






Mysql
1.mysql常用命令
--刷新事务
FLUSH PRIVILEGES;
--运行指定sql文件
source /usr/tmp/xxx.sql;
--创建用户,%代码所有地址均可访问
CREATE USER '用户名'@'%' IDENTIFIED BY '密码';
--导出单表
mysqldump -u 用户名 -p 数据库名 表名 > 文件名.sql;
--带条件的导出单表
mysqldump -u 用户名 -p 数据库名 表名 --where="条件" > 要存放的路径地址及文件名.sql;
例子:mysqldump -u root -p zhhy tb_b_geo --where="id='00000000340e813b0134165d7f041a8d'" > /data/tb_b_geo1.sql;
--中文排序
CONVERT(a.name USING GBK) ASC;
--设置值为需要的大小(1024×1024×具体MB)
set global max_allowed_packet=314572800;
--创建数据库并指定编码
CREATE DATABASE 数据库名 DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
--新表不存在那可以直接创建新表并复制一份数据
create table tb_b_dev_copy select * from tb_b_dev where id = '0a563088150341a9abf62951947aa546';
--新建库
CREATE DATABASE `zhhy-addr` CHARACTER SET 'utf8mb4' COLLATE 'utf8mb4_general_ci';
--新建用户
create user 'zhhy-addr'@'%' IDENTIFIED by 'ty-iFish-lw@2020';
--查看用户
SELECT user , host from mysql.user;
--删除用户
drop user `zhhy-addr`@`%`;
--授权用户
grant all privileges on `zhhy-addr`.* to `zhhy-addr`@`%` identified by 'ty-iFish-lw@2020';
2.Mysql镜像的配置文件路径:
/etc/mysql/mysql.conf.d/mysqld.cnf
3.mysql忽略大小写
配置文件里添加:lower_case_table_names=1
4.mysql服务部署成功,telnet不通
修改配置文件:bind-address=0.0.0.0
5.mysql获取重复数据中第一条数据
方法一:(如果同个人存在两个相同时间会有重复数据)
SELECT b.id, b.name, b.id_sn, b.CREATE_DATE, a.* FROM
(SELECT ID_SN, MAX(CREATE_DATE) CREATE_DATE from tb_b_inout_appl_user GROUP BY ID_SN) a --先通过ID_SN分组,然后获取最大的创建时间
INNER JOIN tb_b_inout_appl_user b on a.id_sn = b.ID_SN and a.CREATE_DATE = b.CREATE_DATE
方法二:
1.先根据时间排序将对应的id拼接起来,然后在截取获取第一个,最后查询id在刚截取第一个出来的数据里的
SELECT * from table w where w.id in (SELECT SUBSTRING_INDEX(GROUP_CONCAT(r.id ORDER BY r.INSERT_DATE DESC),',',1) FROM table r WHERE r.PAY_TABLE_ID='' GROUP BY r.PERIODS_NUMBER ORDER BY r.INSERT_DATE)
6.MySql查询所有的表和表注释
SELECT TABLE_NAME , -- 表名
TABLE_COMMENT , -- 表注释
TABLE_ROWS -- 数据量
FROM information_schema.tables
WHERE TABLE_SCHEMA = 'ty-ci' -- 数据库名
ORDER BY TABLE_NAME;
7.批量保存
<insert id="batchReOrganizationPackEntry">
insert into <include refid="tableName"/>
(id,org_id,pack_id)
values
<foreach collection="list" item="item" separator=",">
(#{item.id}, #{item.organization.id},#{item.packId})
</foreach>
</insert>
8.触发器
CREATE TRIGGER `触发器名称` AFTER 【INSERT/UPDATE/DELETE】ON `表名` FOR EACH ROW BEGIN
-- 自定义sql内容(可以是新增、修改、删除)
INSERT into `目标数据库名`.`目标表名` set `ID`=new.`id`(new.`id`代表当前新增数据的id,多个字段就后面逗号相隔);
UPDATE `目标数据库名`.`目标表名` set `NAME`=new.`NAME` where `ID`=new.`id`(new.`id`代表当前新增数据的id);
DELETE FROM `目标数据库名`.`目标表名` where `ID`=old.`id`(删除时没有新数据,所以得用old);
END;
Oracle
1.Oracle中存在某字段重复数据需要获取最新第一条数据
需求:查询FK_B_PR_VISIT_SITUATION 表中,根据ID_SN和CREATE_DATE 倒序,获取每个ID_SN最新的数据
1.先根据FK_B_PR_VISIT_SITUATION 查询并且根据ID_SN、CREATE_DATE 降序,显示ROW_NUMBER(这个代表此条数据这分组中的第几行)
2.把步骤的结果当作表,加上where rm = 1 ,代表第一行数据
SELECT * FROM(SELECT ID_SN, NM, CREATE_DATE, ROW_NUMBER () OVER ( PARTITION BY id_sn ORDER BY create_date DESC ) AS rn
FROM FK_B_PR_VISIT_SITUATION WHERE del_flag = 0 ORDER BY ID_SN, CREATE_DATE DESC ) WHERE rn = 1
2.Oracle sql计算两个时间之差
天:
ROUND(TO_NUMBER(END_DATE - START_DATE))
小时:
ROUND(TO_NUMBER(END_DATE - START_DATE) * 24)
分钟:
ROUND(TO_NUMBER(END_DATE - START_DATE) * 24 * 60)
秒:
ROUND(TO_NUMBER(END_DATE - START_DATE) * 24 * 60 * 60)
毫秒:
ROUND(TO_NUMBER(END_DATE - START_DATE) * 24 * 60 * 60 * 1000)
3.Oracle sql递归查询
根据id与parentId递归往下查询
SELECT id as id from SYS_OFFICE a where a.DEL_FLAG='0'
START WITH a.ID='xxxxxxxxxxxxx' CONNECT by PRIOR a.id=a.PARENT_ID
4.Oracle 根据字段排序,为空排最后
select * from 表名 order by 排序字段 desc nulls last
例子:
select * from ucas_individual_proj order by created_dt desc nulls last
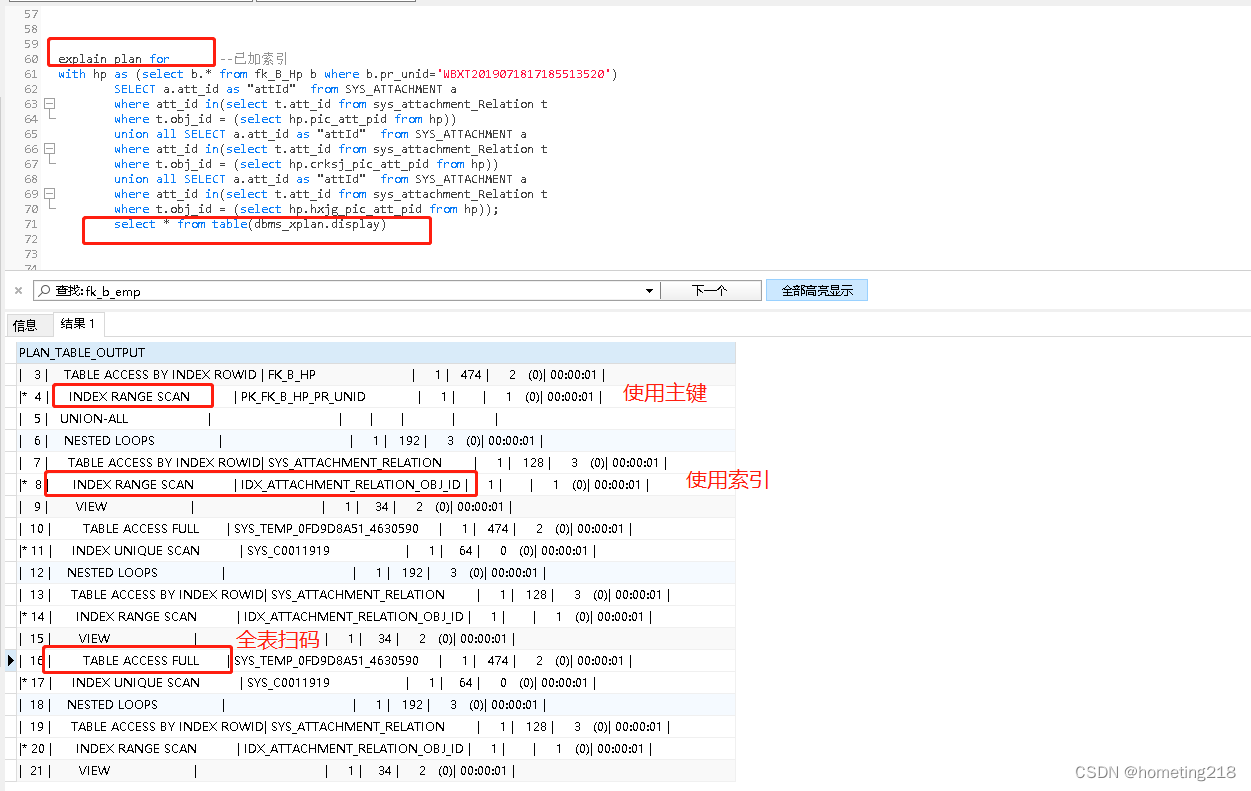
5.Oracle 查看是否使用索引
explain plan for
《执行的sql语句》;
select * from table(dbms_xplan.display);
5.update set select 语句
update "T_TEST" t set t."type" =
(
SELECT a.value from SYS_DICT_VALUE a
LEFT JOIN SYS_DICT_TYPE b on a.DICT_TYPE_ID = b.id
where b.type = 'sex' and a.LABEL = t."type"
),
t."user_id" =
(
SELECT a.id from sys_user a
LEFT JOIN SYS_OFFICE b on a.OFFICE_ID = b.id
where a.name = t."user_id" and b.name = t."office_id" and a.DEL_FLAG = '0'
),
t."office_id" =
(
SELECT a.id from SYS_OFFICE a where a.name = t."office_id" and a.DEL_FLAG = '0'
)
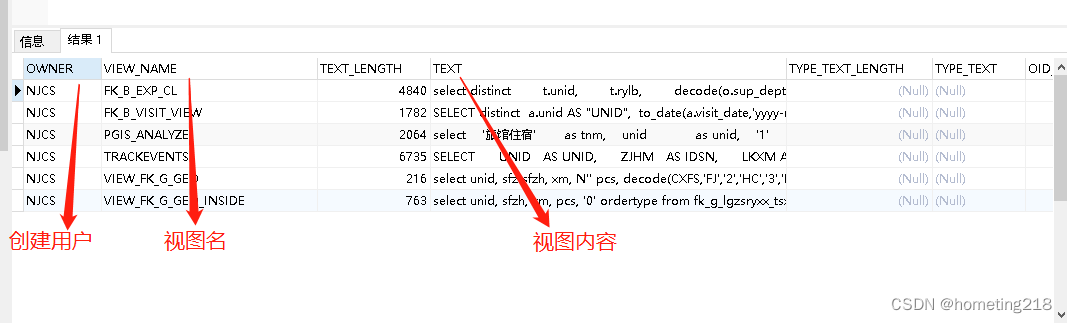
6.查询具体用户创建的视图
select * from all_views t where OWNER = 'NJCS' and view_name = 'VIEW_FK_G_GEO_INSIDE';
7. insert select语法
insert into FK_B_STOC_EXP_IN
select * from (SELECT * from FK_B_STOC_EXP_IN_TEMP where sfz not in (SELECT SFZ from FK_B_STOC_EXP_IN));
8.批量保存
<insert id="batchSave" parameterType="java.util.List">
insert all
<foreach collection="list" item="item" separator=" ">
INTO cj_msg(
id,type,type_id,title,detail,user_id,login_name,
status,create_by,create_date,update_by,update_date,remark,del_flag)
values
(#{item.id},#{item.type},#{item.typeId},#{item.title},#{item.detail},#{item.user.id},#{item.loginName},
#{item.status},#{item.createBy.id},#{item.createDate},#{item.updateBy.id},#{item.updateDate},#{item.remark},#{item.delFlag})
</foreach>
select ${list.size} from dual
</insert>
9.查询数据库下所有的表名和表注释
SELECT at.TABLE_NAME, --表名
atc.COMMENTS --表注释
FROM ALL_TABLES at LEFT JOIN ALL_TAB_COMMENTS atc ON (at.TABLE_NAME = atc.TABLE_NAME AND at.OWNER = atc.OWNER)
WHERE 1 = 1
AND at.OWNER = 'FJSYCDG' --模式名














 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









