







一、思路介绍
我们的目的是从平台上爬取视频并且提取视频的文案
那我们就可以分为两大步去实现我们的目的:
1.爬取(爬取视频)
本次爬虫使用的是requests库,以及re、json库做辅助
2.从视频中提取文案
视频提取文案的方法有两种:1.通过分离视频中的音频,找到语音转文字的第三方库或者一个免费的API接口。2.通过提取字幕来获取文案信息。
不多说开始进入干货环节
二、具体实现
(一)爬取

这段口令最重要的是中间的链接https : //v. d😊 o😊u y i 😊n.com/iM Bb Hq M 1/,我们需要通过正则表达式获取,这段链接在网页中打开后会做一个跳转,如下图:
![]()
但在这个页面我们很难通过requests直接进行爪宝获取视频,所以我们还要做手脚让上面的网址变一下格式,后我们就可以进行爪宝提取视频了
具体代码如下:
import json
import re
import requests
from urllib.parse import unquote
from moviepy.editor import VideoFileClip
from paddleocr import PaddleOCR
import json
import re
import requests
from urllib.parse import unquote
from moviepy.editor import VideoFileClip
from paddleocr import PaddleOCR
class App:
def __init__(self):
self.links = [] # 存储批量获取的口令链接
self.headers = {
"User-Agent": 用户代理,
"Cookie": 页面Cooki,
"Referer": "https://www.douyin.com/"
}
def Password_extraction(self, text1): # 获取文本中的链接
pattern = r"https://v\.douyin\.com/([a-zA-Z0-9_]+)"
# 使用正则表达式搜索文本
match = re.search(pattern, text1)
if match:
short_url = match.group()
response = requests.get(short_url, allow_redirects=True, headers=self.headers)
print(response.url)
long_url = response.url
pattern = r"https://www\.douyin\.com/video/(\d+).*?"
match = re.search(pattern, long_url)
video_id = match.group(1)
new_url = f"https://www.douyin.com/discover?modal_id={video_id}"
print("匹配到的链接:", new_url)
self.links.append(new_url)
else:
print("没有找到匹配的链接")之后我们要开始进行爪宝获取视频地址(图片中要搜索的内容也不一定是&ft,也许是&rc只要可以找到后面描述的内容即可)
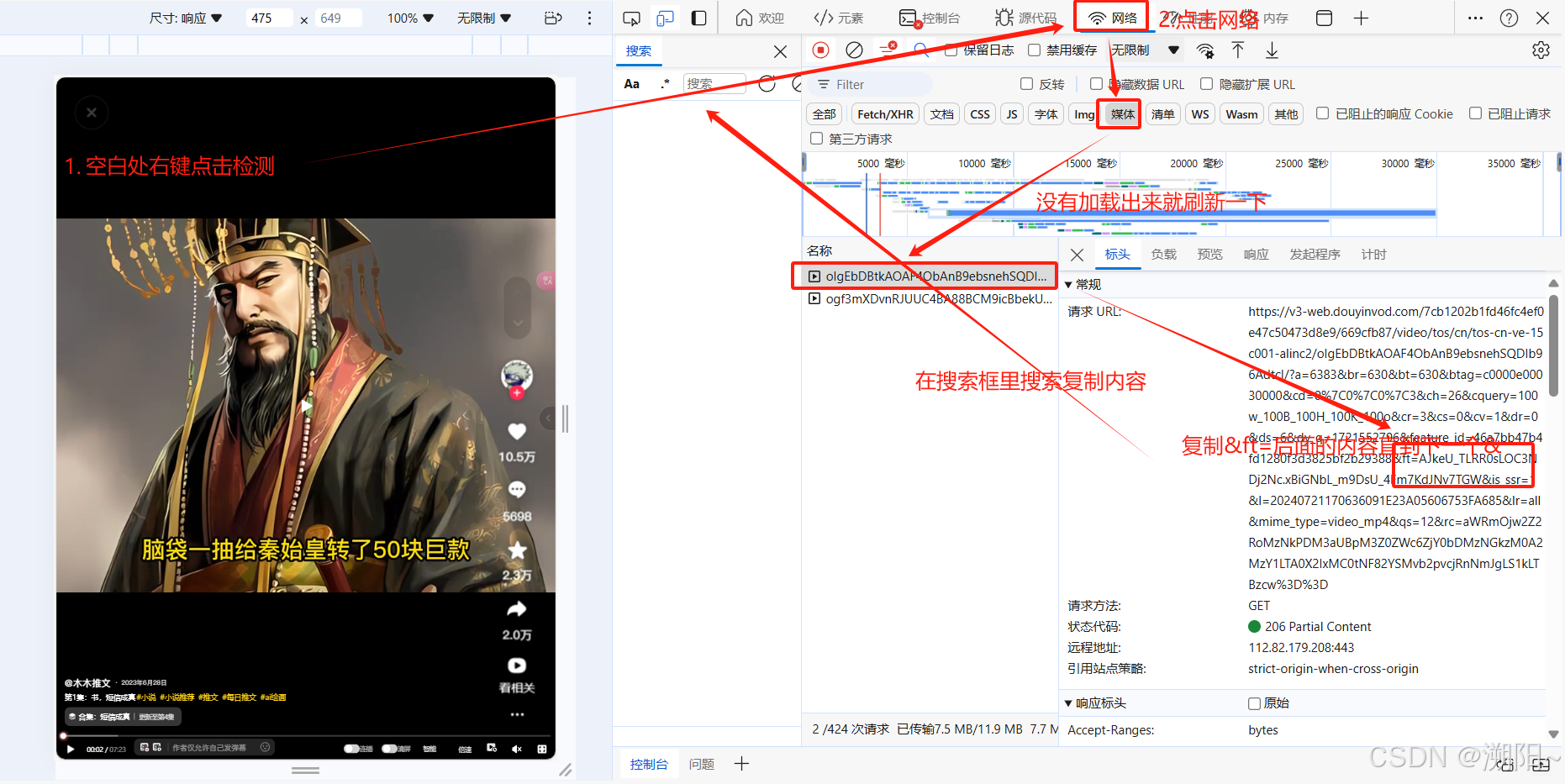
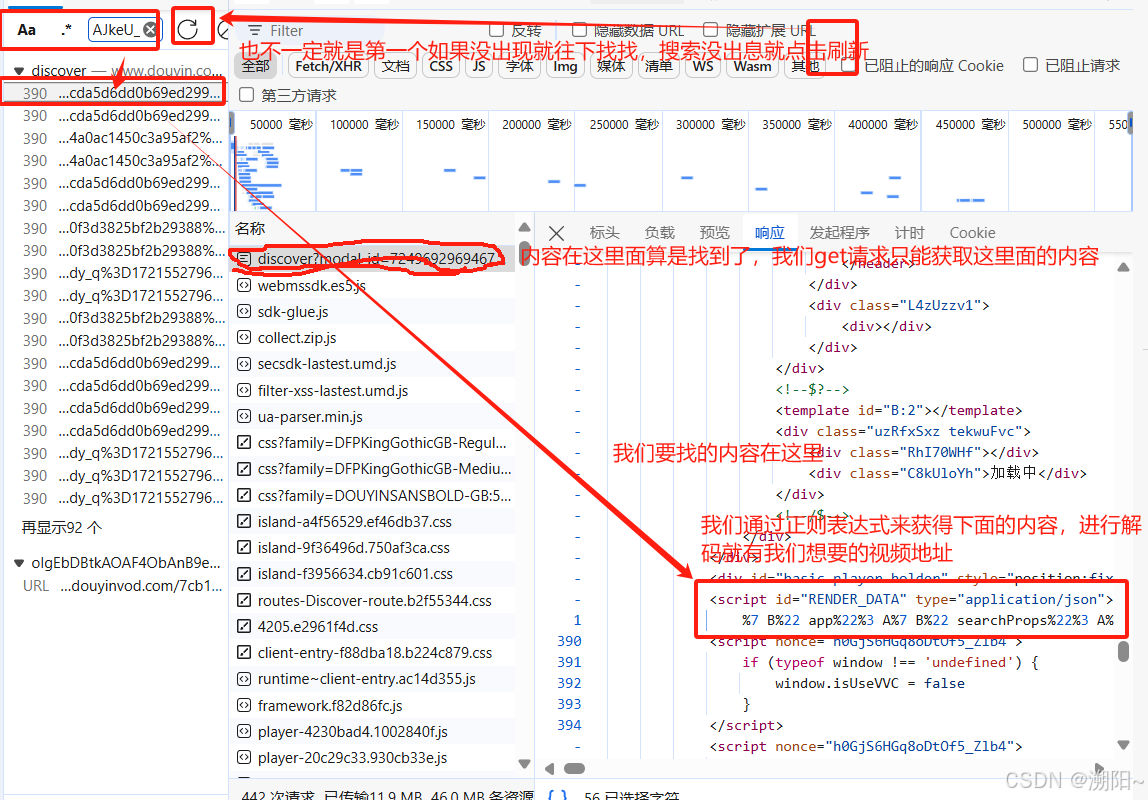
欧克我们编辑正则表达式来获取我们想要的内容吧
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









