







#1.8为自编码器计算图添加标量,图像等汇总节点
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.examples.tutorials.mnist import input_data
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
#控制训练过程的参数
learning_rate = 0.01
training_epochs = 20
batch_size = 256
display_step = 1
examples_to_show = 10
#网络模型参数
n_hidden1_units = 256 #编码器第一隐藏层神经元数量(让编码器和解码器都有同样规模的隐藏层)
n_hidden2_units = 128 #编码器第二隐藏层神经元数量(让编码器和解码器都有同样规模的隐藏层)
n_input_units = 784 #输入层神经元数量MNIST data input(img shape :28*28)
n_output_units = n_input_units #解码器输出晨神经元数量必须等于输入数据的units数量
#对一个张量进行全面的汇总(均值,标准差,最大最小值,直方图)
#用于TensorBoard可视化
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean',mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var-mean)))
tf.summary.scalar('stddev',stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)
#根据输入输出节点数量返回初始化好的指定名称的权重Variable
def WeightsVariable(n_in,n_out,name_str):
return tf.Variable(tf.random_normal([n_in,n_out]),dtype=tf.float32,name=name_str)
#根据输出节点数量返回初始化好的指定名称的偏置Variable
def BiasesVariable(n_out,name_str):
return tf.Variable(tf.random_normal([n_out]),dtype=tf.float32,name=name_str)
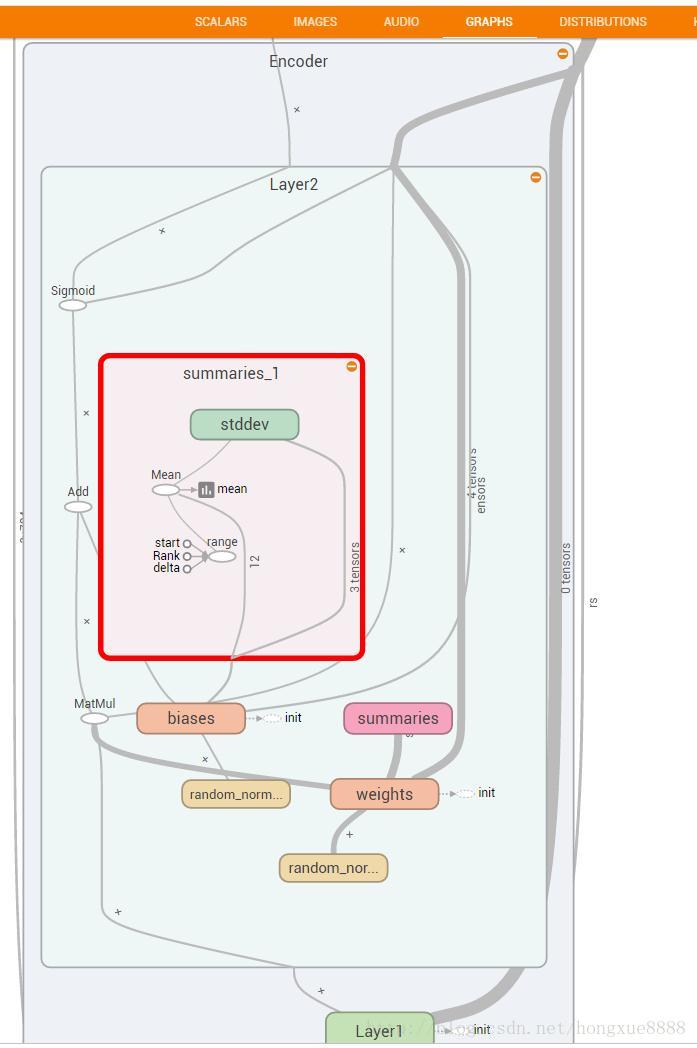
#构建编码器
def Encoder(x_origin,activate_func=tf.nn.sigmoid):
#编码器第一隐藏层
with tf.name_scope('Layer1'):
weights = WeightsVariable(n_input_units,n_hidden1_units,'weights')
biases = BiasesVariable(n_hidden1_units,'biases')
x_code1 = activate_func(tf.add(tf.matmul(x_origin,weights),biases))
# 编码器第二隐藏层
with tf.name_scope('Layer2'):
weights = WeightsVariable(n_hidden1_units, n_hidden2_units, 'weights')
biases = BiasesVariable(n_hidden2_units, 'biases')
x_code2 = activate_func(tf.add(tf.matmul(x_code1, weights), biases))
variable_summaries(weights)
variable_summaries(biases)
return x_code2
#构建解码器
def Decoder(x_code,activate_func):
#解码器第一隐藏层
with tf.name_scope('Layer1'):
weights = WeightsVariable(n_hidden2_units, n_hidden1_units, 'weights')
biases = BiasesVariable(n_hidden1_units, 'biases')
x_decode1 = activate_func(tf.add(tf.matmul(x_code, weights), biases))
# 解码器第二隐藏层
with tf.name_scope('Layer2'):
weights = WeightsVariable(n_hidden1_units, n_output_units, 'weights')
biases = BiasesVariable(n_output_units, 'biases')
x_decode2 = activate_func(tf.add(tf.matmul(x_decode1, weights), biases))
variable_summaries(weights)
variable_summaries(biases)
return x_decode2
#调用上面写的函数构造计算图
with tf.Graph().as_default():
#计算图输入
with tf.name_scope('X_origin'):
X_Origin = tf.placeholder(tf.float32,[None,n_input_units])
#构建编码器模型
with tf.name_scope('Encoder'):
X_code = Encoder(X_Origin,activate_func=tf.nn.sigmoid)
# 构建解码器模型
with tf.name_scope('Decoder'):
X_decode = Decoder(X_code,activate_func=tf.nn.sigmoid)
# 定义损失节点:重构数据与原始数据的误差平方和损失
with tf.name_scope('Loss'):
Loss = tf.reduce_mean(tf.pow(X_Origin - X_decode , 2))
# 定义优化器,训练节点
with tf.name_scope('Train'):
Optimizer = tf.train.RMSPropOptimizer(learning_rate)
Train = Optimizer.minimize(Loss)
# 为计算图添加损失节点的标量汇总(scalar summary)
with tf.name_scope('LossSummary'):
tf.summary.scalar('loss',Loss)
tf.summary.scalar('learning_rate', learning_rate)
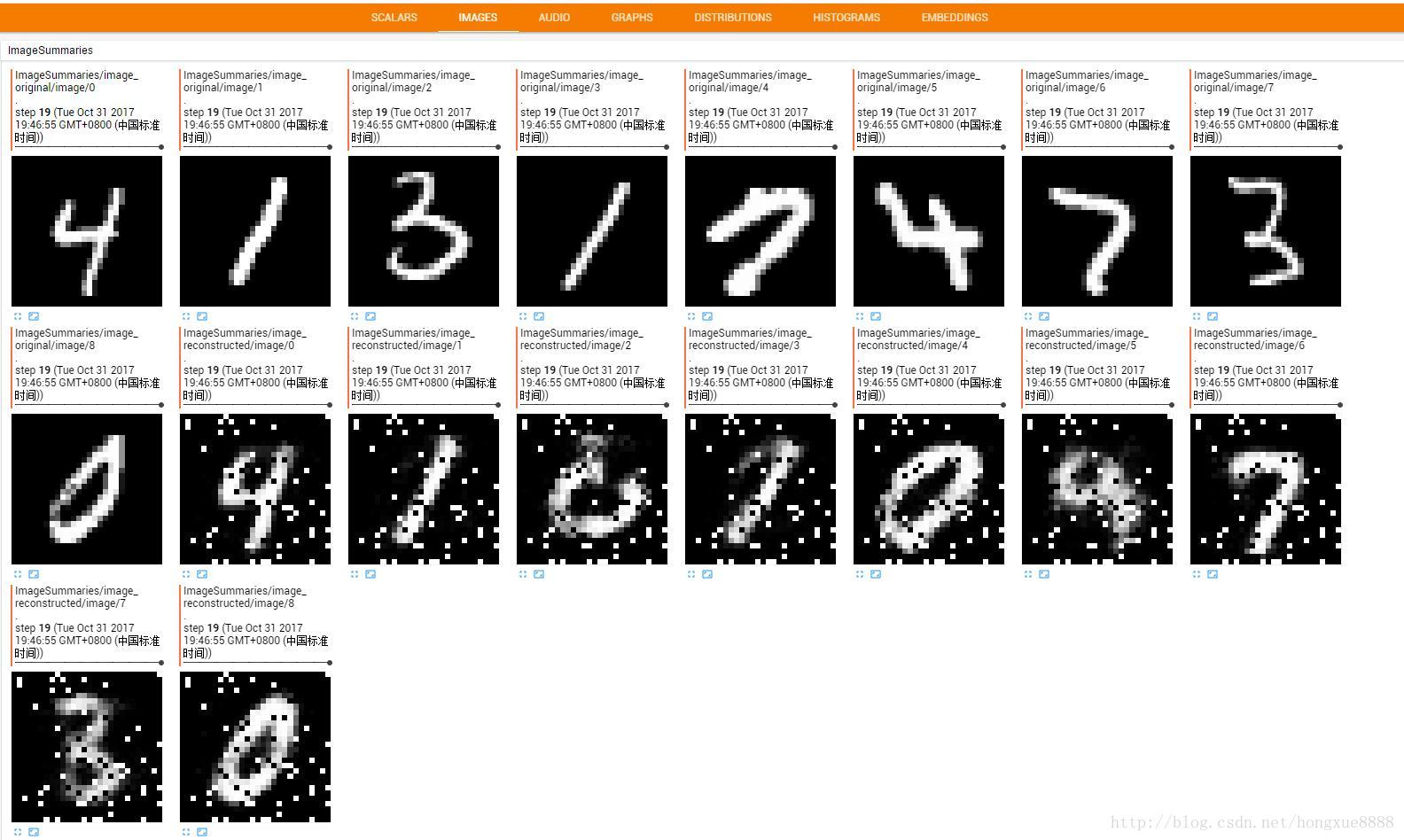
# 为计算图添加图像汇总(image summary)
with tf.name_scope('ImageSummaries'):
image_original = tf.reshape(X_Origin,[-1,28,28,1])
image_reconstructed = tf.reshape(X_decode,[-1,28,28,1])
tf.summary.image('image_original', image_original,9)
tf.summary.image('image_reconstructed', image_reconstructed,9)
#聚合所有汇总节点
merged_summaries = tf.summary.merge_all()
# 为所有变量添加初始化节点
Init = tf.global_variables_initializer()
print('把计算图写入事件文件,在Tesorboard里面查看')
summary_write = tf.summary.FileWriter(logdir='logs',graph=tf.get_default_graph())
summary_write.flush()
# 读取数据集
mnist = input_data.read_data_sets('MNIST_data/', one_hot=True)
with tf.Session() as sess:
sess.run(Init)
total_batch = int(mnist.train.num_examples / batch_size)
# 训练指定轮数,每一轮包含若干个批次
for epoch in range(training_epochs):
#每一轮(回合)都要把所有batch跑一遍
for i in range(total_batch):
batch_xs ,batch_ys = mnist.train.next_batch(batch_size)
#运行优化器Train节点(backprop)和Loss节点(获取损失值)
_,loss = sess.run([Train,Loss],feed_dict={X_Origin:batch_xs})
#每一轮训完之后,输出logs
if epoch % display_step == 0:
print("Epoch:",'%04d' % (epoch + 1),"Loss=","{:.9f}".format(loss))
#调用sess.run()方法运行汇总节点,更新事件文件
summary_str = sess.run(merged_summaries,feed_dict={X_Origin:batch_xs})
summary_write.add_summary(summary_str,epoch)
summary_write.flush()
#关闭summary_write
summary_write.close()
print("模型训练完毕")
#把训练好的编码器-解码器模型用在测试集上,输出重建后的样本数据
reconstructions = sess.run(X_decode,feed_dict={X_Origin:mnist.test.images[:examples_to_show]})
#比较原始图像与重建后的图像
f,a = plt.subplots(2,10,figsize=(10,2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i],(28,28)))
a[1][i].imshow(np.reshape(reconstructions[i],(28,28)))
f.show()
plt.draw()
plt.waitforbuttonpress()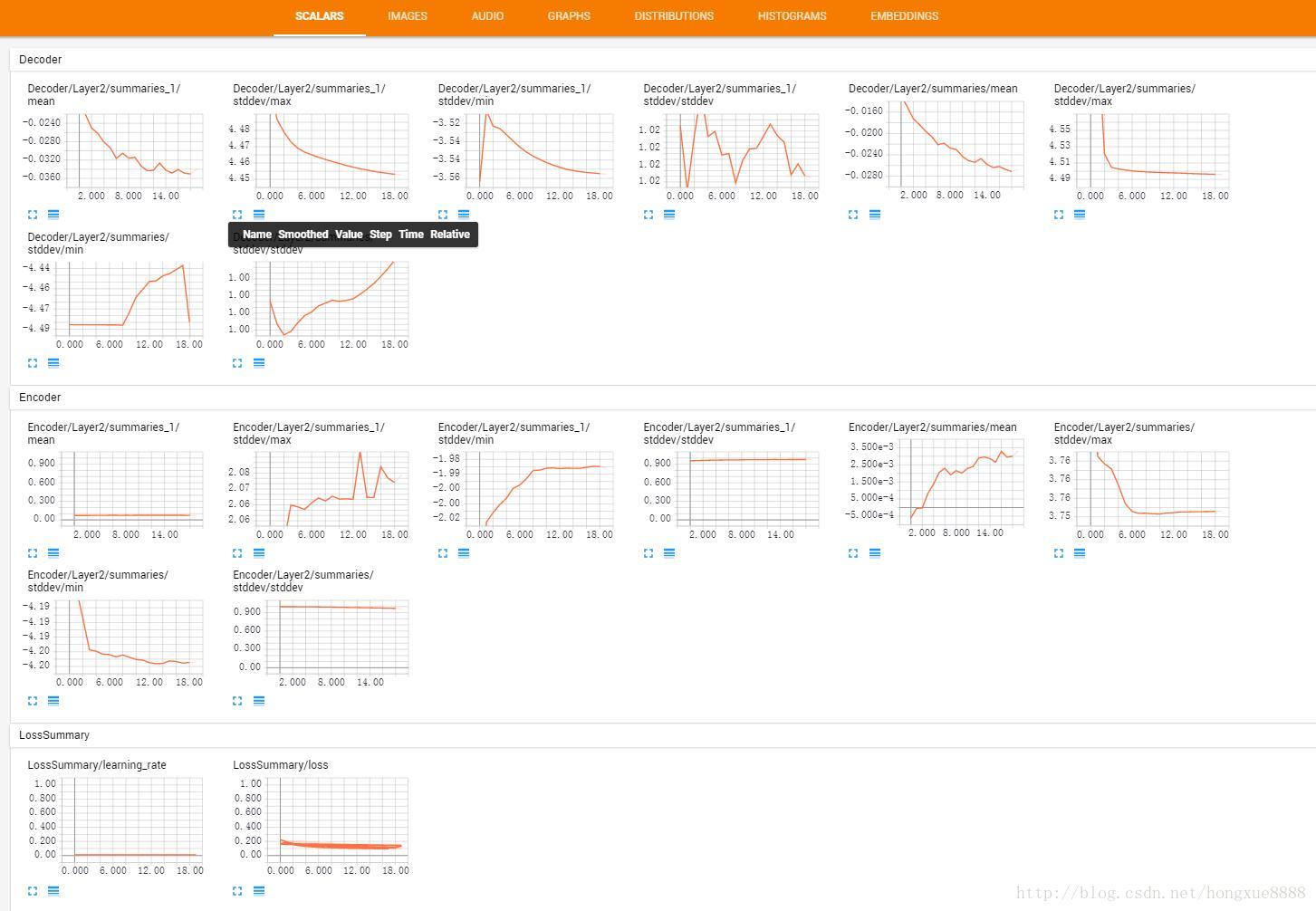















 4965
4965
03-08
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









