







1、PCA降维(主成分分析)
PCA降维就是去除线性相关,使得最后剩余的属性维度全都线性无关。
其实:PCA降维不仅是去除先线性无关,还可以过滤掉小特征值对应的特征向量。因为特征值变化小,对应的特征向量变化也小,转换后两个维度相似性就比较大。相似度大就没有意义。
| 均值(平均值) |  |
| 样本方差(总体方差是n,样本方差是n-1) | 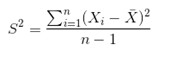 |
| 协方差(如果X等于Y,就是方差) | 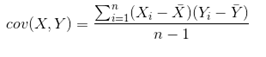 |
①去中心化,减去均值
②计算协方差
③求协方差的特征值,特征向量
④特征向量归一化,原来n维,现在要降到k维,那么就取最大的k个特征值对应的特征向量。与原输入进行相乘。
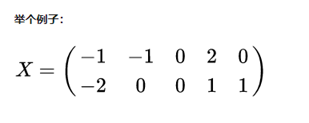
第一步:均值为0,去中心化不变
第二步:求协方差

第三步:求特征值,特征向量

第四步:特征向量归一化

第五步:取前k大特征值对应的特征向量(原输入是2维,现在要降维到1维,k=1,取最大特征值对应的特征向量)

总结:PCA降维是通过协方差求特征值和特征向量,取前k大特征对应的特征向量与原矩阵相乘,得到降维后的矩阵。原理是找到不同的特征值对应的特征向量,都是线性无关。特征值特征向量如何求取?第一步先求特征值,第二步求特征向量。特征向量中有x1+x2-x3=0(这个方程没法解,枚举,每次一位为1,其余都为0)(_,1,0)-->(-1,1,0)、(_,0,1)-->(1,0,1)
2、SVD降维(奇异值分解,参考1、参考2、参考3)
①一些基础知识
实对称矩阵:A=AT(矩阵A=矩阵A的转置)
正交矩阵:AAT=E(A的转置=A的逆矩阵)
酋矩阵:对于实数矩阵,酋矩阵就是正交矩阵,貌似矩阵中的每个向量的模长是1。
②矩阵分解
果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式子 : Av = λv
这时候λ就被称为特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:A = Q∑Q-1
其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。
首先,要明确的是,一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。
③奇异值分解(对应的A不是方阵)
奇异值分解是一个能适用于任意的矩阵的一种分解的方法: A = UΣVT
AAT的特征向量表示U、ATA的特征向量表示VT、AAT特征值得算术平方根表示Σ

总结:在图像处理中,一个700*500的图像,可以压缩到svd分解成:
U=750*750的特征向量矩阵
Σ=1*500的特征值
VT=500*500的特征向量矩阵
若前k个奇异值达到总的奇异值的90%,可以进行压缩存储。
src:750*500
dst:(750*160)+160+(160*500) (k=160)
数据恢复:UΣVT进行相乘得到原矩阵。
#奇异值分解:
U, sigma, VT = np.linalg.svd(data)
#重构,选择前160个奇异值
count = 160
dig = np.mat(np.eye(count) * sigma[:count])
redata = U[:, :count] * dig * VT[:count, :]
#降维 (750,500)(特征维度750,需要降维)
#(500,750)要转置 (750,160)#降维到160 (750*160) (160*160)
redata = np.dot(np.dot(data.T, U[:,:count]) ,dig)
数据降维:这里750表示每个特征的维度,需要找到U,np.dot(np.dot(A.T, U), S),只需把S特征值对应的置为0即可。
这里500表示每个特征的维度,需要找到VT,np.dot(np.dot(A.T, U), S)np.dot(np.dot(A, VT), S)。比如例题有两个特征值,是两维,特征变0一个那么降维到1维。
分析:PCA和SVD降维都是取某些特征值即可。PCA是取最大特征值对应的特征向量去映射原矩阵。SVD是也是取k个特征值对应的特征向量然后去映射原矩阵。(SVD可以有两种降维,一种是把特征值和对应的特征向量单独拿出来,另外一种是把不需要的特征值置为0,做运算的时候对应的特征向量不参与运算)
def SVD1():
path = 'C:/Users/hqh/desktop/wed.jpg'
data = cv2.imread(path,0)
U, sigma, VT = np.linalg.svd(data)
# 在重构之前,依据前面的方法需要选择达到某个能量度的奇异值
cnt = sum(sigma)
cnt90 = 0.9 * cnt # 达到90%时的奇异总值
count = 160 # 选择前160个奇异值
cntN = sum(sigma[:count]) #sigma已经由大到小排序
#cntN>cnt90
# 重构矩阵
dig = np.mat(np.eye(count) * sigma[:count]) # 获得对角矩阵
redata = U[:, :count] * dig * VT[:count, :] # 重构
print(redata.shape)
plt.imshow(redata, cmap='gray') # 取灰
plt.show() # 可以使用save函数来保存图片
'''
src:700*500
dst:(700*160)+160+(500*160)
'''
#U压缩行,V可以压缩列
#输入700行500列,若看成每个特征有700维度,进行降维->500是不变的,找U矩阵(data还需要转置 )
#若看成每个特征有500维度,进行降维->700是不变的,找VT矩阵
redata = np.dot(np.dot(data.T, U[:,:count]) ,dig) #降维 700*500->500*10
plt.imshow(redata, cmap='gray') # 取灰
plt.show() # 可以使用save函数来保存图片
def SVD2():
A = np.mat([[1, 2, 3], [4, 5, 6]]) #2*3
U, Sigma, VT = np.linalg.svd(A) #2*2 2 3*3
S = np.zeros((2, 3))
print("A':", np.dot(np.dot(U, S), VT)) # 恢复原始维度
Sigma[1] = 0 # 降维 #去除一个特征值
S = np.zeros((2, 3))
S[:2, :2] = np.linalg.diag(Sigma)
print("A conv:", np.dot(np.dot(A.T, U), S)) # 原始数据转到低维
S = np.mat(np.eye(1) * Sigma[:1]) # 获得对角矩阵
print("A conv:", np.dot(np.dot(A.T, U[:,0:1]), S)) # 原始数据转到低维















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









