







前言:
YARA 通常是帮助恶意软件研究人员识别和分类恶意软件样本的工具,它基于文本或二进制模式创建恶意样本的描述规则,每个规则由一组字符串和一个布尔表达式组成,这些表达式决定了它的逻辑。
但是这次我们尝试使用 YARA 作为一种扫描工具,我们根据要扫描的红队工具提取出它们特有的二进制或文本特征,希望能整理成能唯一标识该类(不同版本)的红队工具的 YARA 规则,用于对特定主机扫描时可以快速识别该主机上是否存在对应的红队工具,以加强对目标主机的了解。
发生背景:
有一天师兄给了我一个红队工具网站 https://github.com/Threekiii/Awesome-Redteam ,说让我对里面的红队工具做一下Yara 规则???
一开始我也是很懵的,我也不解为什么要对工具做 Yara 规则,因为 Yara 的确是用于提取分析恶意样本的啊。我一开始猜想是有可能是这些工具被装了后门,毕竟这种情况网上太多了,然后我就打开上面的 github 网站,仔细浏览了一下。
真的,不得不说这个网站太全了,太赞了!真的不得不佩服作者的良苦用心,所以这样一个 1.4k stats 的如此优秀的项目会有后门???

谁知道呢,下个 BP 插件目录下的 RouteVulScan——检测脆弱路径插件 扔进 VT 上看一下先:
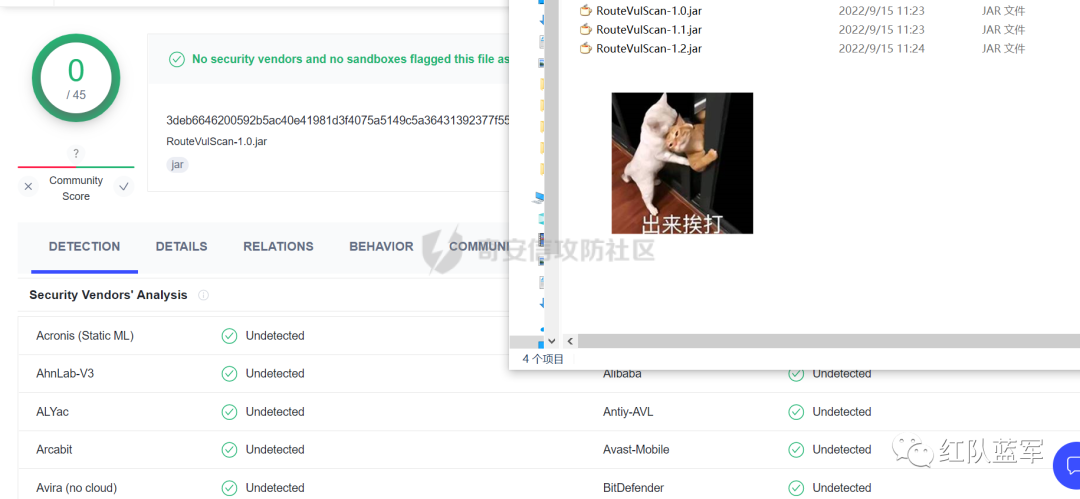
。。。有点绿啊~ 陆陆续续又试了几个,除了几个有点误报外基本都是没问题的,不得不说项目的作者还是很好的,所以这咋提取后门啊!
然后我和师兄吐槽说这些都是普通的工具啊,这怎么做 Yara 规则啊,做来干什么啊?师兄耐心的和我解释说:"一台目标主机上如果出现这些红队工具的话那是很可疑的事情,如果我们在目标内网的一台主机上扫描到这种工具的存在那我们就可以更加掌握这台主机的了解,可以判断使用者用它干了什么之类的……"
一语惊醒梦中人!我觉得非常有道理!就用 Yara 对这些红队工具打标嘛,类似一种本地软件识别工具。至于怎么打进内网?那不是我该考虑的问题。
明确要求——初步制定方案:
要做的是扫描器,平常对恶意样本做 yara 规则是通过仔细逆向来分析获取该类样本特有的混淆、固定的功能代码、特有的字符串等等能标识这一类样本的信息。
那现在正常的软件怎么分析呢,一个个逆向是不可能的,我甚至都不想扔入 IDA 里,因为这是一批工具,量大。然后就是不适合,因为很多工具我没用过,不知道功能,反汇编看了耗时耗力。最后就是没必要,我们只是用 yara 对它们打标,工具和工具相差性还是很大的,无论是字符串还是字节码,而且文件体积上很多也不是一个量级的,随便提取一点能够标识的就够了。
所以综合以上考虑我决定用字节码查看工具 010 Editor ,我使用文件比较功能把不同版本的大块的可标识该类软件的字节码提取出来,右侧的 ASCII/UNICODE 字符串栏中也可以提取自己仍未足够独特的字符串来写成 Yara 规则。

尝试对 BP 插件写 Yara 规则:
先从 "RouteVulScan——检测脆弱路径插件" 下手,拿最新的前 3 个打包好的 jar 版本开始比较,这里先拿其中两个版本进行比较,从众多相同的字节码中挑选大块的,并且自己感觉能标识该插件唯一性的作为 Yara 规则。


把字节码作为字符串,然后条件那里再加点限制,比如 jar 插件本质是压缩包,所以我们限制文件头为 "PK",对应 Yara 规则就是 int16(0)=0x4B50 ,然后在文件体积上也精确一点,这里三个版本的 jar 插件都在 30MB 以上,写成 Yara 规则就是 filesize > 30MB,最终 Yara 规则如下:
rule routevulscan {
meta:
description = "Choose commonalities from multiple versions"
strings:
$s1 = {00 00 00 62 75 72 70 2F 56 69 65 77 24 54 61 62 6C 65 2E 63 6C 61 73 73 85 52 4D 6F D3 40 10 7D EB 38 71 9D 98 34 2D 0D 50 D2 96 06 92 92 A4 A1 2E DF 12 45 BD 44 80 82 0C 1C 8A 72 C8 CD 71 57 CE 56 C6 46 8E 43}
condition:
( uint16(0) == 0x4B50 and filesize > 30MB) and $s1
对自己整个 D 盘文件全范围测试一下,避免误报:

可以看到在较大环境中测试也是可以的,没有匹配到杂七杂八的其它 jar 包(也可能是我的本地环境比较简单),那么同理我们把剩下两个 Log4j2Scan、HaE 的 Yara 规则也写出来,并在本地环境中测试一下命中及误报情况:
rule Log4j2Scan {
meta:
description = "Choose commonalities from multiple versions"
strings:
$s1 = {32 00 63 6F 6D 2F 61 6C 69 62 61 62 61 2F 66 61 73 74 6A 73 6F 6E 2F 4A 53 4F 4E 50 61 74 68 24 46 6C 6F 6F 72 53 65 67 6D 65 6E 74 2E 63 6C 61 73 73 50 4B 01 02 14 00 14 00 08 08 08 00 72 07 B7 54 00 00 00 00 02 00 00 00 00 00 00 00 1B 00 00 00 00 00 00 00 00 00 00 00 00 00}
condition:
( uint16(0) == 0x4B50 and filesize > 3MB) and $s1
}
rule HaE {
meta:
description = "Choose commonalities from multiple versions"
strings:
$s1 = {03 00 00 AA 06 00 00 33 00 00 00 62 75 72 70 2F 75 69 2F 4A 54 61 62 62 65 64 50 61 6E 65 43 6C 6F 73 65 42 75 74 74 6F 6E 24 43 6C 6F 73 65 42 75 74 74 6F 6E 54 61 62 2E 63 6C 61 73 73 9D 55}
condition:
( uint16(0) == 0x4B50 and filesize < 2MB) and $s1
}

二次制定方案——寻找"检测面":
前面初步制定的方案很快就发现不够用了,因为受制于寻找文件之间的相同性,所以面向的对象都是单一的或少数不多的整合型的 releases 版本,但其实有很多不是单独的文件形式,比如说 Yakit 这种大型工具,Py2exe 和 PyInstaller 这些 python 打包工具,那这其实就得换个思路了。
一开始我想和别的扫描工具一样去检查这些工具文件夹内某个特殊文件是否存在来判定该工具,但是想了想还是统一用 Yara 规则吧,毕竟我们要统一可用性,就不用切来切去了。
所以我要找有几个有代表性的文件来检测,即 "检测面"。
yarGen 工具利用:
由于这些大型工具我基本没用过,哪怕是用过的 Py2exe 和 PyInstaller 也只是会用而已,所以哪里会知道哪些文件是有代表性的关键文件?从几十个几百个文件中逐个挑选来尝试可不是明智的选择,所以我在网络上看到了一个自动 Yara 生成工具 yarGen。
yarGen 原理是从样本中提取所有 ASCII 和 UNICODE 字符串,并删除同时出现在 goodware 字符串数据库中的所有字符串。然后,它使用模糊正则表达式和 “乱码检测器” 对每个字符串进行评估和评分,该检测器允许 yarGen 检测和偏向真实语言而不是没有意义的字符链,前 20 个字符串将集成到生成的规则中。它能尝试识别要分析的文件之间的相似性,然后将字符串组合成所谓的 "超级规则"。
但是自动生成的 Yara 规则总是不如手工准确,yarGen 项目的作者也注意到了这一点,所以我们在其自动生成的规则上还需要进行手工调整,调整总归比自己从0到1做一个强,所以还是决定用上这个工具。
如何编写合理有效的 Yara 规则:
从 Nextron 公司博客站上如何构建最佳 Yara 规则的文章中我们知道一个有效的 Yara 规则不应该太简单,不然它会产生许多误报的规则,也不应该太复杂,否则它仅能匹配特定样本而且不比散列值好多少。

yarGen 检查所有字符串并将它们分为以下类别:
-
非常具体的字符串(检测的硬指标,例如 IP 地址、有效负载 URL、PDB 路径、用户配置文件目录,错别字语意字符串)
-
稀有字符串(有几率在正常软件中出现,例如 “wwwlib.dll”)
-
看起来很常见的字符串(并不具体但不会在好软件中出现,比如乱码字符串等)。
yarGen 推崇 Unicode 字符串优先级大于 ASCII 字符串,自动生成规则的字符串区中以 开头的为硬指标字符串,以x 开头的为稀有字符串,以 开头的为看起来很常见的字符串,以a 开头的字符串是不确定它们是否不会出现在合法软件中。那么对于这种权重不同的字符串我们可以在限制条件上也体现出来:( 1 of x* ) and ( 5 of a* ) 。
举个例子如下:
rule an_example {
meta:
description = “This is just an example”
strings:
$s1 = “Micorsoft Corportation” fullword wide
$s2 = “IM Monnitor Service” fullword wide
$x1 = “imemonsvc.dll” fullword wide
$x2 = “iphlpsvc.tmp” fullword
$x3 = “{53A4988C-F91F-4054-9076-220AC5EC03F3}” fullword
$z1 = “urlmon” fullword
$z2 = “Registered trademarks and service marks are the property of their” wide
$z3 = “XpsUnregisterServer” fullword
$z4 = “XpsRegisterServer” fullword
condition:
int16(0) == 0x4D5A and (( 1 of ($s*) ) or ( 2 of ($x*) and all of ($z*) )) and filesize < 40000
}
但有时候并不能提取出足够的规则,特别是对于我做规则的对象有些完全就是合法的,比如 py2exe 和 pyinstall 或 HFish 蜜罐等,他们甚至没法自动生成出规则!

这种情况在如何构建最佳 Yara 规则 - 第 2 部分 中其实也提及了,我们
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1257
1257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









