







线性回归(Linear Regression)
从这篇文章开始,主要介绍机器学习的一些列基本算法,本文介绍线性回归问题,以及利用最小均方和梯度下降解决线性回归问题。
(以下内容是根据斯坦福大学ng教授的机器学习公开课总结的内容)
监督学习:即训练数据中既包含了输入数据又包含了对应于这个是输入数据的正确的输出结果。
回归问题:当给出了输入数据后,预测正确的输出结果。
线性回归函数
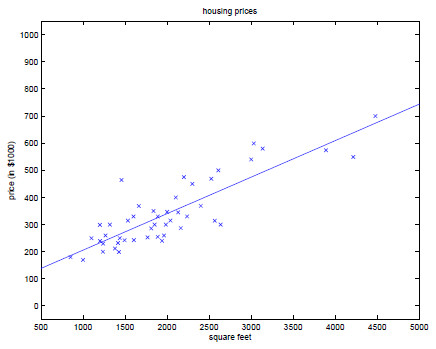
首先考虑一个问题:我们需要预测自己房屋的价格,现在拥有的数据只是几十个房屋样本价格,如下图所示。怎样根据这些房屋的面积以及价格来预测我们自己房屋的价格呢?
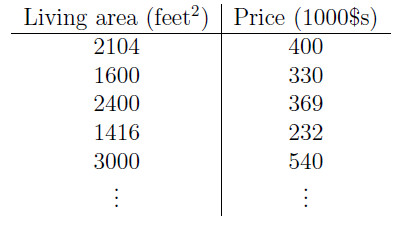
为了更加直观的将已知样本房屋的价格表示出来,我们将上述数据标注在坐标系中,如下图:
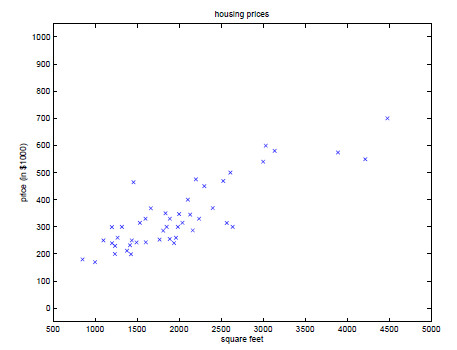
由图我们可以看出,点的分布大致围绕在一条直线周围,因此,我们可以用一个线性函数表示房屋的面积与房屋的价格的对应关系,流程大致如下:
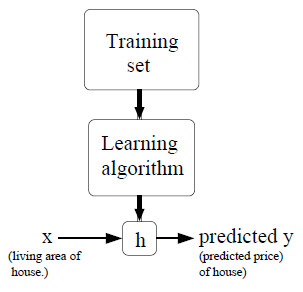
利用训练数据+学习算法得到一个函数h,然后将待预测的房屋面积输入,即可得到预测的房价。
首先介绍具体字母代表的含义:
- m:训练数据的总数。
- x:输入值
- y:输出值
- (x,y):训练样本
- ( x(i) , y(i) ):训练样本中的第i对值
为了使得问题更加具有一般性,我们将上面的例子进行扩充成如下表格:
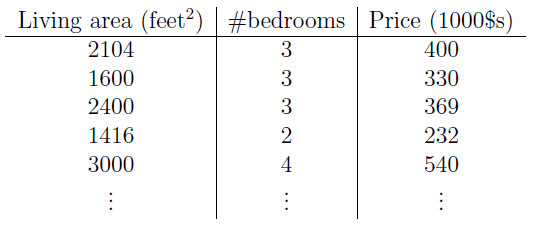
现在我们假设输出值和输入值之间对应的关系为线性函数:
- hθ(x)=θ0+θ1x1+θ2x2
上面的式子为了便于表达,假设 x0=1 ,因此,可以写成:
- hθ(x)=θ0x0+θ1x1+θ2x2=∑ni=0θixi=θTX
现在,当我们有了测试集,怎样来预测参数θ?,我们的目的就是使得预测结果尽量接近与真实的结果,因此,在所有的训练集上,我们需要使得该函数的输出结果尽量可能接近真实值,也就是使得差量最小,因此可以表示为如下的形式:
- J(θ)=1/2∑mi=0(hθ(x(i))−y(i))2
这个表达形式可以表现出预测值和真实值的平方差量,其中前面的1/2主要是为了后面的求导计算方便,m表示的是所有的训练数据总数量。到这里,我们表示出了误差函数,也就是损失函数,我们的目标是最小化损失函数J(θ),用到的方法是梯度下降法。
梯度下降(gradient descent)
首先我们考虑一个实际的情景,当我们站在山腰的时候,如果我们想最快到达山地,我们首选的方法当然是找坡度最大的地方,即梯度的方向。如下图所示:
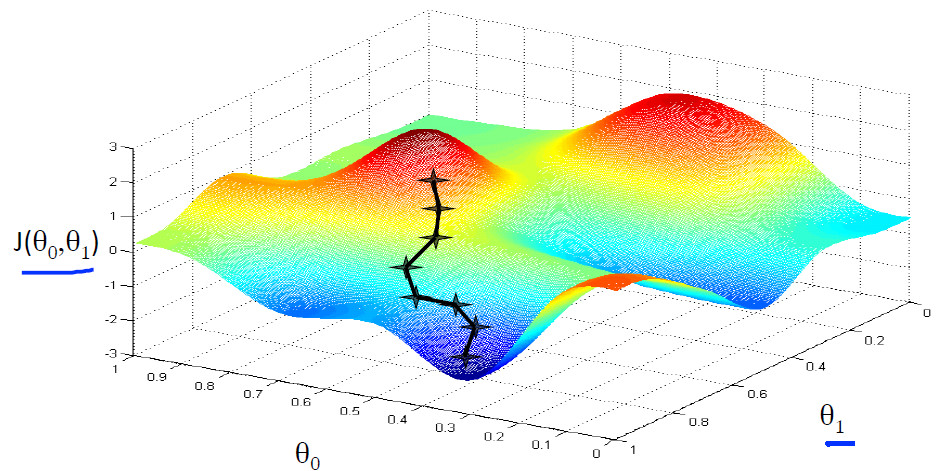
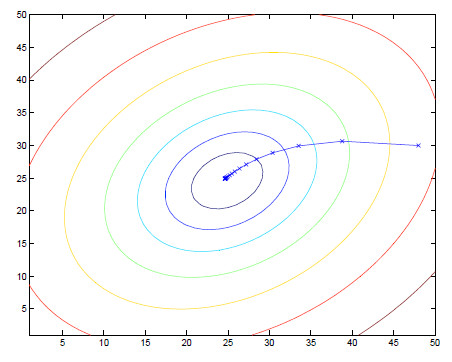
但是,我们会发现一个问题,那就是当我们所处的位置不同的时候,就会走到不同的最低位置,即会出现局部最优,而不是寻找的全局最优值,如下图所示:
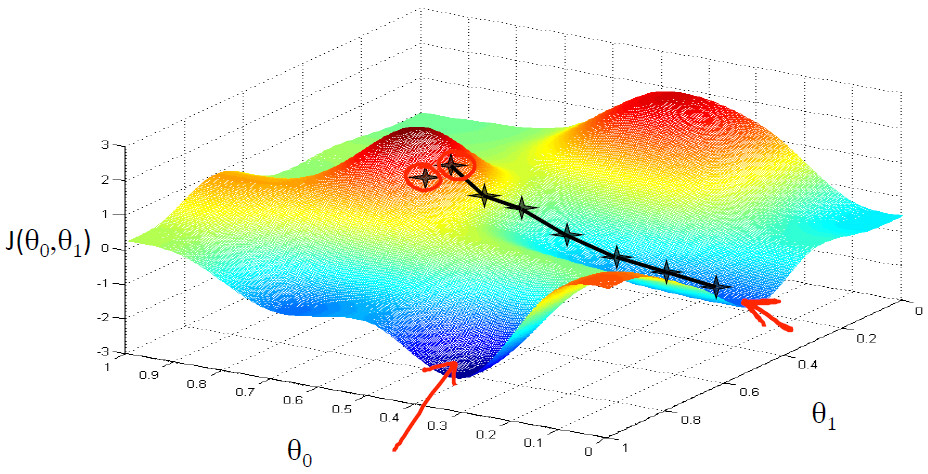
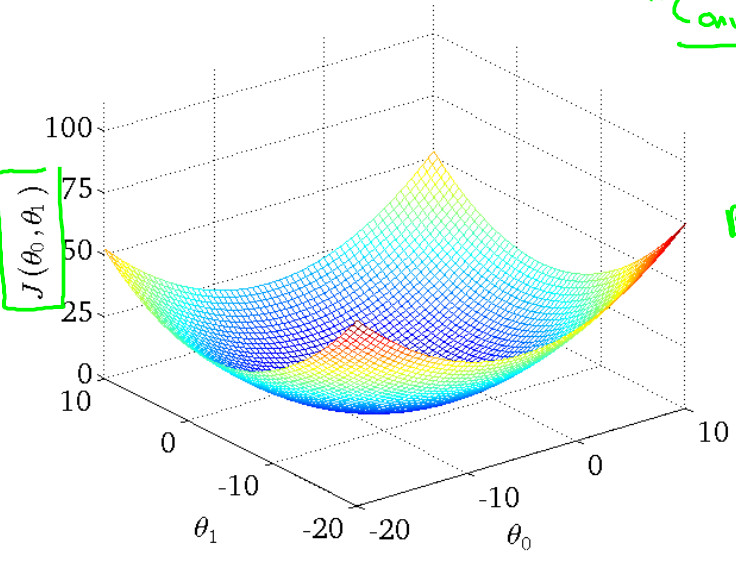
其实,现实我们遇见的现实问题大多只有一个最小值,因此,不会走入局部最优值。例如本实例图像如下所示:
现在,根据上图可以看出我们需要做的就是不断地更新
θ
(此处的为一个向量,包括
θ1和θ2
)值,得到到达最小值时候的
θ
,更新的方法如下,即求偏导后沿着偏导数数的方向进行更新。
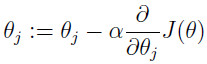
该表达式表示对
θi
(包括
θ1和θ2
)更新,其中的α表示更新不发的大小(如果太大可能直接越过了最小值,如果太小,迭代速度太慢,代价太大)。将J带入后计算如下:
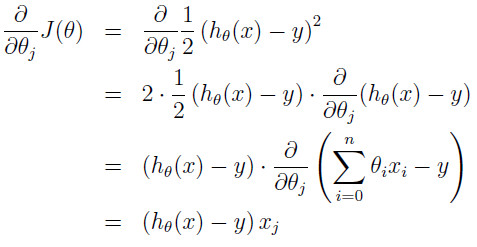
最后结果为:
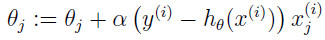
这个规则称为最小均方(LMS,least mean squares)更新规则
对于以上的式子进行充分直到得到结果即可,其中重复的形式有两种,一种称作批梯度下降(batch gradient descent)和随机梯度下降(stochastic gradient descent)。
批梯度下降(batch gradient descent)
批梯度下降即每次更新一个参数的一步时候,都需要将所有的数据计算一遍,算法如下:
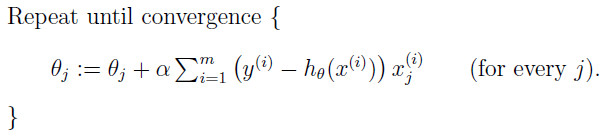
很明显,这个算法当训练数据集很大的时候,会导致算法变慢,时间复杂度太大。因此,一般用的比较少。
随机梯度下降(stochastic gradient descent)
随机梯度下降主要是对以上算法的优化,每一步参数的更新,只看训练数据集中的一个训练数据,算法如下:
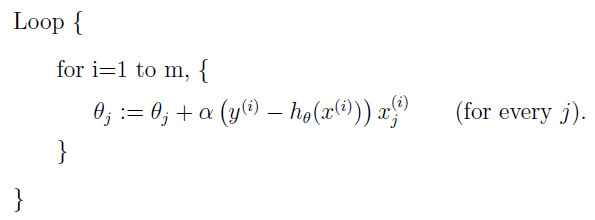
利用以上的算法更新开头提出的问题的解法过程图像和最终结果图像如下:
个人博客:http://www.houlaizhexq.com,http://houlaizhexq.github.io/















 1114
1114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









