









对于pgvector0.6.0的向量相关查询,稍不注意,优化器就会不使用向量索引,例如:

这个查询,先查询出 id 在 10 和 100 之间的记录,然后对这些记录,按照与向量 ‘[3, 1, 2]’ 的距离排序。
从执行计划看,是先用 id 上的索引(主键),选出 id 在 10 到 100 之间的记录,然后对这些记录计算向量距离并排序,查找最近向量的方法是排序,是一种暴力计算的方法。
可以看到,这里并没有使用pgvector所特有的向量索引。
当 where 的条件查询出的记录多到一定程度时(估计selectivity不同了),优化器便会选择另一个执行计划,如下图,会先按照向量索引查询出最近的若干向量,然后再对这些最邻近向量所在行,按其它字段进行条件过滤,这种情况使用了向量索引。

同样的查询类型,查询的范围不同,优化器会根据cost给出不同的执行计划。

在上面的查询中,返回的最邻近向量数只有一个,没有达到5个的需求,在不改变执行计划的前提下,可以增大where的查询范围,即按照向量索引查询后,过滤条件放宽一些,或许可以得到更多结果,然后再用limit选取头几条。

上面的查询模式,增大limit的值也会带来执行计划的改变,例如:
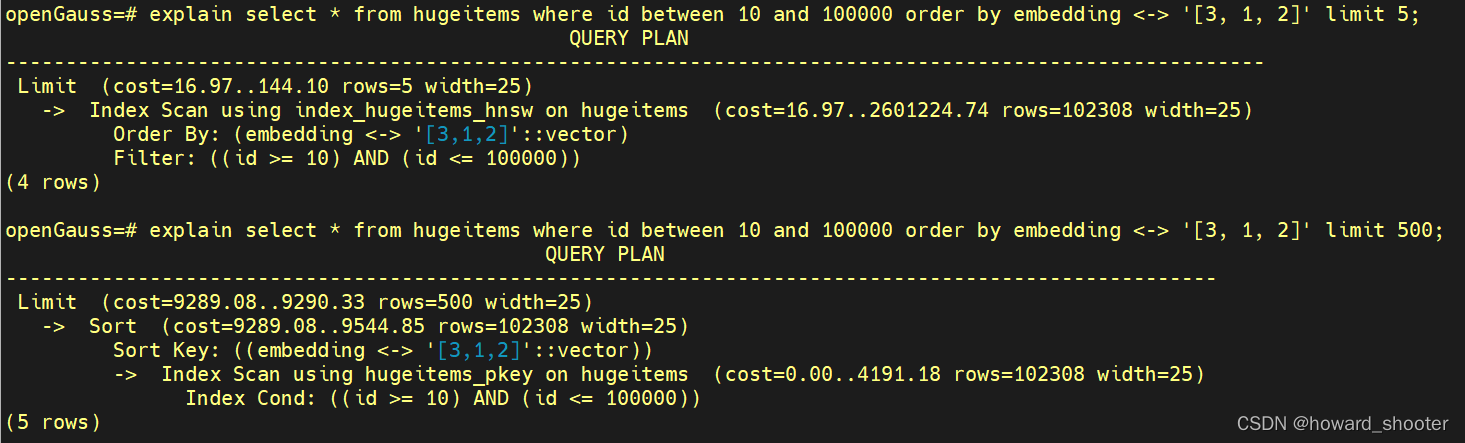
这就需要,每次对SQL做修改时,查看执行计划,有时数据库的优化,和业务内容强相关。















 2579
2579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









