







特征递归消除法 Recursive feature elimination(RFE)
RFE的基本计算过程
RFE是一种基于模型训练结果进行特征筛选的方法,通过递归不断消除无用特征。该方法的基本执行步骤如下:
- 使用给定的评估器,在当前数据集A1上进行训练并计算每个特征的重要性(coef_或feature_importances_);
- 剔除最不重要的特征,即特征重要性计算结果最小的特征,得到特征子集A2,然后再次训练模型,并计算剩余特征的特征重要性;
- 不断重复步骤2,直到特征子集的个数等于人工设置的最终保留特征个数n_features_to_select。
相比只训练一个模型,然后根据这个模型的feature_importances_对特征重要性进行排名,RFE过程更加复杂且更加精准。每次剔除特征后,剩下的特征都是在新环境中进行比较。然而,由于涉及多轮模型训练,RFE过程需要更大的计算量。
RFE在sklearn中的实现
from sklearn.feature_selection import RFE #sklearn中的feature_selection模块中找到RFE评估器
| 参数 | 解释 | 说明 |
|---|---|---|
| estimator | 带入训练的评估器 | 必须要能输出特征重要性指标 |
| n_features_to_select | 筛选后特征个数 | 默认保留一半 |
| step | 每次剔除特征的个数 | 默认每轮剔除1个特征 |
| importance_getter | 特征重要性评估指标 | 默认情况是coef_或者feature_importances_ |
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import numpy as np
# 创建示例数据集
np.random.seed(0)
n_samples = 1000
age = np.random.randint(18, 65, size=n_samples)
income = np.random.randint(20000, 150000, size=n_samples)
gender = np.random.choice(['M', 'F'], size=n_samples)
education = np.random.choice(['High School', 'Bachelor', 'Master', 'PhD'], size=n_samples)
target = np.random.choice([0, 1], size=n_samples)
data = {
'Age': age,
'Income': income,
'Gender': gender,
'Education': education,
'Target': target
}
df = pd.DataFrame(data)
# 将分类变量转换为哑变量
df = pd.get_dummies(df, columns=['Gender', 'Education'])
# 定义特征和目标变量
X = df.drop('Target', axis=1)
y = df['Target']
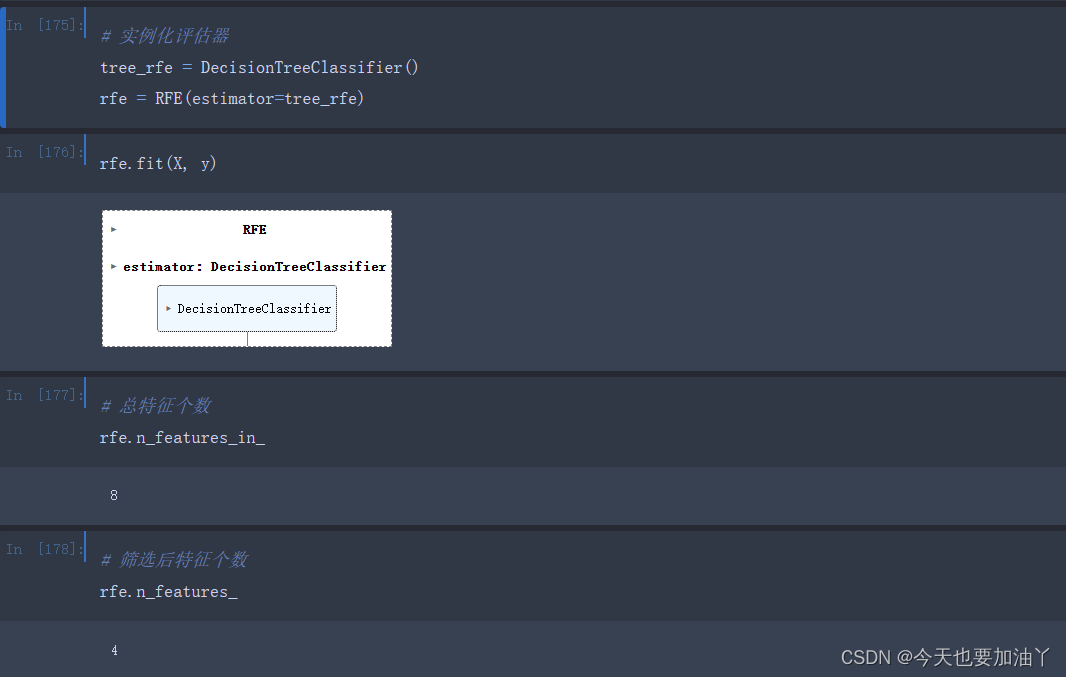


基于RFE计算过程的特征筛选
我们知道,只有模型本身有效,模型产出的feature_importances_才具有可信度。RFE过程尽管会用到feature_importances_进行特征筛选,但RFE过程只是对模型进行简单训练,并未进行超参数搜索等模型优化,这会使得每一轮的模型都是过拟合的,而基于过拟合模型产出的feature_importances_进行的特征筛选,结果并不可靠。此处设置n_features_to_select=1,最终会剔除到只剩一个特征:
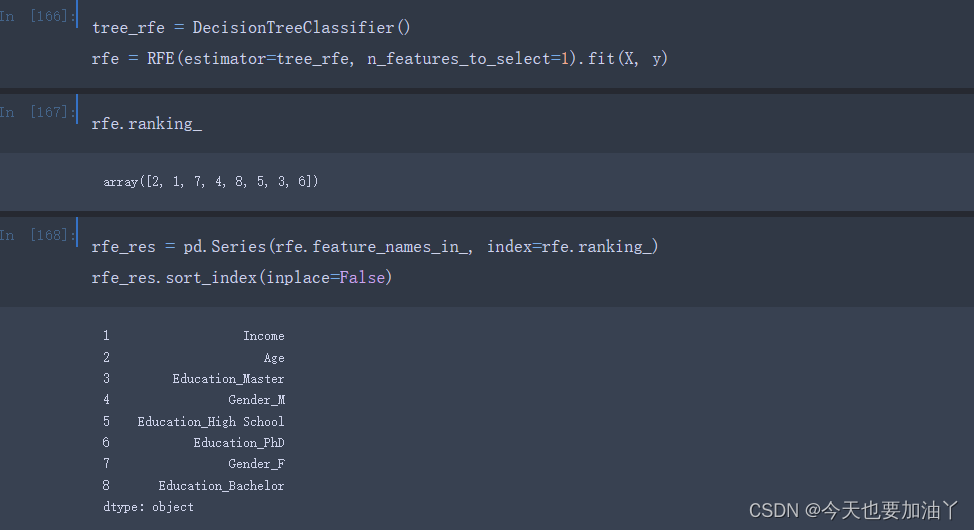
要解决该问题,sklearn提供了一个非常便捷的方法,即在实例化RFE评估器时带入一个已经经过网格搜索调参后的模型,即可每一轮特征重要性评估时使用已经训练好的模型,而该模型是已经经过剪枝的决策树模型,不会再表现出过拟合倾向。
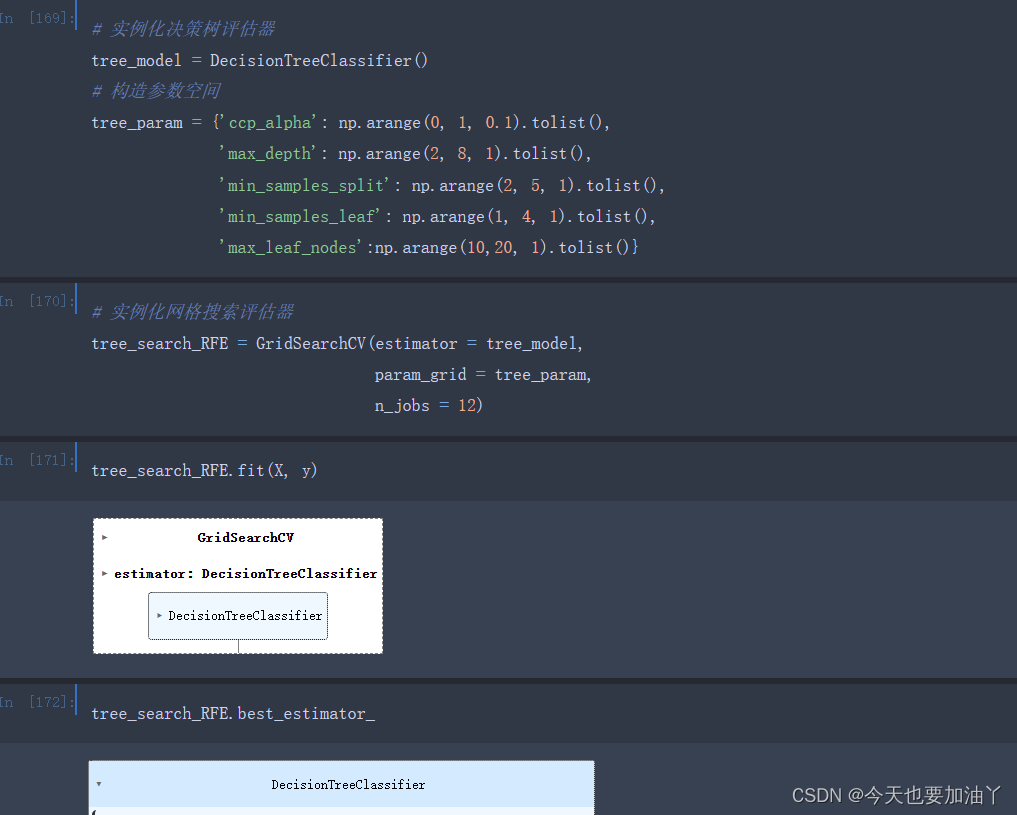
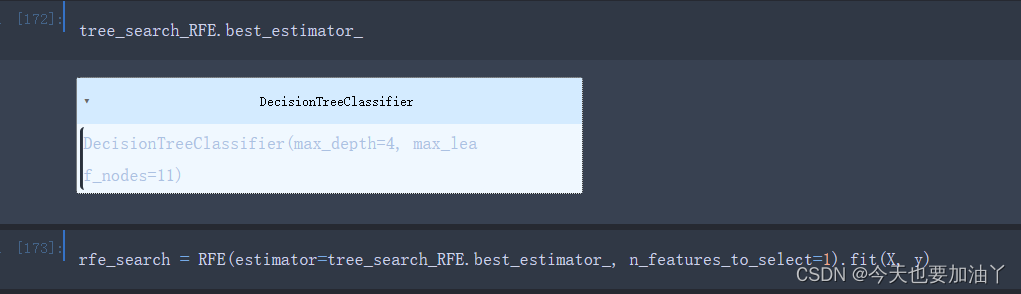
更加严谨的话,在RFE剔除一个特征后,然后利用特征子集训练一个最优超参数搜索后的决策树,然后再将这个模型带入下次RFE特征搜索。
# 定义参数空间
tree_param = {'ccp_alpha': np.arange(0, 1, 0.1).tolist(),
'max_depth': np.arange(2, 8, 1).tolist(),
'min_samples_split': np.arange(2, 5, 1).tolist(),
'min_samples_leaf': np.arange(1, 4, 1).tolist(),
'max_leaf_nodes':np.arange(10,20, 1).tolist()}
# 创建容器
rfe_res_search1 = []
# 执行循环
for i in tqdm(range(18)):#总共循环了18次、依次剔除了最不重要的18个特征
i = 18 - i
# 实例化网格搜索评估器
tree_model = DecisionTreeClassifier()
tree_search_RFE = GridSearchCV(estimator = tree_model,
param_grid = tree_param,
n_jobs = 12)
# 首次循环时,创建X_train_temp
if i == 18:
X_train_temp = (X_train_OE).copy()
# 训练模型,然后带入RFE评估器
tree_search_RFE.fit(X_train_temp, y_train)
rfe_search = RFE(estimator=tree_search_RFE.best_estimator_, n_features_to_select=i).fit(X_train_temp, y_train)
X_train_temp = X_train_OE[rfe_search.get_feature_names_out()]
# 搜索本轮被淘汰的特征,并记入rfe_res_search1
rfe_res_search1.append(rfe_search.feature_names_in_[rfe_search.ranking_ != 1])
# 清除临时变量
gc.collect()















 4019
4019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









