







从头到尾彻底理解KMP
用暴力匹配的思路,并假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置,则有:
- 如果当前字符匹配成功(即S[i] == P[j]),则i++,j++,继续匹配下一个字符;
- 如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0。相当于每次匹配失败时,i 回溯,j 被置为0。
int BFMatch(char* s, char* p)
{
int sLen = strlen(s);
int pLen = strlen(p);
int i = 0;
int j = 0;
while (i < sLen && j < pLen)
{
if (s[i] == p[j])
{
//①如果当前字符匹配成功(即S[i] == P[j]),则i++,j++
i++;
j++;
}
else
{
//②如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0
i = i - j + 1;
j = 0;
}
}
//匹配成功,返回模式串p在文本串s中的位置,否则返回-1
if (j == pLen)
return i - j;
else
return -1;
}举个例子,如果给定文本串S“BBC ABCDAB ABCDABCDABDE”,和模式串P“ABCDABD”,现在要拿模式串P去跟文本串S匹配,整个过程如下所示:S[0]为B,P[0]为A,不匹配,执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,S[1]跟P[0]匹配,相当于模式串要往右移动一位(i=1,j=0)

S[1]跟P[0]还是不匹配,继续执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,S[2]跟P[0]匹配(i=2,j=0),从而模式串不断的向右移动一位(不断的执行“令i = i - (j - 1),j = 0”,i从2变到4,j一直为0)

直到S[4]跟P[0]匹配成功(i=4,j=0),此时按照上面的暴力匹配算法的思路,转而执行第①条指令:“如果当前字符匹配成功(即S[i] == P[j]),则i++,j++”,可得S[i]为S[5],P[j]为P[1],即接下来S[5]跟P[1]匹配(i=5,j=1)

S[5]跟P[1]匹配成功,继续执行第①条指令:“如果当前字符匹配成功(即S[i] == P[j]),则i++,j++”,得到S[6]跟P[2]匹配(i=6,j=2),如此进行下去
直到S[10]为空格字符,P[6]为字符D(i=10,j=6),因为不匹配,重新执行第②条指令:“如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0”,相当于S[5]跟P[0]匹配(i=5,j=0)
至此,我们可以看到,如果按照暴力匹配算法的思路,尽管之前文本串和模式串已经分别匹配到了S[9]、P[5],但因为S[10]跟P[6]不匹配,所以文本串回溯到S[5],模式串回溯到P[0],从而让S[5]跟P[0]匹配。
而S[5]肯定跟P[0]失配。为什么呢?因为在之前第4步匹配中,我们已经得知S[5] = P[1] = B,而P[0] = A,即P[1] != P[0],故S[5]必定不等于P[0],所以回溯过去必然会导致失配。那有没有一种算法,让i 不往回退,只需要移动j 即可呢?
答案是肯定的。这种算法就是本文的主旨KMP算法,它利用之前已经部分匹配这个有效信息,保持i 不回溯,通过修改j 的位置,让模式串尽量地移动到有效的位置。
2.1.KMP算法
- 假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
- 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
- 换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值(next 数组的求解会在下文的3.3.3节中详细阐述),即移动的实际位数为:j,且此值大于等于1。
int KMP(Str s , Str p , int *next)
{
int i=0,j=0;
while(i<s.length&&j<p.length)
{
if(s.ch[i]==p.ch[j])//匹配
{
++i;
++j;
}
else
{
j = next[j];//走下一步,从next中选择
if(j==-1)
{
j=0;
++i;
}
}
}
if(j==p.length)
return i-p.length;
else
return -1;
} 2.2步骤
- ①寻找前缀后缀最长公共元素长度
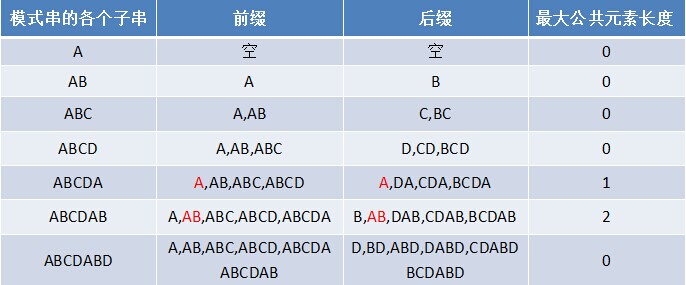
- 对于P = p0 p1 ...pj-1 pj,寻找模式串P中长度最大且相等的前缀和后缀。如果存在p0 p1 ...pk-1 pk = pj- k pj-k+1...pj-1 pj,那么在包含pj的模式串中有最大长度为k+1的相同前缀后缀。举个例子,如果给定的模式串为“abab”,那么它的各个子串的前缀后缀的公共元素的最大长度如下表格所示:
比如对于字符串aba来说,它有长度为1的相同前缀后缀a;而对于字符串abab来说,它有长度为2的相同前缀后缀ab(相同前缀后缀的长度为k + 1,k + 1 = 2)。

- ②求next数组
- next 数组考虑的是除当前字符外的最长相同前缀后缀,所以通过第①步骤求得各个前缀后缀的公共元素的最大长度后,只要稍作变形即可:将第①步骤中求得的值整体右移一位,然后初值赋为-1,如下表格所示:
比如对于aba来说,第3个字符a之前的字符串ab中有长度为0的相同前缀后缀,所以第3个字符a对应的next值为0;而对于abab来说,第4个字符b之前的字符串aba中有长度为1的相同前缀后缀a,所以第4个字符b对应的next值为1(相同前缀后缀的长度为k,k = 1)。

- ③根据next数组进行匹配
- 匹配失配,j = next [j],模式串向右移动的位数为:j - next[j]。换言之,当模式串的后缀pj-k pj-k+1, ..., pj-1 跟文本串si-k si-k+1, ..., si-1匹配成功,但pj 跟si匹配失败时,因为next[j] = k,相当于在不包含pj的模式串中有最大长度为k 的相同前缀后缀,即p0 p1 ...pk-1 = pj-k pj-k+1...pj-1,故令j = next[j],从而让模式串右移j - next[j] 位,使得模式串的前缀p0 p1, ..., pk-1对应着文本串 si-k si-k+1, ..., si-1,而后让pk 跟si 继续匹配。如下图所示:
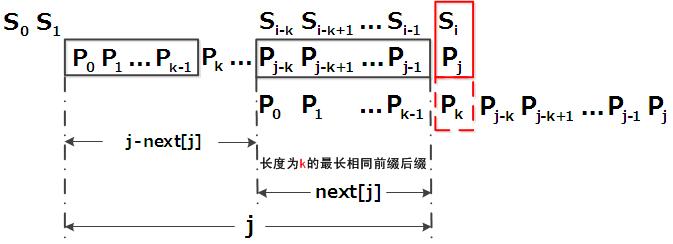
2.3.1 寻找最长前缀后缀
2.3.2 基于《最大长度表》匹配

- 1. 因为模式串中的字符A跟文本串中的字符B、B、C、空格一开始就不匹配,所以不必考虑结论,直接将模式串不断的右移一位即可,直到模式串中的字符A跟文本串的第5个字符A匹配成功:

- 22. 继续往后匹配,当模式串最后一个字符D跟文本串匹配时失配,显而易见,模式串需要向右移动。但向右移动多少位呢?因为此时已经匹配的字符数为6个(ABCDAB),然后根据《最大长度表》可得失配字符D的上一位字符B对应的长度值为2,所以根据之前的结论,可知需要向右移动6 - 2 = 4 位。

- 3. 模式串向右移动4位后,发现C处再度失配,因为此时已经匹配了2个字符(AB),且上一位字符B对应的最大长度值为0,所以向右移动:2 - 0 =2 位。

- 4. A与空格失配,向右移动1 位。
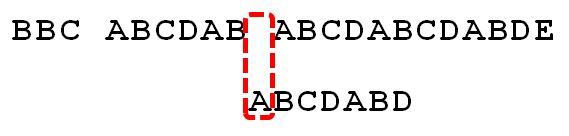
- 5. 继续比较,发现D与C 失配,故向右移动的位数为:已匹配的字符数6减去上一位字符B对应的最大长度2,即向右移动6 - 2 = 4 位。

- 6. 经历第5步后,发现匹配成功,过程结束。
通过上述匹配过程可以看出,问题的关键就是寻找模式串中最大长度的相同前缀和后缀,找到了模式串中每个字符之前的前缀和后缀公共部分的最大长度后,便可基于此匹配。而这个最大长度便正是next 数组要表达的含义。

由上文,我们已经知道,字符串“ABCDABD”各个前缀后缀的最大公共元素长度分别为:
而且,根据这个表可以得出下述结论

- 失配时,模式串向右移动的位数为:已匹配字符数 - 失配字符的上一位字符所对应的最大长度值

把next 数组跟之前求得的最大长度表对比后,不难发现,next 数组相当于“最大长度值” 整体向右移动一位,然后初始值赋为-1。意识到了这一点,你会惊呼原来next 数组的求解竟然如此简单:就是找最大对称长度的前缀后缀,然后整体右移一位,初值赋为-1(当然,你也可以直接计算某个字符对应的next值,就是看这个字符之前的字符串中有多大长度的相同前缀后缀)。
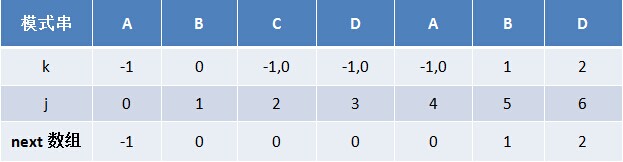
换言之,对于给定的模式串:ABCDABD,它的最大长度表及next 数组分别如下:

根据最大长度表求出了next 数组后,从而有
失配时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值 而后,你会发现,无论是基于《最大长度表》的匹配,还是基于next 数组的匹配,两者得出来的向右移动的位数是一样的。为什么呢?因为:
- 根据《最大长度表》,失配时,模式串向右移动的位数 = 已经匹配的字符数 - 失配字符的上一位字符的最大长度值
- 而根据《next 数组》,失配时,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值
- 其中,从0开始计数时,失配字符的位置 = 已经匹配的字符数(失配字符不计数),而失配字符对应的next 值 = 失配字符的上一位字符的最大长度值,两相比较,结果必然完全一致。
所以,你可以把《最大长度表》看做是next 数组的雏形,甚至就把它当做next 数组也是可以的,区别不过是怎么用的问题。
2.3.4 通过代码递推计算next 数组
int GetNext(Str s ,int *arr)
{
int k=0,j=-1;
arr[0]=-1;
while(k<s.length)
{
if(j==-1||s.ch[k]==s.ch[j])
{
k++;
j++;
//if(s.ch[j]!=s.ch[k])
arr[k]=j;
//else
// arr[k]=arr[j];
}
else
{
j=arr[j];
}
}
}用代码重新计算下“ABCDABD”的next 数组,以验证之前通过“最长相同前缀后缀长度值右移一位,然后初值赋为-1”得到的next 数组是否正确,计算结果如下表格所示:
从上述表格可以看出,无论是之前通过“最长相同前缀后缀长度值右移一位,然后初值赋为-1”得到的next 数组,还是之后通过代码递推计算求得的next 数组,结果是完全一致的。
2.3.5基于《next 数组》匹配
下面,我们来基于next 数组进行匹配。
还是给定 文本串“BBC ABCDAB ABCDABCDABDE”,和模式串“ABCDABD”,现在要拿模式串去跟文本串匹配,如下图所示:

在正式匹配之前,让我们来再次回顾下上文2.1节所述的KMP算法的匹配流程:
- “假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
- 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
- 换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值,即移动的实际位数为:j - next[j],且此值大于等于1。”
- 1. 最开始匹配时
- P[0]跟S[0]匹配失败
- 所以执行“如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]”,所以j = -1,故转而执行“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++”,得到i = 1,j = 0,即P[0]继续跟S[1]匹配。
- P[0]跟S[1]又失配,j再次等于-1,i、j继续自增,从而P[0]跟S[2]匹配。
- P[0]跟S[2]失配后,P[0]又跟S[3]匹配。
- P[0]跟S[3]再失配,直到P[0]跟S[4]匹配成功,开始执行此条指令的后半段:“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++”。
- P[0]跟S[0]匹配失败
- 2. P[1]跟S[5]匹配成功,P[2]跟S[6]也匹配成功, ...,直到当匹配到P[6]处的字符D时失配(即S[10] != P[6]),由于P[6]处的D对应的next 值为2,所以下一步用P[2]处的字符C继续跟S[10]匹配,相当于向右移动:j - next[j] = 6 - 2 =4 位。
- 3. 向右移动4位后,P[2]处的C再次失配,由于C对应的next值为0,所以下一步用P[0]处的字符继续跟S[10]匹配,相当于向右移动:j - next[j] = 2 - 0 = 2 位。
- 4. 移动两位之后,A 跟空格不匹配,模式串后移1 位。
- 5. P[6]处的D再次失配,因为P[6]对应的next值为2,故下一步用P[2]继续跟文本串匹配,相当于模式串向右移动 j - next[j] = 6 - 2 = 4 位。
- 6. 匹配成功,过程结束。
匹配过程一模一样。也从侧面佐证了,next 数组确实是只要将各个最大前缀后缀的公共元素的长度值右移一位,且把初值赋为-1 即可。
2.3.6 基于《最大长度表》与基于《next 数组》等价
我们已经知道,利用next 数组进行匹配失配时,模式串向右移动 j - next [ j ] 位,等价于已匹配字符数 - 失配字符的上一位字符所对应的最大长度值。原因是:
- j 从0开始计数,那么当数到失配字符时,j 的数值就是已匹配的字符数;
- 由于next 数组是由最大长度值表整体向右移动一位(且初值赋为-1)得到的,那么失配字符的上一位字符所对应的最大长度值,即为当前失配字符的next 值。
但为何本文不直接利用next 数组进行匹配呢?因为next 数组不好求,而一个字符串的前缀后缀的公共元素的最大长度值很容易求。例如若给定模式串“ababa”,要你快速口算出其next 数组,乍一看,每次求对应字符的next值时,还得把该字符排除之外,然后看该字符之前的字符串中有最大长度为多大的相同前缀后缀,此过程不够直接。而如果让你求其前缀后缀公共元素的最大长度,则很容易直接得出结果:0 0 1 2 3,如下表格所示:
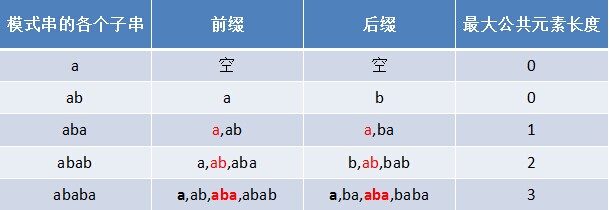
然后这5个数字 全部整体右移一位,且初值赋为-1,即得到其next 数组:-1 0 0 1 2。
2.3.7 Next 数组的优化
行文至此,咱们全面了解了暴力匹配的思路、KMP算法的原理、流程、流程之间的内在逻辑联系,以及next 数组的简单求解(《最大长度表》整体右移一位,然后初值赋为-1)和代码求解,最后基于《next 数组》的匹配,看似洋洋洒洒,清晰透彻,但以上忽略了一个小问题。
比如,如果用之前的next 数组方法求模式串“abab”的next 数组,可得其next 数组为-1 0 0 1(0 0 1 2整体右移一位,初值赋为-1),当它跟下图中的文本串去匹配的时候,发现b跟c失配,于是模式串右移j - next[j] = 3 - 1 =2位。

右移2位后,b又跟c失配。事实上,因为在上一步的匹配中,已经得知p[3] = b,与s[3] = c失配,而右移两位之后,让p[ next[3] ] = p[1] = b 再跟s[3]匹配时,必然失配。问题出在哪呢?

问题出在不该出现p[j] = p[ next[j] ]。为什么呢?理由是:当p[j] != s[i] 时,下次匹配必然是p[ next [j]] 跟s[i]匹配,如果p[j] = p[ next[j] ],必然导致后一步匹配失败(因为p[j]已经跟s[i]失配,然后你还用跟p[j]等同的值p[next[j]]去跟s[i]匹配,很显然,必然失配),所以不能允许p[j] = p[ next[j ]]。如果出现了p[j] = p[ next[j] ]咋办呢?如果出现了,则需要再次递归,即令next[j] = next[ next[j] ]。
所以,咱们得修改下求next 数组的代码。int GetNext(Str s ,int *arr)
{
int k=0,j=-1;
arr[0]=-1;
while(k<s.length)
{
if(j==-1||s.ch[k]==s.ch[j])
{
k++;
j++;
if(s.ch[j]!=s.ch[k])
arr[k]=j;
else
arr[k]=arr[j];
}
else
{
j=arr[j];
}
}
}利用优化过后的next 数组求法,可知模式串“abab”的新next数组为:-1 0 -1 0。可能有些读者会问:原始next 数组是前缀后缀最长公共元素长度值右移一位, 然后初值赋为-1而得,那么优化后的next 数组如何快速心算出呢?实际上,只要求出了原始next 数组,便可以根据原始next 数组快速求出优化后的next 数组。还是以abab为例,如下表格所示:
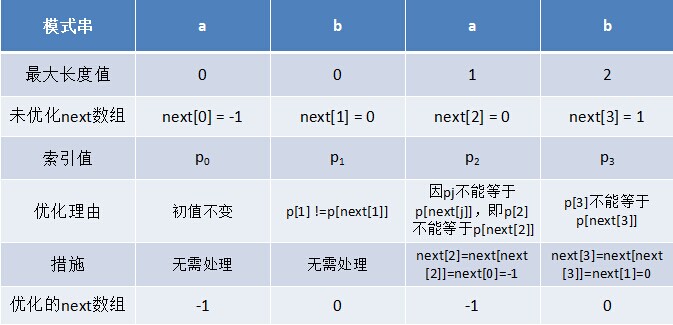
只要出现了p[next[j]] = p[j]的情况,则把next[j]的值再次递归。例如在求模式串“abab”的第2个a的next值时,如果是未优化的next值的话,第2个a对应的next值为0,相当于第2个a失配时,下一步匹配模式串会用p[0]处的a再次跟文本串匹配,必然失配。所以求第2个a的next值时,需要再次递归:next[2] = next[ next[2] ] = next[0] = -1(此后,根据优化后的新next值可知,第2个a失配时,执行“如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符”),同理,第2个b对应的next值为0。
对于优化后的next数组可以发现一点:如果模式串的后缀跟前缀相同,那么它们的next值也是相同的,例如模式串abcabc,它的前缀后缀都是abc,其优化后的next数组为:-1 0 0 -1 0 0,前缀后缀abc的next值都为-1 0 0。
3.KMP的时间复杂度分析
- 如果模式串中存在相同前缀和后缀,即pj-k pj-k+1, ..., pj-1 = p0 p1, ..., pk-1,那么在pj跟si失配后,让模式串的前缀p0 p1...pk-1对应着文本串si-k si-k+1...si-1,而后让pk跟si继续匹配。
- 之前本应是pj跟si匹配,结果失配了,失配后,令pk跟si匹配,相当于j 变成了k,模式串向右移动j - k位。
- 因为k 的值是可变的,所以我们用next[j]表示j处字符失配后,下一次匹配模式串应该跳到的位置。换言之,失配前是j,pj跟si失配时,用p[ next[j] ]继续跟si匹配,相当于j变成了next[j],所以,j = next[j],等价于把模式串向右移动j - next [j] 位。
- 而next[j]应该等于多少呢?next[j]的值由j 之前的模式串子串中有多大长度的相同前缀后缀所决定,如果j 之前的模式串子串中(不含j)有最大长度为k的相同前缀后缀,那么next
[j] = k。
“KMP的算法流程:
- 假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
- 如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
- 如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。”
我们发现如果某个字符匹配成功,模式串首字符的位置保持不动,仅仅是i++、j++;如果匹配失配,i 不变(即 i 不回溯),模式串会跳过匹配过的next [j]个字符。整个算法最坏的情况是,当模式串首字符位于i - j的位置时才匹配成功,算法结束。
所以,如果文本串的长度为n,模式串的长度为m,那么匹配过程的时间复杂度为O(n),算上计算next的O(m)时间,KMP的整体时间复杂度为O(m + n)。















 5054
5054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









