







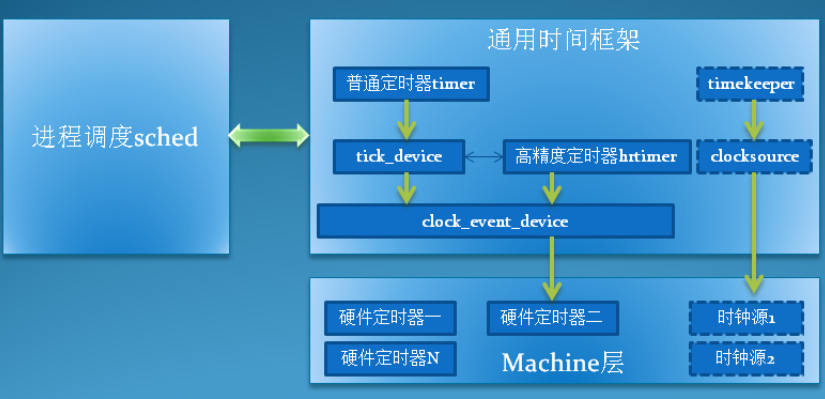
时钟源(clock source)
clock source顾名思义就是提供给系统提供时钟的时钟源。
clock source负责读取芯片中按时间增加的值(所谓cycle),并提供给timekeeper,当然也要提供按cycle的值计算时间间隔的内容。
clocksource以及timer相关的内容都在kernel/kernel/time目录下面。
obj-y += timekeeping.o ntp.o clocksource.o jiffies.o timer_list.o
obj-y += timeconv.o posix-clock.o alarmtimer.o
obj-$(CONFIG_GENERIC_CLOCKEVENTS_BUILD) += clockevents.o
obj-$(CONFIG_GENERIC_CLOCKEVENTS) += tick-common.o
obj-$(CONFIG_GENERIC_CLOCKEVENTS_BROADCAST) += tick-broadcast.o tick-broadcast-hrtimer.o
obj-$(CONFIG_GENERIC_SCHED_CLOCK) += sched_clock.o
obj-$(CONFIG_TICK_ONESHOT) += tick-oneshot.o
obj-$(CONFIG_TICK_ONESHOT) += tick-sched.o
obj-$(CONFIG_TIMER_STATS) += timer_stats.o下面来看一下时钟源是怎么注册上去,怎么提供计算时间的内容给timekeeper。
1. 时钟源注册过程:
linux可以有很多时钟源,其中一种时钟源是jiffies。还有就是平台相关的时钟源,精度较高。
当然在注册了很多种时钟源之后,linux内核也用某种方式去选择当前的时钟源来保证最好的精度。
1)jiffies时钟源注册过程:
jiffies我们知道就是一秒钟会增加相当于HZ大小的一个变量。
首先需要根据时钟源,填充clocksource相关数据结构中的成员。
static struct clocksource clocksource_jiffies = {
.name= "jiffies",
.rating= 1,
.read= jiffies_read, /*读取当前jiffies*/
.mask= 0xffffffff, /*32bits*/
.mult= NSEC_PER_JIFFY << JIFFIES_SHIFT, /* details above */
.shift= JIFFIES_SHIFT,
}; 从这个例子,可以看出来 (mult>>shift)*cloclsource->read() 这个读的就是jiffies数。
当然如果要注册一些更高精度的时钟源,mult和shift要进行小心的计算,以保证其值不会溢出。这个后面再看。
2. 平台相关的时钟源
int clocksource_register(struct clocksource *cs)
{
/* calculate max adjustment for given mult/shift */
cs->maxadj = clocksource_max_adjustment(cs); /*计算相当于mult值得11%赋给maxadj*/
/* calculate max idle time permitted for this clocksource */
cs->max_idle_ns = clocksource_max_deferment(cs); /*max_idle_ns计算方法看下面*/
mutex_lock(&clocksource_mutex);
clocksource_enqueue(cs); //把注册的clock source 添加到clocksource_list链表中,按rate的降序排序
clocksource_enqueue_watchdog(cs);
clocksource_select(); //按rate选择最佳的clocksource,当然这里rate哪个大就选哪
个,,
mutex_unlock(&clocksource_mutex);
return 0;
}
static u64 clocksource_max_deferment(struct clocksource *cs)
{
u64 max_nsecs, max_cycles;
max_cycles = 1ULL << (63 - (ilog2(cs->mult + cs->maxadj) + 1));
/* 上面的计算出来就是2的63次方 = max_cycles*(cs->mult + cs->maxadj) ,也就是说
这个是在计算2的63次方纳秒对应的cycles,也就是计算最大的cycles,因为时间对应的纳秒不能超
过2的64次方,因为会溢出
*/
max_cycles = min_t(u64, max_cycles, (u64) cs->mask);
/*max_cycles和cs->mask中的最小值赋值给max_cycles*/
max_nsecs = clocksource_cyc2ns(max_cycles, cs->mult - cs->maxadj,
cs->shift);
return max_nsecs - (max_nsecs >> 3);
}
static struct clocksource clocksource_counter = {
.name = "arch_sys_counter",
.rating = 400,
.read = arch_counter_read,
.mask = CLOCKSOURCE_MASK(56),
.flags = CLOCK_SOURCE_IS_CONTINUOUS,
};
static void __init arch_timer_counter_init(void)
{
clocksource_register_hz(&clocksource_counter, arch_timer_rate);
setup_sched_clock(arch_timer_update_sched_clock, 32, arch_timer_rate);
/* Use the architected timer for the delay loop. */
arch_delay_timer.read_current_timer = &arch_timer_read_current_timer;
arch_delay_timer.freq = arch_timer_rate;
register_current_timer_delay(&arch_delay_timer);
}
static inline int clocksource_register_hz(struct clocksource *cs, u32 hz)
{
return __clocksource_register_scale(cs, 1, hz);
}
int __clocksource_register_scale(struct clocksource *cs, u32 scale, u32 freq)
{
/* Initialize mult/shift and max_idle_ns */
__clocksource_updatefreq_scale(cs, scale, freq); //根据clocksource的频
率计算mult和shit的值
/* Add clocksource to the clcoksource list */
mutex_lock(&clocksource_mutex);
clocksource_enqueue(cs);
clocksource_enqueue_watchdog(cs);
clocksource_select();
mutex_unlock(&clocksource_mutex);
return 0;
}
void __clocksource_updatefreq_scale(struct clocksource *cs, u32 scale, u32 freq)
{
u64 sec;
sec = (cs->mask - (cs->mask >> 3));
do_div(sec, freq);
do_div(sec, scale);
if (!sec)
sec = 1;
else if (sec > 600 && cs->mask > UINT_MAX)
sec = 600;
clocks_calc_mult_shift(&cs->mult, &cs->shift, freq,
NSEC_PER_SEC / scale, sec * scale);
cs->maxadj = clocksource_max_adjustment(cs);
while ((cs->mult + cs->maxadj < cs->mult)
|| (cs->mult - cs->maxadj > cs->mult)) {
cs->mult >>= 1;
cs->shift--;
cs->maxadj = clocksource_max_adjustment(cs);
}
cs->max_idle_ns = clocksource_max_deferment(cs);
}
void
clocks_calc_mult_shift(u32 *mult, u32 *shift, u32 from, u32 to, u32 maxsec)
{
u64 tmp;
u32 sft, sftacc= 32;
tmp = ((u64)maxsec * from) >> 32;
while (tmp) {
tmp >>=1;
sftacc--;
}
for (sft = 32; sft > 0; sft--) {
tmp = (u64) to << sft;
tmp += from / 2;
do_div(tmp, from);
if ((tmp >> sftacc) == 0)
break;
}
*mult = tmp;
*shift = sft;
}
kernel用乘法+移位来替换除法:根据cycles来计算过去了多少ns。
单纯从精度上讲,肯定是mult越大越好,但是计算过程可能溢出,所以mult也不能无限制的大,这个计算中有个magic number 600 :
这个600的意思是600秒,表示的Timer两次计算当前计数值的差不会超过10分钟。主要考虑的是系统进入IDLE状态之后,时间信息不会被更新,10分钟内只要退出IDLE,clocksource还是可以成功的转换时间。当然了,最后的这个时间不一定就是10分钟,它由clocksource_max_deferment计算并将结果存储在max_idle_ns中
筒子比较关心的问题是如何计算 ,精度如何,其实我不太喜欢这种计算,Kernel总是因为某些原因把代码写的很蛋疼.反正揣摩代码意图要花不少时间,收益嘛其实也不太大.如何实现我也不解释了,我以TSC为例子我评估下这种mult+shift的精度.
#include<stdio.h>
#include<stdlib.h>
typedef unsigned int u32;
typedef unsigned long long u64;
#define NSEC_PER_SEC 1000000000L
void
clocks_calc_mult_shift(u32 *mult, u32 *shift, u32 from, u32 to, u32 maxsec)
{
u64 tmp;
u32 sft, sftacc= 32;
/*
* * Calculate the shift factor which is limiting the conversion
* * range:
* */
tmp = ((u64)maxsec * from) >> 32;
while (tmp) {
tmp >>=1;
sftacc--;
}
/*
* * Find the conversion shift/mult pair which has the best
* * accuracy and fits the maxsec conversion range:
* */
for (sft = 32; sft > 0; sft--) {
tmp = (u64) to << sft;
tmp += from / 2;
//do_div(tmp, from);
tmp = tmp/from;
if ((tmp >> sftacc) == 0)
break;
}
*mult = tmp;
*shift = sft;
}
int main()
{
u32 tsc_mult;
u32 tsc_shift ;
u32 tsc_frequency = 2127727000/1000; //TSC frequency(KHz)
clocks_calc_mult_shift(&tsc_mult,&tsc_shift,tsc_frequency,NSEC_PER_SEC/1000,
600*1000); //NSEC_PER_SEC/1000是因为TSC的注册是clocksource_register_khz
fprintf(stderr,"mult = %d shift = %d\n",tsc_mult,tsc_shift);
return 0;
}600是根据TSC clocksource的MASK算出来的的入参,感兴趣可以自己推算看下结果:
mult = 7885042 shift = 24
root@manu:~/code/c/self/time# python
Python 2.7.3 (default, Apr 10 2013, 05:46:21)
[GCC 4.6.3] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> (2127727000*7885042)>>24
1000000045L
>>>
我们知道TSC的frequency是2127727000Hz,如果cycle走过2127727000,就意味过去了1秒,或者说10^9(us).按照我们的算法得出的时间是1000000045ns. 这个误差是多大呢,每走10^9秒,误差是45纳秒,换句话说,运行257天,产生1秒的计算误差.考虑到NTP的存在,这个运算精度还可以了.3. clocksource watchdog
clocksource_enqueue_watchdog会将clocksource挂到watchdog链表.watchdog顾名思义,监控所有clocksource:
#define WATCHDOG_INTERVAL (HZ >> 1)
#define WATCHDOG_THRESHOLD (NSEC_PER_SEC >> 4)如果0.5秒内,误差大于0.0625s,表示这个clocksource精度极差,将rating设成0.
实际的应用场景
以高通msm8916为例,除了jiffies,其他clocksource是没有直接使用kernel/kernel/time/clocksource.c文件里边的接口的。
其他arm_arch_timer.c[/kernel/driver/clocksource/arm_arch_timer.c]
和 arch_timer.c [kernel/arch/arm/kernel/arch_timer.c] 两个都是使用
sched_clock.c[/kernel/kernel/time/sched_clock.c]文件里边的
sched_clock_register()来进行注册,并使用sched_clock_32()函数读取当前时间。

















 1704
1704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









