解析出配置项的键值对,并提供根据键获取值的功能。
下面是代码的主要功能解释:
- 定义了一个结构体
ConfigInfo,用于存储配置项的键值对。 isVaildLines函数用于判断一行文本是否是有效配置项。如果该行中包含:字符,则认为是有效配置项,返回 1;否则返回 0。getFileLines函数用于获取指定文件中的有效配置项的行数。它打开文件,逐行读取文本内容,并调用isVaildLines函数判断每一行是否是有效配置项。parseFile函数用于解析文件内容,提取有效配置项的键值对。它首先根据行数动态分配存储配置项的内存空间,然后打开文件,逐行读取文本内容,使用strchr函数找到键值分隔符:,并使用strncpy函数将键和值分别复制到对应的结构体成员中。getInfoByKey函数用于根据键获取对应的值。它遍历配置项数组,逐个比较键是否匹配,如果找到匹配的键,则返回对应的值;如果没有找到匹配的键,则返回 NULL。freeConfigInfo函数用于释放配置项数组占用的内存。它接收一个ConfigInfo结构体数组的指针,并使用free函数释放内存,并将指针置为 NULL。- 在
main函数中,首先获取配置文件的有效行数,然后调用parseFile函数解析文件内容,将解析结果存储在configInfo结构体数组中。接着通过调用getInfoByKey函数,根据键获取对应的值,并打印出来。最后调用freeConfigInfo函数释放内存。
这段代码适用于读取配置文件,提取配置项的键值对,并根据键获取对应的值。
#include <stdio.h>
#include <string.h>
#include <iostream>
#include <stdlib.h>
#include <Windows.h>
using namespace std;
struct ConfigInfo{
char key[32];
char value[32];
};
int isVaildLines(char *str){
if(strchr(str,':') == NULL){
return 0;
}else{
return 1;
}
}
//获取文件的有效行数
int getFileLines(char * filePath){
FILE *fp = fopen(filePath , "r");
if(fp == NULL){
perror("fopen error");
return -1;
}
int lines = 0;
char buf[1024] = {0};
while(fgets(buf , 1024 , fp) != NULL){
if(isVaildLines(buf) == 1){
lines++;
}
memset(buf , 0 , sizeof(buf));
}
fclose(fp);
return lines;
}
//解析文件
void parseFile(char *filePath , int lines , struct ConfigInfo ** configInfo){
struct ConfigInfo * info = (struct ConfigInfo * )malloc(sizeof(struct ConfigInfo) * lines);
if(info == NULL){
return;
}
FILE *fp = fopen(filePath , "r");
if(fp == NULL){
perror("fopen error");
return;
}
char buf[1024] = {0};
// int Vaild = 0;
int index = 0;
while(fgets(buf , 1024 , fp) != NULL){
if(isVaildLines(buf) == 1){
// lines++;
memset(info[index].key , 0 , sizeof(info[index].key) );
memset(info[index].value , 0 , sizeof(info[index].value) );
char *pos = strchr(buf , ':');
/*
sscanf(buf , "%[^:]%*:%s" , info[index].key , info[index].value);*/
strncpy(info[index].key , buf , pos - buf);
strncpy(info[index].value , pos+1 , strlen(pos+1)-1);
// strcpy(info[index].value , pos+1);
index++;
}
memset(buf , 0 , sizeof(buf));
}
*configInfo = info;
}
char * getInfoByKey(char * key , struct ConfigInfo * configInfo , int lines){
for(int i=0; i<lines; i++){
if(strcmp(key , configInfo[i].key) == 0){
return configInfo[i].value;
}
}
return NULL;
}
void freeConfigInfo(struct ConfigInfo *configInfo){
if(configInfo != NULL){
free(configInfo);
configInfo = NULL;
}
}
int main(){
char *filePath = (char *)"./config.txt";
int lines = getFileLines(filePath);
printf("有效行数为:[%d]\n",lines);
struct ConfigInfo * configInfo = NULL;
parseFile(filePath , lines , &configInfo);
printf("heroId = [%s]\n" , getInfoByKey("heroId" , configInfo , lines));
printf("heroName = [%s]\n" , getInfoByKey("heroName" , configInfo , lines));
printf("heroAtk = [%s]\n" , getInfoByKey("heroAtk" , configInfo , lines));
printf("heroDef = [%s]\n" , getInfoByKey("heroDef" , configInfo , lines));
printf("heroInfo = [%s]\n" , getInfoByKey("heroInfo" , configInfo , lines));
//释放
freeConfigInfo(configInfo);
configInfo = NULL;
return 0;
}有效行数为:[5]
heroId = [1]
heroName = [亚瑟]
heroAtk = [1000]
heroDef = [1000]
heroInfo = [前排坦克]
十三、文件的加密和解密
这段代码实现了文件的加密和解密操作。
codeFile 函数用于对源文件进行加密,并将加密后的内容写入目标文件。具体步骤如下:
- 使用
srand(time(0))设置随机数种子,以确保每次运行生成不同的随机数序列。 - 打开源文件和目标文件,如果文件打开失败则输出错误信息并返回。
- 使用
fgetc函数从源文件中逐个字符读取,将字符转换为short类型的整数。 - 将读取的
short类型整数左移 4 位,并将最高位设置为 1(即二进制的 1000000000000000)。 - 通过
rand() % 16生成一个范围在 0 到 15 之间的随机数,并加到short类型整数上。 - 使用
fprintf函数将加密后的整数转换为字符串并写入目标文件。 - 关闭源文件和目标文件。
decodeFile 函数用于对加密文件进行解密,并将解密后的内容写入目标文件。具体步骤如下:
- 打开加密文件和目标文件,如果文件打开失败则输出错误信息并返回。
- 使用
fscanf函数从加密文件中按照%hd格式读取一个short类型的整数。 - 将读取的
short类型整数左移 1 位,然后右移 5 位,将高位的加密标记位移除。 - 将解密后的
short类型整数转换为char类型,并使用fputc函数将其写入目标文件。 - 循环执行步骤 2-4 直到加密文件的末尾。
- 关闭加密文件和目标文件。
需要注意的是,这段代码使用简单的位操作进行加密和解密,并不是强大的加密算法。它只是给出了一个简单的示例来演示文件加密和解密的基本原理。在实际应用中,需要使用更加复杂和安全的加密算法来保护敏感数据的安全性。
void codeFile(char *sourceFilePath,char *destFilePath){
srand(time(0));
FILE *fp_r = fopen(sourceFilePath , "r");
FILE *fp_w = fopen(destFilePath , "w");
if(fp_r == NULL || fp_w == NULL){
perror("fopen error");
return;
}
char ch;
while((ch = fgetc(fp_r)) != EOF){
short temp = (short)ch;
temp = temp << 4;
temp = temp | 0x8000;
temp += rand() % 16; //0~15
// printf("%d\n",temp);
fprintf(fp_w , "%hd" , temp);
}
fclose(fp_w);
fclose(fp_r);
}
void decodeFile(char *sourceFilePath , char *destFilePath){
FILE *fp_r = fopen(sourceFilePath , "r");
FILE *fp_w = fopen(destFilePath , "w");
if(fp_r == NULL || fp_w == NULL){
perror("fopen error");
return;
}
short temp;
char ch;
while((!feof(fp_r))){ //用short读
fscanf(fp_r , "%hd" , &temp);
temp <<= 1;
temp >>= 5;
ch = (char)temp;
fputc(ch , fp_w);
}
fclose(fp_r);
fclose(fp_w);
}















 1460
1460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









