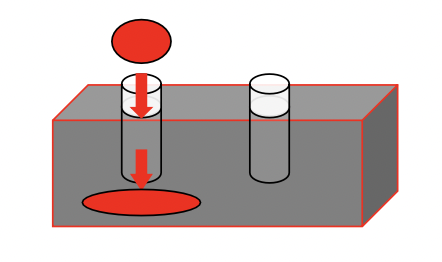
In this assignment you will add a system call tracing feature that may help you when debugging later labs. You’ll create a new trace system call that will control tracing. It should take one argument, an integer “mask”, whose bits specify which system calls to trace. For example, to trace the fork system call, a program calls trace(1 << SYS_fork), where SYS_fork is a syscall number from kernel/syscall.h. You have to modify the xv6 kernel to print out a line when each system call is about to return, if the system call’s number is set in the mask. The line should contain the process id, the name of the system call and the return value; you don’t need to print the system call arguments. The trace system call should enable tracing for the process that calls it and any children that it subsequently forks, but should not affect other processes.
subentry{ my $name = shift; print".global $name\n"; print"${name}:\n"; print" li a7, SYS_${name}\n"; print" ecall\n"; print" ret\n"; } entry("fork"); entry("exit"); ...
该脚本运行后,生成一个 usys.S 文件,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13
# generated by usys.pl - do not edit #include "kernel/syscall.h" .global fork fork: li a7, SYS_fork ecall ret .global exit exit: li a7, SYS_exit ecall ret # ...
.section trampsec .globl trampoline trampoline: .align 4 .globl uservec uservec: # # trap.c sets stvec to point here, so # traps from user space start here, # in supervisor mode, but with a # user page table. # # sscratch points to where the process's p->trapframe is # mapped into user space, at TRAPFRAME. # # swap a0 and sscratch # so that a0 is TRAPFRAME csrrw a0, sscratch, a0
# save the user registers in TRAPFRAME sd ra, 40(a0) # ... sd t6, 280(a0)
# save the user a0 in p->trapframe->a0 csrr t0, sscratch sd t0, 112(a0)
# restore kernel stack pointer from p->trapframe->kernel_sp ld sp, 8(a0)
# make tp hold the current hartid, from p->trapframe->kernel_hartid ld tp, 32(a0)
# load the address of usertrap(), p->trapframe->kernel_trap ld t0, 16(a0)
# restore kernel page table from p->trapframe->kernel_satp ld t1, 0(a0) csrw satp, t1 sfence.vma zero, zero
# a0 is no longer valid, since the kernel page # table does not specially map p->tf.
// Look in the process table for an UNUSED proc. // If found, initialize state required to run in the kernel, // and return with p->lock held. // If there are no free procs, or a memory allocation fails, return 0. staticstruct proc* allocproc(void) { // ... found: p->pid = allocpid(); p->state = USED; p->trace_mask = 0; // Allocate a trapframe page. if((p->trapframe = (struct trapframe *)kalloc()) == 0){ freeproc(p); release(&p->lock); return0; } // ... return p; }
// Create a new process, copying the parent. // Sets up child kernel stack to return as if from fork() system call. int fork(void) { // ... // Copy user memory from parent to child. if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0){ freeproc(np); release(&np->lock); return-1; } np->sz = p->sz;
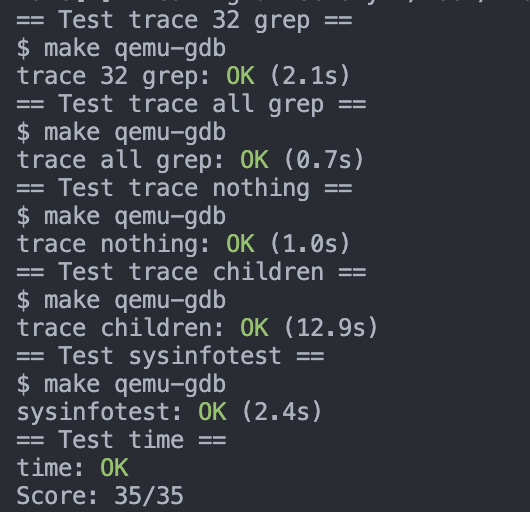
In this assignment you will add a system call, sysinfo, that collects information about the running system. The system call takes one argument: a pointer to a struct sysinfo (see kernel/sysinfo.h). The kernel should fill out the fields of this struct: the freemem field should be set to the number of bytes of free memory, and the nproc field should be set to the number of processes whose state is not UNUSED. We provide a test program sysinfotest; you pass this assignment if it prints “sysinfotest: OK”.
本文为本人完成6.s081 2021fall时的一些记录,仅作为备忘录使用。代码仓库地址:代码task 1: System call tracing (moderate)题意描述In this assignment you will add a system call tracing feature that may help you when debugging later labs....






















 472
472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









