







一、简介
Kafka是一款开源的、轻量级的、分布式、可分区和具有复制备份的(Replicated)、基于ZooKeeper协调管理的分布式流平台的功能强大的发布—订阅消息系统。据Kafka官方网站介绍,当前的Kafka已经定位为一个分布式流式处理平台(a distributed streaming platform),它最初由LinkedIn公司开发,后来成为Apache项目的一部分。
作为一个消息系统,其基本结构中至少要有产生消息的组件(消息生产者,Producer)以及消费消息的组件(消费者,Consumer)。生产者负责生产消息,将消息写入Kafka集群;消费者从Kafka集群中拉取消息。
二、核心概念
1、主题
Kafka将一组消息抽象归纳为一个主题(Topic),也就是说,一个主题就是对消息的一个分类。生产者将消息发送到特定主题,消费者订阅主题或主题的某些分区进行消费。
2、消息
消息是Kafka通信的基本单位,由一个固定长度的消息头和一个可变长度的消息体构成。
3、分区和副本
Kafka将一组消息归纳为一个主题,而每个主题又被分成一个或多个分区(Partition)。每个分区由一系列有序、不可变的消息组成,是一个有序队列。
每个分区在物理上对应为一个文件夹,分区的命名规则为主题名称后接“—”连接符,之后再接分区编号,分区编号从0开始,编号最大值为分区的总数减1。每个分区又有一至多个副本(Replica),分区的副本分布在集群的不同代理上,以提高可用性。从存储角度上分析,分区的每个副本在逻辑上抽象为一个日志(Log)对象,即分区的副本与日志对象是一一对应的。每个主题对应的分区数可以在Kafka启动时所加载的配置文件中配置,也可以在创建主题时指定。
Kafka只能保证一个分区之内消息的有序性,并不能保证跨分区消息的有序性。
4、Leader副本和Follower副本
Kafka会选择该分区的一个副本作为Leader副本,而该分区其他副本即为Follower副本,只有Leader副本才负责处理客户端读/写请求,Follower副本从Leader副本同步数据。
5、偏移量
任何发布到分区的消息会被直接追加到日志文件(分区目录下以“.log”为文件名后缀的数据文件)的尾部,而每条消息在日志文件中的位置都会对应一个按序递增的偏移量。偏移量是一个分区下严格有序的逻辑值,它并不表示消息在磁盘上的物理位置。
6、日志段
一个日志又被划分为多个日志段(LogSegment),日志段是Kafka日志对象分片的最小单位。与日志对象一样,日志段也是一个逻辑概念,一个日志段对应磁盘上一个具体日志文件和两个索引文件。日志文件是以“.log”为文件名后缀的数据文件,用于保存消息实际数据。两个索引文件分别以“.index”和“.timeindex”作为文件名后缀,分别表示消息偏移量索引文件和消息时间戳索引文件。
7、代理
Kafka集群就是由一个或多个Kafka实例构成,我们将每一个Kafka实例称为代理(Broker),通常也称代理为Kafka服务器(KafkaServer)。
8、生产者
生产者(Producer)负责将消息发送给代理,也就是向Kafka代理发送消息的客户端。
9、消费者和消费组
消费者(Comsumer)以拉取(pull)方式拉取数据,它是消费的客户端。在Kafka中每一个消费者都属于一个特定消费组(ConsumerGroup),我们可以为每个消费者指定一个消费组,以groupId代表消费组名称,通过group.id配置设置。如果不指定消费组,则该消费者属于默认消费组test-consumer-group。同时,每个消费者也有一个全局唯一的id,通过配置项client.id指定,如果客户端没有指定消费者的id, Kafka会自动为该消费者生成一个全局唯一的id,格式为
g
r
o
u
p
I
d
−
{groupId}-
groupId−{hostName}-
t
i
m
e
s
t
a
m
p
−
{timestamp}-
timestamp−{UUID前8位字符}。同一个主题的一条消息只能被同一个消费组下某一个消费者消费,但不同消费组的消费者可同时消费该消息。消费组是Kafka用来实现对一个主题消息进行广播和单播的手段,实现消息广播只需指定各消费者均属于不同的消费组,消息单播则只需让各消费者属于同一个消费组。
10、ISR
Kafka在ZooKeeper中动态维护了一个ISR(In-sync Replica),即保存同步的副本列表,该列表中保存的是与Leader副本保持消息同步的所有副本对应的代理节点id。如果一个Follower副本宕机(本书用宕机来特指某个代理失效的情景,包括但不限于代理被关闭,如代理被人为关闭或是发生物理故障、心跳检测过期、网络延迟、进程崩溃等)或是落后太多,则该Follower副本节点将从ISR列表中移除。
11、ZooKeeper在Kafka中的作用
Kafka利用ZooKeeper保存相应元数据信息,Kafka元数据信息包括如代理节点信息、Kafka集群信息、旧版消费者信息及其消费偏移量信息、主题信息、分区状态信息、分区副本分配方案信息、动态配置信息等。Kafka在启动或运行过程当中会在ZooKeeper上创建相应节点来保存元数据信息,Kafka通过监听机制在这些节点注册相应监听器来监听节点元数据的变化,从而由ZooKeeper负责管理维护Kafka集群,同时通过ZooKeeper我们能够很方便地对Kafka集群进行水平扩展及数据迁移。
12、集群架构

三、Kafka特性
1、消息持久化
Kafka高度依赖于文件系统来存储和缓存消息。
2、高吞吐量
高吞吐量是Kafka设计的主要目标,Kafka将数据写到磁盘,充分利用磁盘的顺序读写。
3、扩展性
Kafka要支持对大规模数据的处理,就必须能够对集群进行扩展,分布式必须是其特性之一,这样就可以将多台廉价的PC服务器搭建成一个大规模的消息系统。Kafka依赖ZooKeeper来对集群进行协调管理,这样使得Kafka更加容易进行水平扩展,生产者、消费者和代理都为分布式,可配置多个。同时在机器扩展时无需将整个集群停机,集群能够自动感知,重新进行负责均衡及数据复制。
4、多客户端支持
Kafka核心模块用Scala语言开发,但Kafka支持不同语言开发生产者和消费者客户端应用程序。同时,Kafka支持多种连接器(Connector)的接入,也提供了Connector API供开发者调用。Kafka与当前主流的大数据框架都能很好地集成,如Flume、Hadoop、HBase、Hive、Spark、Storm等。
5、Kafka Streams
Kafka在0.10之后版本中引入Kafak Streams。Kafka Streams是一个用Java语言实现的用于流处理的jar文件。
6、安全机制
当前版本的Kafka支持以下几种安全措施:
- 通过SSL和SASL(Kerberos), SASL/PLAIN验证机制支持生产者、消费者与代理连接时的身份认证;
- 支持代理与ZooKeeper连接身份验证;
- 通信时数据加密;
- 客户端读、写权限认证;
- Kafka支持与外部其他认证授权服务的集成。
7、数据备份
Kafka可以为每个主题指定副本数,对数据进行持久化备份,这可以一定程度上防止数据丢失,提高可用性。
8、轻量级
Kafka的代理是无状态的,即代理不记录消息是否被消费,消费偏移量的管理交由消费者自己或组协调器来维护。同时集群本身几乎不需要生产者和消费者的状态信息,这就使得Kafka非常轻量级,同时生产者和消费者客户端实现也非常轻量级。
9、消息压缩
Kafka支持Gzip、Snappy、LZ4这3种压缩方式,通常把多条消息放在一起组成MessageSet,然后再把MessageSet放到一条消息里面去,从而提高压缩比率进而提高吞吐量。
四、Kafka环境搭建
1、jdk环境
详见《CentOS7环境安装jdk、tomcat及其配置环境变量》。
2、ZooKeeper环境安装(单机配置)
1、下载zookeeper
wget https://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
2、解压
tar -zxvf zookeeper-3.4.14.tar.gz
3、修改配置zoo.cfg(第一次需要把zoo_sample.cfg重命名成zoo.cfg)
修改dataDir和dataLogDir配置如下:
dataDir=/usr/local/soft/zookeeper-3.4.14/data
dataLogDir=/usr/local/soft/zookeeper-3.4.14/logs
其他配置含义如下:

3、启动
./zkServer.sh start
启动结果如下:

4、查看状态
./zkServer.sh status

3、ZooKeeper环境安装(集群配置)
1、修改主机名
分别在三台主机上执行下面命令:
#主机1执行
hostnamectl set-hostname node08
#主机2执行
hostnamectl set-hostname node09
#主机3执行
hostnamectl set-hostname node10
2、配置主机名与IP的映射
分别在三台主机上修改/etc/hosts文件。增加如下内容:
192.168.1.8 server08
192.168.1.9 server09
192.168.1.10 server10
3、新增myid
在${dataDir}路径下创建一个myid文件。myid里存放的值就是服务器的编号。
4、添加环境变量
在/etc/profile文件中,增加如下配置:
ZOOKEEPER_HOME=/usr/local/soft/zookeeper-3.4.14
PATH=$PATH:$ZOOKEEPER_HOME/bin
export PATH ZOOKEEPER_HOME
5、配置其他服务
安装上述步骤,配置其他主机上的zookeeper。
6、启动
在三台主机上分别启动zookeeper。
zkServer.sh start
7、查看状态
zkServer.sh status
出现如下两种情况,其中一个是leader,另外两个是follower。


4、Kafka环境安装(单机)
1、下载
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.5.0/kafka_2.12-2.5.0.tgz
2、解压
tar -zxvf kafka_2.12-2.5.0.tgz
3、修改环境变量
通过命令:
vim /etc/profile
修改环境变量,新增如下内容:
KAFKA_HOME=/usr/local/soft/kafka_2.12-2.5.0
PATH=$PATH:$KAFKA_HOME/bin
export PATH KAFKA_HOME
刷新,让环境变量配置生效,命令如下:
source /etc/profile
4、修改配置文件server.properties
broker.id=0
log.dirs=/usr/local/soft/kafka_2.12-2.5.0/logs
5、启动kafka
#后台启动,可以添加-daemon参数,有可能启动失败,需要查看日志
kafka-server-start.sh /usr/local/soft/kafka_2.12-2.5.0/config/server.properties
6、验证
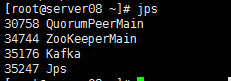
1>、执行jps命令查看Java进程,此时进程信息至少包括以下几项:
2>、通过ZooKeeper客户端登录ZooKeeper查看目录结构,执行以下命令:
zkCli.sh -server server08:2181
ls /

5、Kafka环境安装(集群)
1、基础配置
完成单机版步骤
2、修改配置文件
修改server.properties文件中Kafka连接ZooKeeper的配置。
zookeeper.connect=server08:2181,server09:2181,server10:2181
复制完成后,分别登录另外两台机器,修改server.properties文件中的broker.id依次为2和3。并新增如下配置:
host.name=192.168.1.8
#或
host.name=192.168.1.9
#或
host.name=192.168.1.10
3、启动kafka
分别启动kafka。
#后台启动,可以添加-daemon参数,有可能启动失败,需要查看日志
kafka-server-start.sh /usr/local/soft/kafka_2.12-2.5.0/config/server.properties
Kafka若不设置host.name,则会在创建主题及向主题发送消息时发生NOT_LEADER_FOR_PARTITION这样的异常。
4、验证
通过ZooKeeper客户端登录ZooKeeper查看目录结构,执行以下命令:
zkCli.sh -server server08:2181
ls /
zkCli.sh -server server08:2181
ls /brokers/ids

7、springboot整合kafka
完整源码地址:https://gitee.com/hsh2015/learningDemo/tree/master/Kafka_learning。
1、pom.xml文件
新增kafka依赖。
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
2、启动类
@SpringBootApplication()
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class,args);
}
}
3、配置文件
server.port=8080
server.servlet.context-path=/kafka
server.tomcat.uri-encoding=UTF-8
#============== kafka ===================
# 指定kafka server的地址,集群配多个,中间,逗号隔开
spring.kafka.bootstrap-servers=192.168.1.8:9092,192.168.1.9:9092,192.168.1.10:9092
#=============== provider =======================
# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
spring.kafka.producer.retries=0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
spring.kafka.producer.batch-size=16384
# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
spring.kafka.producer.buffer-memory=33554432
#procedure要求leader在考虑完成请求之前收到的确认数,用于控制发送记录在服务端的持久化,其值可以为如下:
#acks = 0 如果设置为零,则生产者将不会等待来自服务器的任何确认,该记录将立即添加到套接字缓冲区并视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障),为每条记录返回的偏移量始终设置为-1。
#acks = 1 这意味着leader会将记录写入其本地日志,但无需等待所有副本服务器的完全确认即可做出回应,在这种情况下,如果leader在确认记录后立即失败,但在将数据复制到所有的副本服务器之前,则记录将会丢失。
#acks = all 这意味着leader将等待完整的同步副本集以确认记录,这保证了只要至少一个同步副本服务器仍然存活,记录就不会丢失,这是最强有力的保证,这相当于acks = -1的设置。
#可以设置的值为:all, -1, 0, 1
spring.kafka.producer.acks=1
# 指定消息key和消息体的编解码方式
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#=============== consumer =======================
# 指定默认消费者group id --> 由于在kafka中,同一组中的consumer不会读取到同一个消息,依靠groud.id设置组名
spring.kafka.consumer.group-id=testGroup
# smallest和largest才有效,如果smallest重新0开始读取,如果是largest从logfile的offset读取。一般情况下我们都是设置smallest
spring.kafka.consumer.auto-offset-reset=earliest
# enable.auto.commit:true --> 设置自动提交offset
spring.kafka.consumer.enable-auto-commit=true
#如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。
spring.kafka.consumer.auto-commit-interval=100
# 指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
4、生产者(产生消息)
@RestController
public class KafkaController {
@Autowired
private KafkaTemplate<String,Object> kafkaTemplate;
@GetMapping("/message/send")
public boolean send(@RequestParam String message){
kafkaTemplate.send("testTopic",message);
return true;
}
}
5、消费者(接收消息)
@Component
public class ConsumerListener {
@KafkaListener(topics = "testTopic")
public void onMessage(String message){
//insertIntoDb(buffer);//这里为插入数据库代码
System.out.println(message);
}
}
错误
1、Using config: /usr/local/soft/zookeeper-3.4.14/bin/…/conf/zoo.cfg,Error contacting service. It is probably not running.
防火墙问题,关掉防火墙即可。
2、 error during sbt launcher: java.lang.RuntimeException: Expected one of local, maven-local, maven-central, scala-tools-releases, scala-tools-snapshots, sonatype-oss-releases, sonatype-oss-snapshots, jcenter, got 'local '.
原因:将sbt的配置源修改为国内aliyun时,执行的时候报错,去看了一遍,原来是粘贴的配置文件里有空格,每一行的结尾都有,所以导致无法识别。
3、2020-06-09 08:58:46.554 ERROR 7692 — [ad | producer-1] o.s.k.support.LoggingProducerListener : Exception thrown when sending a message with key=‘null’ and payload=‘abc’ to topic testTopic:org.apache.kafka.common.errors.NetworkException: The server disconnected before a response was received.
重启kafka服务。
















 3361
3361











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











