






在Netflix,数据支撑着我们的大部分工作。在数据平台团队中,我们构建了跨公司使用的基础设施,以处理大规模数据。
在我们最近的博客文章中,我们介绍了“数据网格 — 数据移动和处理平台”。当用户想要利用数据网格来移动和转换数据时,他们首先会创建一个新的数据网格流水线。这个流水线由多个称为“处理器”的单元组成,它们通过Kafka主题连接。这些处理器本身作为使用DataStream API实现的Flink作业。
自那时起,我们看到许多使用案例(包括Netflix图搜索)都采用了数据网格进行流处理。我们能够通过提供一些常用的开箱即用处理器,如投影、过滤、联合和字段重命名,来吸纳许多这些使用案例。
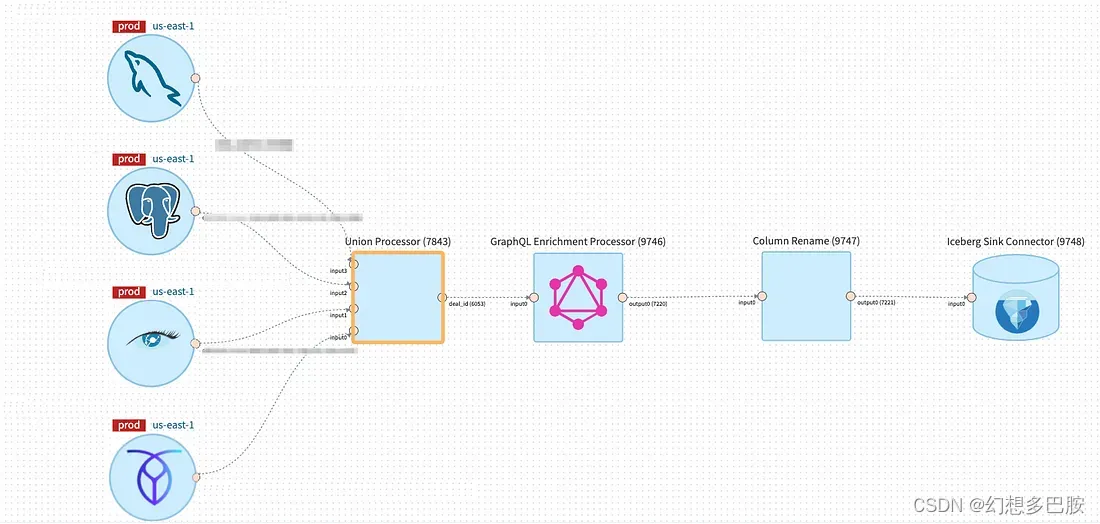
通过保持各个处理器的逻辑简单,我们使它们可以被重复使用,从而可以在大规模上进行集中管理和操作。这也使它们能够被组合使用,用户可以结合不同的处理器来表达他们需要的逻辑。
然而,这种设计决策也带来了一系列不同的挑战。
一些团队发现提供的构建块表达能力不够强大。对于无法使用现有处理器解决的使用案例,用户不得不通过构建定制处理器来表达他们的业务逻辑。为此,他们必须使用来自Flink的低级DataStream API和数据网格SDK,这需要面对陡峭的学习曲线。在构建完成后,他们还必须自行操作这些定制处理器。
此外,许多流水线需要由多个处理器组成。由于每个处理器都是作为一个Flink作业实现,并通过Kafka主题连接,这意味着许多流水线具有相对较高的运行时开销成本。
我们探索了各种解决方案来解决这些挑战,最终决定构建数据网格SQL处理器,以提供更灵活地表达用户业务逻辑的能力。
现有的数据网格处理器与SQL有很多重叠之处。例如,通过SELECT和WHERE子句可以表达过滤和投影。此外,用户不再需要通过组合多个单独的处理器来实现业务逻辑,而可以在单个SQL查询中表达他们的逻辑,避免了多个Flink作业和Kafka主题带来的额外资源和延迟开销。此外,SQL还支持用户定义函数(UDFs)和用于扩展表达能力的自定义连接器,如查找连接。
数据网格SQL处理器
由于数据网格处理器是构建在Flink之上的,考虑使用Flink SQL而不是继续为我们需要支持的每个转换操作构建额外的处理器是很有意义的。
数据网格SQL处理器是一个由平台管理的参数化Flink作业,它接受有模式的数据源和一个将针对这些源执行的Flink SQL查询。通过在数据网格处理器内部利用Flink SQL,我们能够支持流式SQL功能,而不需要改变数据网格的架构。
在幕后,数据网格SQL处理器使用了Flink的Table API来实现,这提供了一个强大的抽象,用于在DataStream和动态表之间进行转换。基于处理器连接的上游源,SQL处理器将自动将上游源转换为Flink SQL引擎中的表。用户的查询随后会被注册到SQL引擎,并转换为由Flink集群上可执行的物理操作符组成的Flink作业图。与低级DataStream API不同,用户无需手动构建作业图,因为这一切都由Flink的SQL引擎管理。
数据网格上的SQL体验
SQL处理器使用户能够充分利用数据网格平台的功能。这包括自动扩展、通过基础设施即代码声明式管理流水线,以及丰富的连接器生态系统。
为了确保用户体验的无缝性,我们增强了数据网格平台的SQL相关功能。这些增强功能包括交互式查询模式、实时查询验证和自动模式推断。
为了了解这些功能如何帮助用户提高生产效率,让我们看看用户在使用数据网格SQL处理器时的典型工作流程。
- 用户通过交互式查询模式开始其工作。他们可以实时抽样其上游数据源。
- 当用户在SQL查询上进行迭代时,查询验证服务会提供关于查询的实时反馈。
- 有了有效的查询后,用户可以再次利用交互式查询模式执行查询,并在几秒钟内将实时结果流式返回到用户界面。
- 为了更高效的模式管理和演进,平台将根据SQL查询选择的字段自动推断输出模式。
- 一旦用户完成查询编辑,它将被保存到数据网格流水线中,并部署为长时间运行的流式SQL作业。
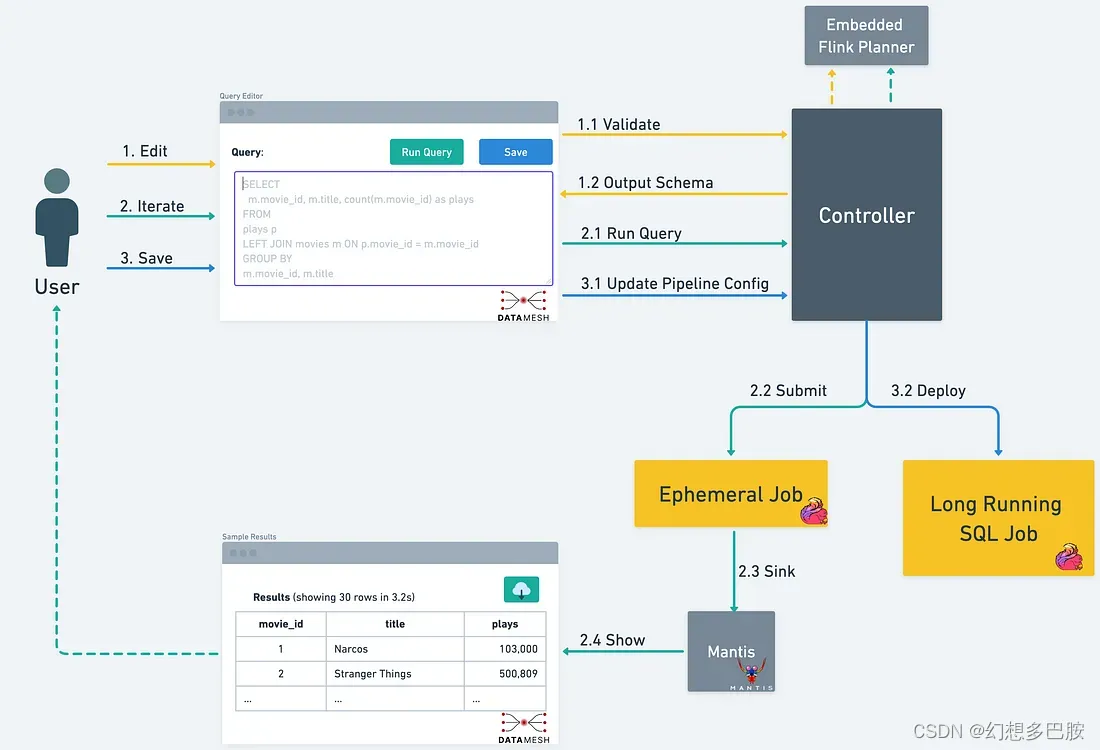
用户通常会在部署之前多次迭代其SQL查询。在部署后运行时验证和分析查询不仅会减慢迭代速度,还会使数据网格中的模式演进自动化变得困难。
为了解决这一挑战,我们实现了一个查询验证服务,可以实时验证Flink SQL查询,并为违规提供有意义的错误消息。这使用户在编辑查询时可以获得及时的验证反馈。我们利用Apache Flink的内部Planner类来解析和转换SQL查询,而无需创建完整的流式表环境。这使得查询服务轻量、可扩展且执行无关。
为了有效地在平台层操作成千上万的使用案例,我们建立了有针对性的防护措施,限制了Flink SQL的某些功能。随着时间的推移,我们计划逐步扩展支持的功能。我们通过递归检查从用户查询构建的Calcite树来实现这些防护措施。如果树中包含我们当前不支持的节点,将拒绝部署该查询。此外,我们将Flink内部异常转换为更有意义的错误消息,以帮助用户理解问题。我们计划继续投资于改进这些防护措施,因为良好的防护措施有助于改善用户体验。未来的一些想法包括制定规则以拒绝昂贵和次优的查询。
为了帮助数据网格用户快速迭代其业务逻辑,我们在平台中构建了交互式查询模式。用户可以通过执行简单的SELECT * FROM <table>查询开始实时抽样其流数据。使用交互式查询模式,数据网格平台将执行Flink SQL查询,并在几秒钟内在用户界面显示结果。由于这是针对流数据的Flink SQL查询,新的结果将继续实时传递给用户。
用户可以继续迭代和修改他们的Flink SQL查询,一旦满意查询输出,他们可以将查询保存为其流处理管道的一部分。
为了提供这种交互式体验,我们维护一个始终运行的Flink会话集群,可以运行并发的参数化查询。这些查询将它们的数据输出到Mantis的接收器中,以便将结果流式返回到用户的浏览器。
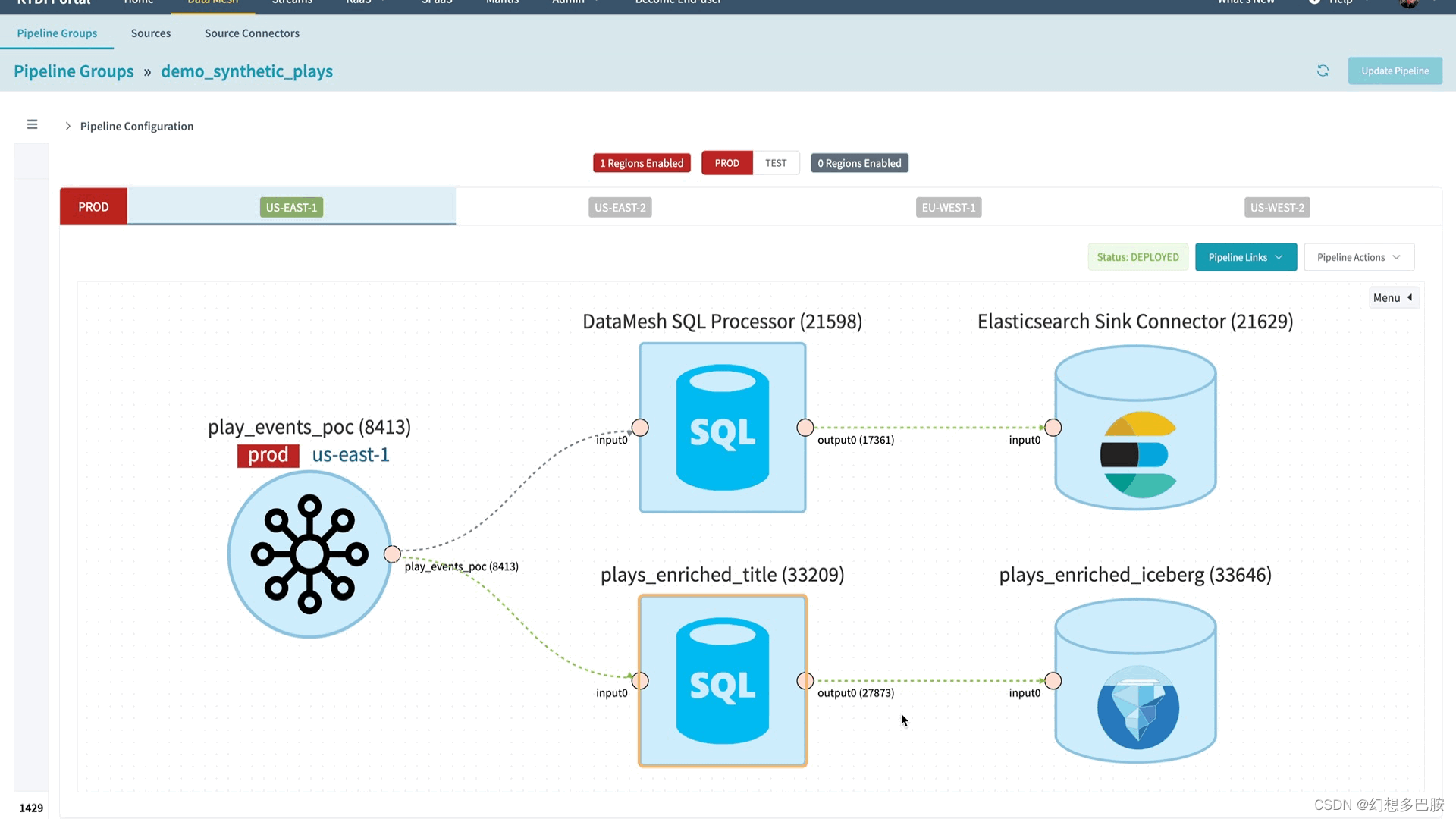
交互查询模式的操作
我们的经验教训
事后看来,我们希望早些在数据网格平台上启用Flink SQL。如果我们早些拥有数据网格SQL处理器,我们本可以避免花费工程资源来构建诸如Union处理器、列重命名处理器、投影和过滤处理器等较小的构建块。
自从我们推广使用数据网格SQL处理器以来,我们看到了来自数据网格用户的激动和快速采纳。由于Flink SQL的灵活性,用户现在有了一种新的方式来表达他们的流转换逻辑,而不是使用低级别的DataStream API编写自定义处理器。
虽然Flink SQL是一个强大的工具,但我们将数据网格SQL处理器视为平台的补充。它并不意味着取代使用低级别DataStream API编写的定制处理器和Flink作业。由于SQL是一个更高级的抽象,用户不再控制低级别的Flink运算符和状态。这意味着如果状态演进对用户的业务逻辑至关重要,那么完全控制状态只能通过像DataStream API这样的低级别抽象来实现。即使存在这种限制,我们也看到通过数据网格SQL处理器解锁了许多新的使用案例。
我们早期对防护措施的投资帮助我们与用户设定了清晰的期望,并保持了可管理的运营负担。这使我们能够推广我们有信心支持的查询和模式,同时提供了逐步引入新能力的框架。
数据网格上SQL的未来
尽管将SQL处理器引入数据网格平台是迈出的一大步,但我们仍有很多工作要做,以释放Netflix流处理的潜力。我们一直与合作团队合作,优先考虑并构建下一组扩展SQL处理器的功能。这些功能包括使用慢变维度(SCD)表进行流丰富化、时间关联加入和窗口聚合。
请继续关注更多更新!
















 3156
3156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











