







 本文围绕LDA模型在希拉里邮件分析中的应用展开。先介绍了模型构建所需的函数解析和辅助函数,如get_document_topics等。接着展示项目代码,包括导入训练数据、清理内容、进行人工分词、建立语料库等步骤,最后呈现了模型结果和测试部分结果。
本文围绕LDA模型在希拉里邮件分析中的应用展开。先介绍了模型构建所需的函数解析和辅助函数,如get_document_topics等。接着展示项目代码,包括导入训练数据、清理内容、进行人工分词、建立语料库等步骤,最后呈现了模型结果和测试部分结果。
1.知识准备
1.1 函数解析
class gensim.models.ldamodel.LdaModel(corpus=None, num_topics=100, id2word=None, distributed=False, chunksize=2000, passes=1, update_every=1, alpha='symmetric', eta=None, decay=0.5, offset=1.0, eval_every=10, iterations=50, gamma_threshold=0.001, minimum_probability=0.01, random_state=None, ns_conf=None, minimum_phi_value=0.01, per_word_topics=False, callbacks=None, dtype=<type 'numpy.float32'>)
- corpus:用该参数传入的文档语料将会被用来训练模型,如果不指定该参数,则不进行任何训练,默认后续会调用 update() 方法对模型语料进行更新
- num_topics:需要提取的潜在主题数
- id2word:用于设置构建模型的词典,决定了词汇数量,id2word = dictionary.id2token
- distributed:是否开启分布式计算
- chunksize:文件块大小,等同深度学习训练的batch,一次性给入2000篇文章,一次性给入越多,性能越好,该指标会略微影响最终结果
- passes:等同epoch,how often we train the model on the entire corpus.
- iterations:it controls how often we repeat a particular loop over each document. 跟passes相对,每篇文章的loop,其跟passes两个指标都很重要,若把这两个指标设置得足够高,会有好效果。
- alpha:决定文档主题狄利克雷先验分布的超参数,默认取值为对称 1.0/num_topics 先验,可以自行设置,也支持以下两种取值:
(1)‘asymmetric’ :固定的非对称 1.0/topicno 先验
(2) ‘auto’:根据实际数据学习得到的非对称先验 - eta:决定主题词汇狄利克雷先验分布的超参数,可以自行设置为对称的先验分布常量或者长度为词汇总数的向量作为非对称先验,此外也支持以下两种取值:
(1)‘auto’:根据实际数据学习得到的非对称先验
(2)形如 num_topics x num_words
的矩阵:为每一个主题都引入一个词汇非对称先验分布 - minimum_probability:用于限制返回一个文档主题的概率
- 利用random_state进行随机化设置
1.2辅助函数
get_document_topics 文章主题偏好
主函数:get_document_topics(bow, minimum_probability=None,minimum_phi_value=None, per_word_topics=False)
- minimum_probability:忽略概率小于该参数值的主题
- per_word_topics:取值为 True 时,同时按照可能性的降序返回词汇对应的主题
model.get_document_topics(corpus[0])
>>> [(1, 0.13500942), (3, 0.18280579), (4, 0.1801268), (7, 0.50190312)]
get_term_topics 单词的主题偏好
get_term_topics(word_id, minimum_probability=None)¶
get_term_topics 方法用于返回词典中指定词汇最有可能对应的主题,调用方式为:实例.get_term_topics(word_id, minimum_probability=None),
- word_id 即为指定词汇 id
- minimum_probability 为返回主题的最小概率限定
get_topic_terms以及get_topics 主题内容展示
model.get_topics()
get_topic_terms(topicid, topn=10)
输入主题号,返回重要词以及重要词概率
get_topic_terms 方法以(词汇 id,概率)的形式返回指定主题的重要词汇,调用方式为:get_topic_terms(topicid, topn=10)
- topicid 即为主题 id
- topn 为返回的词汇数
# 函数一
model.get_topic_terms(1, topn=10)
>>> [(774, 0.019700538013351386),
(3215, 0.0075965808303036916),
(3094, 0.0067132528809042526),
(514, 0.0063925849599646822),
(2739, 0.0054527647598129206),
(341, 0.004987335769043616),
(752, 0.0046566448210636699),
(1218, 0.0046234352422933724),
(186, 0.0042132891022475458),
(829, 0.0041800479706789939)]
# 函数二:
>>> array([[ 9.57974777e-05, 6.17130780e-07, 6.34938224e-07, ...,
6.17080048e-07, 6.19691132e-07, 6.17090716e-07],
[ 9.81065671e-05, 3.12945042e-05, 2.80837858e-04, ...,
7.86879291e-07, 7.86479617e-07, 7.86592758e-07],
[ 4.57734625e-05, 1.33555568e-05, 2.55108081e-05, ...,
5.31796854e-07, 5.32000122e-07, 5.31934336e-07],
print_topic以及print_topics
- model.print_topic(1, topn=10)
- print_topics(num_topics=20, num_words=10)
# 函数一
model.print_topic(1, topn=10)
>>> '0.025*"image" + 0.010*"object" + 0.008*"distance" + 0.007*"recognition" + 0.005*"pixel" + 0.004*"cluster" + 0.004*"class" + 0.004*"transformation" + 0.004*"constraint" + 0.004*"map"'
# 函数二
model.print_topics(num_topics=20, num_words=10)
[(0,
'0.008*"gaussian" + 0.007*"mixture" + 0.006*"density" + 0.006*"matrix" + 0.006*"likelihood" + 0.005*"noise" + 0.005*"component" + 0.005*"prior" + 0.005*"estimate" + 0.004*"log"'),
(1,
'0.025*"image" + 0.010*"object" + 0.008*"distance" + 0.007*"recognition" + 0.005*"pixel" + 0.004*"cluster" + 0.004*"class" + 0.004*"transformation" + 0.004*"constraint" + 0.004*"map"'),
(2,
'0.011*"visual" + 0.010*"cell" + 0.009*"response" + 0.008*"field" + 0.008*"motion" + 0.007*"stimulus" + 0.007*"direction" + 0.005*"orientation" + 0.005*"eye" + 0.005*"frequency"')]
show_topic以及show_topics
- model.show_topic(topicid, topn=10)
输入主题号,得到每个主题哪些重要词+重要词概率
- model.show_topics(num_topics=10, num_words=10, log=False,
formatted=True)
每个主题下,重要词等式
show_topic(topicid, topn=10)
>>> [('action', 0.013790729946622874),
('control', 0.013754026606322274),
('policy', 0.010037394726575378),
('q', 0.0087439205722043382),
('reinforcement', 0.0087102831394097746),
('optimal', 0.0074764680531377312),
('robot', 0.0057665635437760083),
('controller', 0.0053787501576589725)]
# second
model.show_topics(num_topics=10)
>>> [(0,
'0.014*"action" + 0.014*"control" + 0.010*"policy" + 0.009*"q" + 0.009*"reinforcement" + 0.007*"optimal" + 0.006*"robot" + 0.005*"controller" + 0.005*"dynamic" + 0.005*"environment"'),
(1,
'0.020*"image" + 0.008*"face" + 0.007*"cluster" + 0.006*"signal" + 0.005*"source" + 0.005*"matrix" + 0.005*"filter" + 0.005*"search" + 0.004*"distance" + 0.004*"o_o"')]
2.项目代码, 结果以及注释展示《LDA模型应用:一眼看穿希拉里的邮件》
2.1导入训练数据
df = pd.read_csv("../input/HillaryEmails.csv")
# 原邮件数据中有很多Nan的值,直接扔了。
df = df[['Id','ExtractedBodyText']].dropna()
链接:https://pan.baidu.com/s/1NDIC3jXozW25B3_SdE8oSw
提取码:98ms
复制这段内容后打开百度网盘手机App,操作更方便哦
2.2构建文件内容清理函数, 取出无关的信息
def clean_email_text(text):
text = text.replace('\n'," ") #新行,我们是不需要的
text = re.sub(r"-", " ", text) #把 "-" 的两个单词,分开。(比如:july-edu ==> july edu)
text = re.sub(r"\d+/\d+/\d+", "", text) #日期,对主体模型没什么意义
text = re.sub(r"[0-2]?[0-9]:[0-6][0-9]", "", text) #时间,没意义
text = re.sub(r"[\w]+@[\.\w]+", "", text) #邮件地址,没意义
text = re.sub(r"/[a-zA-Z]*[:\//\]*[A-Za-z0-9\-_]+\.+[A-Za-z0-9\.\/%&=\?\-_]+/i", "", text) #网址,没意义
pure_text = ''
# 以防还有其他特殊字符(数字)等等,我们直接把他们loop一遍,过滤掉
for letter in text:
# 只留下字母和空格
if letter.isalpha() or letter==' ':
pure_text += letter
# 再把那些去除特殊字符后落单的单词,直接排除。
# 我们就只剩下有意义的单词了。
text = ' '.join(word for word in pure_text.split() if len(word)>1)
return text
2.3进行lda建模
LDA模型构建:
好,我们用Gensim来做一次模型构建
首先,我们得把我们刚刚整出来的一大波文本数据
- [[一条邮件字符串],[另一条邮件字符串], …]
转化成Gensim认可的语料库形式:
- [[一,条,邮件,在,这里],[第,二,条,邮件,在,这里],[今天,天气,肿么,样],…]
2.3.1 引入库和自定义的停止词
from gensim import corpora, models, similarities
import gensim
stoplist = ['very', 'ourselves', 'am', 'doesn', 'through', 'me', 'against', 'up', 'just', 'her', 'ours',
'couldn', 'because', 'is', 'isn', 'it', 'only', 'in', 'such', 'too', 'mustn', 'under', 'their',
'if', 'to', 'my', 'himself', 'after', 'why', 'while', 'can', 'each', 'itself', 'his', 'all', 'once',
'herself', 'more', 'our', 'they', 'hasn', 'on', 'ma', 'them', 'its', 'where', 'did', 'll', 'you',
'didn', 'nor', 'as', 'now', 'before', 'those', 'yours', 'from', 'who', 'was', 'm', 'been', 'will',
'into', 'same', 'how', 'some', 'of', 'out', 'with', 's', 'being', 't', 'mightn', 'she', 'again', 'be',
'by', 'shan', 'have', 'yourselves', 'needn', 'and', 'are', 'o', 'these', 'further', 'most', 'yourself',
'having', 'aren', 'here', 'he', 'were', 'but', 'this', 'myself', 'own', 'we', 'so', 'i', 'does', 'both',
'when', 'between', 'd', 'had', 'the', 'y', 'has', 'down', 'off', 'than', 'haven', 'whom', 'wouldn',
'should', 've', 'over', 'themselves', 'few', 'then', 'hadn', 'what', 'until', 'won', 'no', 'about',
'any', 'that', 'for', 'shouldn', 'don', 'do', 'there', 'doing', 'an', 'or', 'ain', 'hers', 'wasn',
'weren', 'above', 'a', 'at', 'your', 'theirs', 'below', 'other', 'not', 're', 'him', 'during', 'which']
2.3.2进行人工分词
这里,英文的分词,直接就是对着空白处分割就可以了。
中文的分词稍微复杂点儿,具体可以百度:CoreNLP, HaNLP, 结巴分词,等等
分词的意义在于,把我们的长长的字符串原文本,转化成有意义的小元素:
texts = [[word for word in doc.lower().split() if word not in stoplist] for doc in doclist]
2.4建立语料库
用词袋的方法, 将每一个词用一个数字index来进行映射, 通过将原数据中的单词进行映射, 将原数据映射成一条长长的数字组成的数组
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
- 建立模型
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
2.5给出模型构建部分的全部代码
import numpy as np
import pandas as pd
import re
#读入数据
df = pd.read_csv("../input/HillaryEmails.csv")
# 原邮件数据中有很多Nan的值,直接扔了。
df = df[['Id','ExtractedBodyText']].dropna()
#文本清洗函数
def clean_email_text(text):
text = text.replace('\n'," ") #新行,我们是不需要的
text = re.sub(r"-", " ", text) #把 "-" 的两个单词,分开。(比如:july-edu ==> july edu)
text = re.sub(r"\d+/\d+/\d+", "", text) #日期,对主体模型没什么意义
text = re.sub(r"[0-2]?[0-9]:[0-6][0-9]", "", text) #时间,没意义
text = re.sub(r"[\w]+@[\.\w]+", "", text) #邮件地址,没意义
text = re.sub(r"/[a-zA-Z]*[:\//\]*[A-Za-z0-9\-_]+\.+[A-Za-z0-9\.\/%&=\?\-_]+/i", "", text) #网址,没意义
pure_text = ''
# 以防还有其他特殊字符(数字)等等,我们直接把他们loop一遍,过滤掉
for letter in text:
# 只留下字母和空格
if letter.isalpha() or letter==' ':
pure_text += letter
# 再把那些去除特殊字符后落单的单词,直接排除。
# 我们就只剩下有意义的单词了。
text = ' '.join(word for word in pure_text.split() if len(word)>1)
return text
#原始数据进行清洗
docs = df['ExtractedBodyText']
docs = docs.apply(lambda s: clean_email_text(s))
doclist = docs.values
#导入建模库
from gensim import corpora, models, similarities
import gensim
#导入自定义停用词
stoplist = ['very', 'ourselves', 'am', 'doesn', 'through', 'me', 'against', 'up', 'just', 'her', 'ours',
'couldn', 'because', 'is', 'isn', 'it', 'only', 'in', 'such', 'too', 'mustn', 'under', 'their',
'if', 'to', 'my', 'himself', 'after', 'why', 'while', 'can', 'each', 'itself', 'his', 'all', 'once',
'herself', 'more', 'our', 'they', 'hasn', 'on', 'ma', 'them', 'its', 'where', 'did', 'll', 'you',
'didn', 'nor', 'as', 'now', 'before', 'those', 'yours', 'from', 'who', 'was', 'm', 'been', 'will',
'into', 'same', 'how', 'some', 'of', 'out', 'with', 's', 'being', 't', 'mightn', 'she', 'again', 'be',
'by', 'shan', 'have', 'yourselves', 'needn', 'and', 'are', 'o', 'these', 'further', 'most', 'yourself',
'having', 'aren', 'here', 'he', 'were', 'but', 'this', 'myself', 'own', 'we', 'so', 'i', 'does', 'both',
'when', 'between', 'd', 'had', 'the', 'y', 'has', 'down', 'off', 'than', 'haven', 'whom', 'wouldn',
'should', 've', 'over', 'themselves', 'few', 'then', 'hadn', 'what', 'until', 'won', 'no', 'about',
'any', 'that', 'for', 'shouldn', 'don', 'do', 'there', 'doing', 'an', 'or', 'ain', 'hers', 'wasn',
'weren', 'above', 'a', 'at', 'your', 'theirs', 'below', 'other', 'not', 're', 'him', 'during', 'which']
#对处理后的数据进行去停用词和分词
texts = [[word for word in doc.lower().split() if word not in stoplist] for doc in doclist]
#利用词袋模型建立语料库
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
#建立lda模型
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=20)
2.6 lda模型结果展示部分
- 展示第10号分类中最常出现的5个词的两种方式
lda.print_topic(10, topn=5)
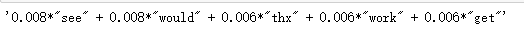
#以指定分类号显示最常出现的5个词和概率的形式展示, 不是前面的相乘形式
lda.show_topic(10, topn = 5)

- 展示指定多个数量分类下的常见单词数量和概率的两种方式
#指定输出随意10个分类中常出现的5个词
lda.print_topics(num_topics=10, num_words=5)

#这个和前面的形式一样
lda.show_topics(num_topics = 10, num_words = 5)

- 展示所有分类下的指定数量的常见单词的一种方法
#展示每个分类中最常出现的5个单词
lda.print_topics(num_words=5)

2.7测试部分结果展示, 包括数据的初始化等操作

- 此为测试数据, 单独形成一个txt形式的文件, 导入到程序中即可
#测试数据的初始化操作
with open("test.txt", "r") as f:
data = f.read()
data = data.split("\n\n")
text_data = pd.DataFrame(data, columns = ["data", ])
text_data = text_data["data"]
text_data = text_data.apply(lambda s:clean_email_text(s))
doclist = text_data.values
text_data = [[word for word in doc.lower().split() if word not in stoplist] for doc in doclist]
text_data = [dictionary.doc2bow(text) for text in text_data]

- 使用get_document_topics 文章主题偏好函数, 查看各个数据对应原始训练数据中的哪个分类的概率
result = [lda.get_document_topics(text) for text in text_data]
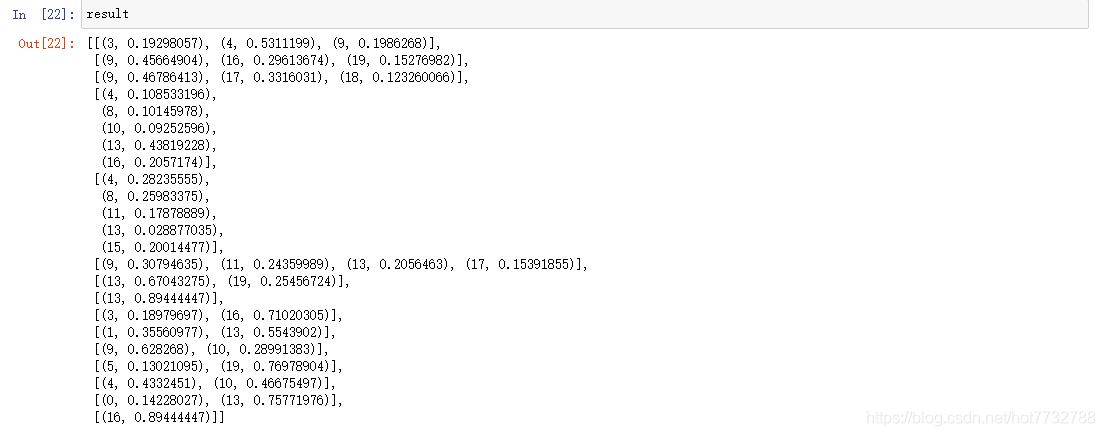
- 使用get_term_topics 单词的主题偏好判断某个单词是属于哪个分类的概率(已有映射的单词)–注意后面参数是概率阈值, 有时概率都很小就不会显示出来了, 此时将阈值降低即可
lda.get_term_topics(1, minimum_probability = 0)#单词的没成功, 后面是最小概率的限定, 小于后面的值就不返回了


















 1514
1514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









