







根据 Yarn 的 Application 找到 Hive 的 SQL,需要根据执行引擎(tez 或者 mr)的不同有不同的方法。以下以 TEZ 引擎 为例。
1. 通过界面
找到 Application
点击 Tracking URL 后面的链接,当运行的时候是 “ApplicationMaster”。当运行结束后是 “History”
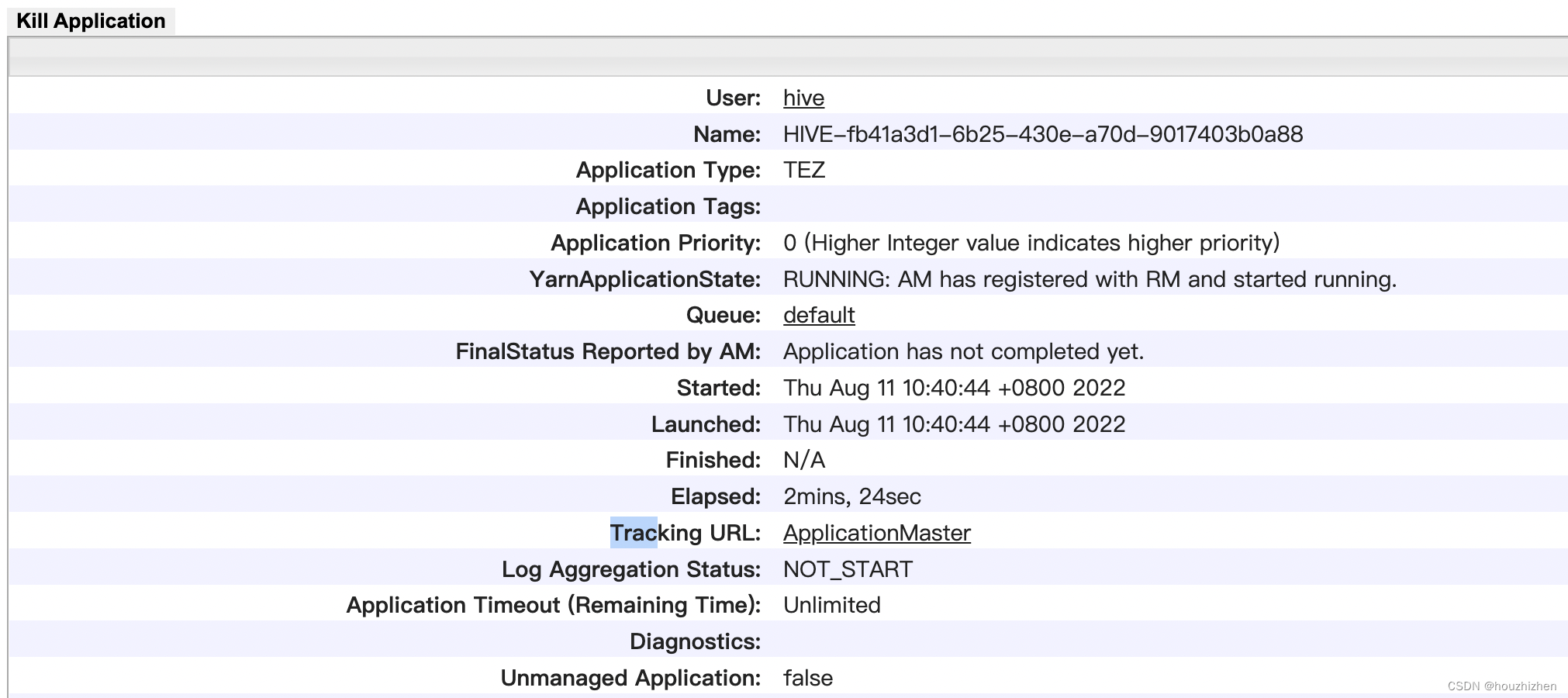
进入 Application 界面,如下图所示。
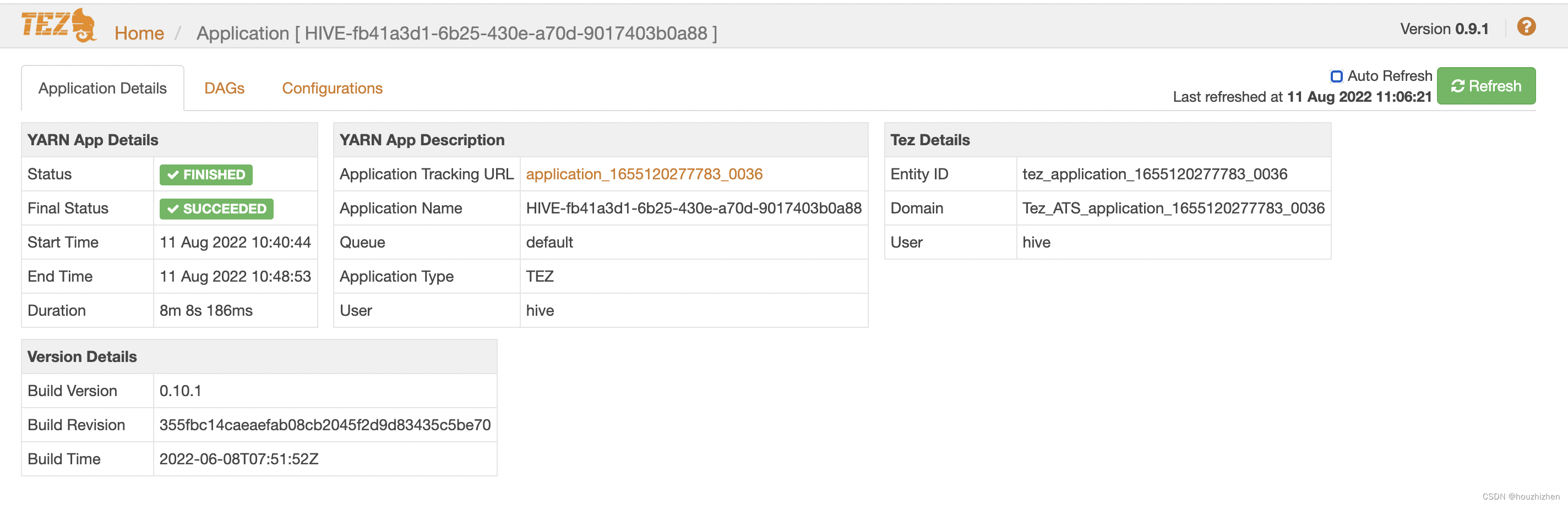
点击 [DAGs],一个 Appcation 可能运行多个 DAG,一个SQL 运行生成一个 DAG。

点击对应的 DAG,进入下面的界面
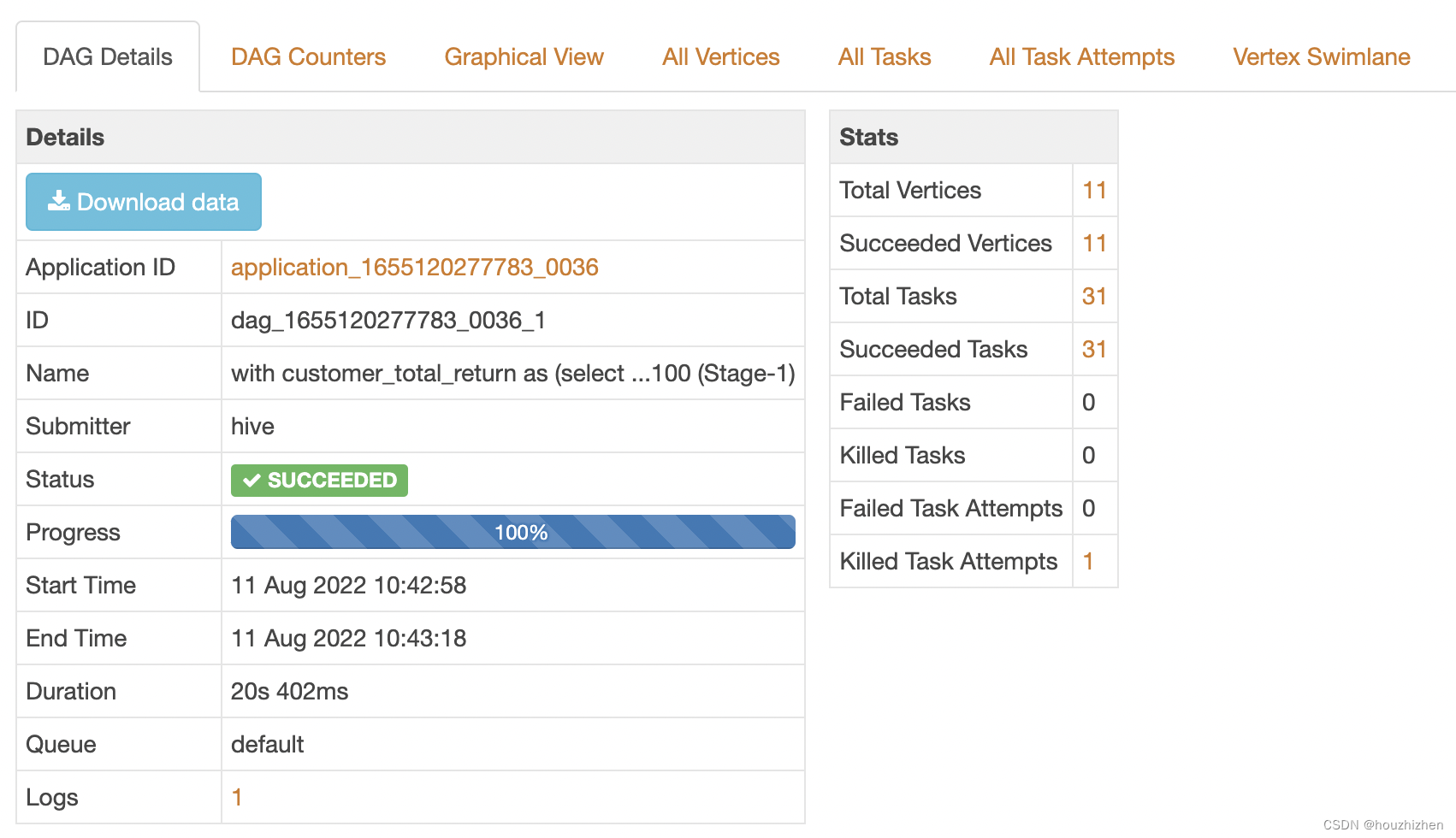
点击【Download data】,下载一个 zip 文件,点击解压此文件。

进入目录【dag_1655120277783_0036_1】,如下图所示。
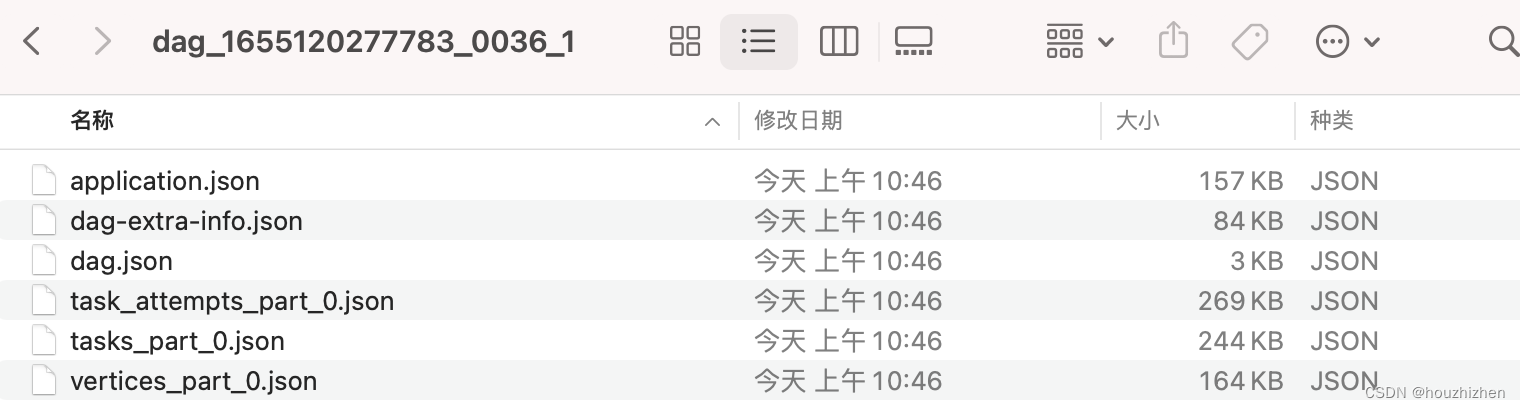
打开文件【dag-extra-info.json】,搜索 【description】,找到dagPlan/dagContext/description,就是执行的SQL。由于'换行符'替换为 \n,如果执行此SQL,需要把 \n 换为'换行符' 或者空格。

2. 通过 timeline-server api
假设 timeline server 监听 172.23.233.232 8188 端口
那么假设 application id 是 application_1660210417920_0001。首先根据 application id 找到对应的 dag id,然后第2步根据 dag id 查找dag 的详细信息,详细信息里包含 SQL。
2.1 根据 application 找到对应的 dag id
http://172.23.233.232:8188/ws/v1/timeline/TEZ_APPLICATION/tez_application_1660210417920_0001根据 TEZ_DAG_ID 找到后面的 dag id。
{"TEZ_DAG_ID":["dag_1660210417920_0001_1"]}2.2 根据 dag id 请求 dag 的详细信息
http://172.23.233.232:8188/ws/v1/timeline/TEZ_DAG_EXTRA_INFO/dag_1660210417920_0001_1搜索 description 找到对应的SQL
"description":"select c1,count(1) cnt from t1 group by c1"
















 3833
3833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









