






目录
前言
本片博客是为完成Hadoop老师布置的作业而写的,写的不好请各位看官勿喷,因为本人自己也是小白。
学习目标
了解Hadoop,虚拟机配置,完成Hadoop伪分布式部署。
一、Hadoop
1、Hadoop是什么
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 。
2、Hadoop的特点
(1)高可靠性
在处理数据时,Hadoop往往会将数据备份多份分发至不同的机器进行保存,这样就避免了在处理数据时,机器宕机导致数据丢失的麻烦,保证了数据的安全性、可靠性。
(2)高扩展性
在处理数据时,如果当前集群的资源(比如存储能力和运算能力)不足以完成数据处理和分析任务,可以通过快速扩充集群规模进行扩容和加强集群的运算能力。
(3)高效性
Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 ;相比传统的单台机器处理数据,效率是极高的。
(4)高容错性
Hadoop能自动保存数据的多个副本,当某个节点宕机时,它可以自动的将副本复制给其他机器,保证数据的完整性,并且可以将失败的任务重新分发。
(5)低成本
Hadoop集群可以将程序运行在廉价的机器上并发的进行处理,成本低、效率高,是处理海量数据的最佳选择;与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
3、Hadoop的组件
(1)HDFS:Hadoop Distribute File System,分布式文件系统,用于存储海量数据。
(2)MapReduce:Hadoop的分布式运算框架。
(3)Yarn:分布式资源调度和任务监控和分配的平台。
(4)commons:Hadoop底层的技术支持。
4、核心架构
Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心 。
二、Hadoop集群构建
1、虚拟机配置
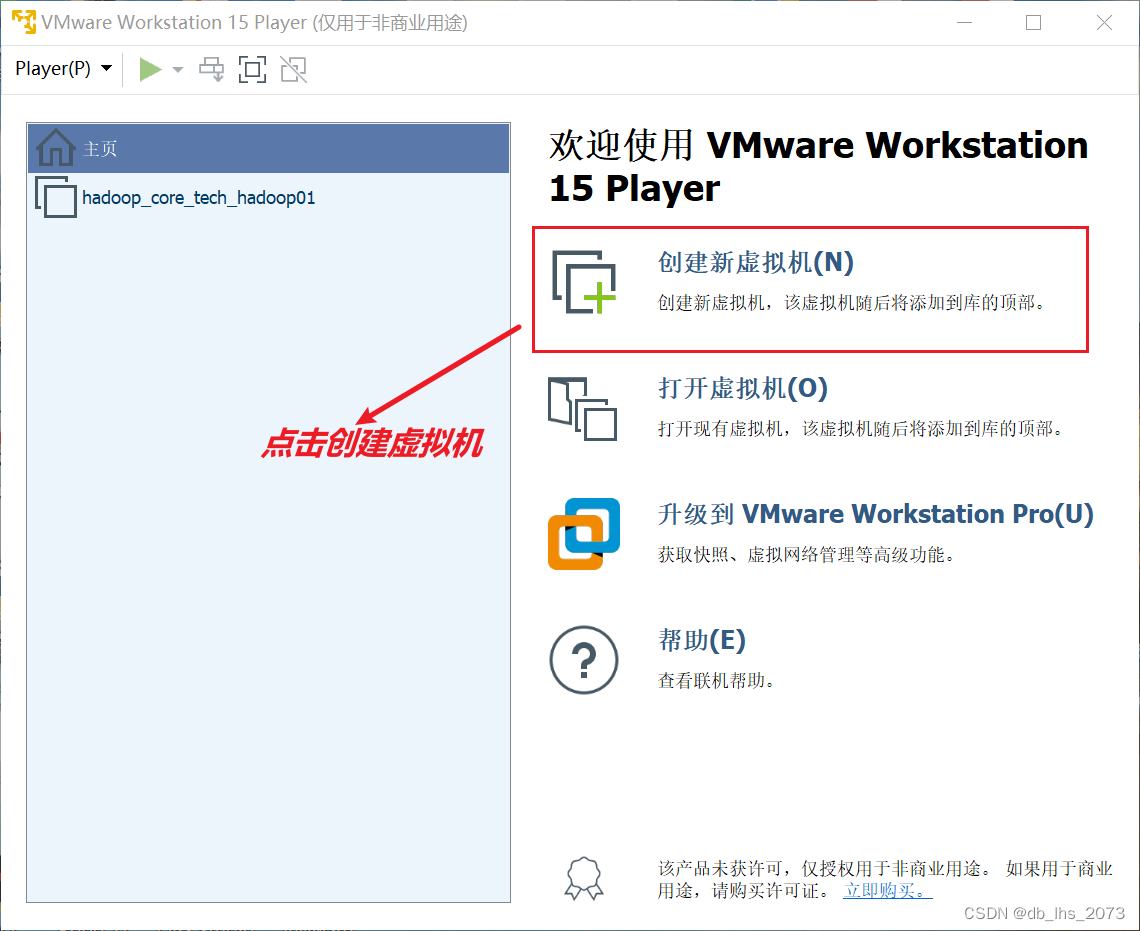
需要用到centos镜像
注:可到官网下载
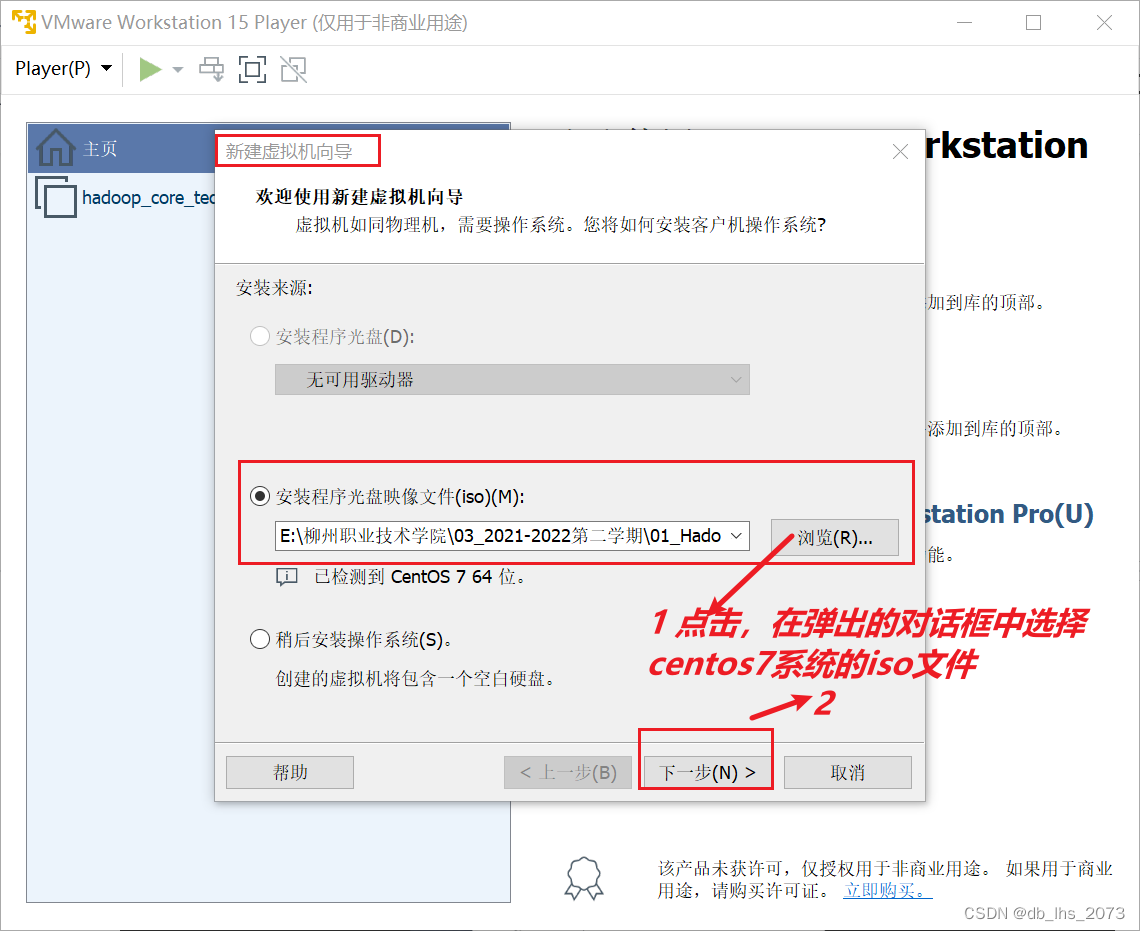
命名虚拟机,这里我命名CentOS 7 64 位
选择位置,选择空间合适的盘,搭建存放目录
然后下一步
 设置磁盘容量
设置磁盘容量 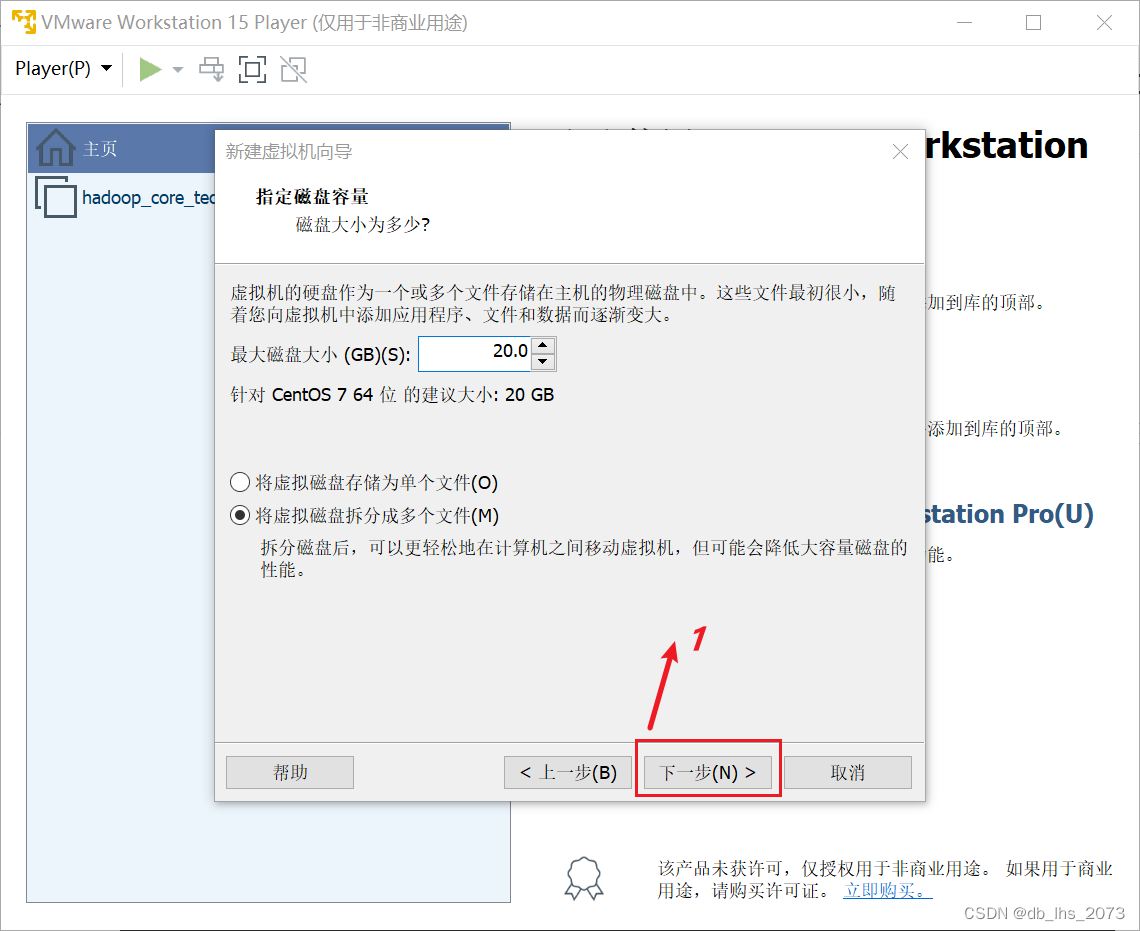
创建完成

打开虚拟机


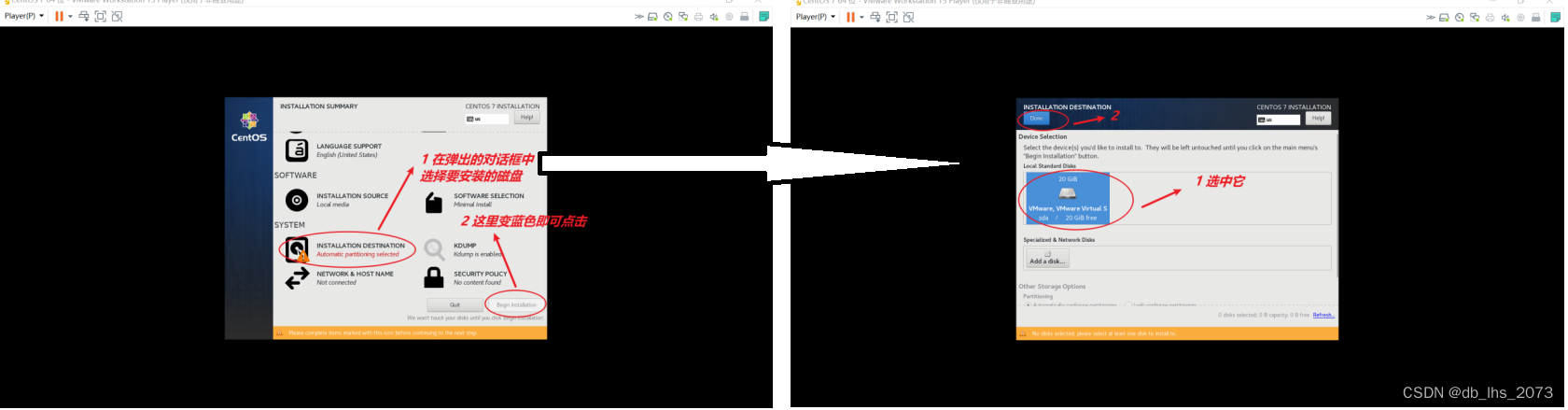
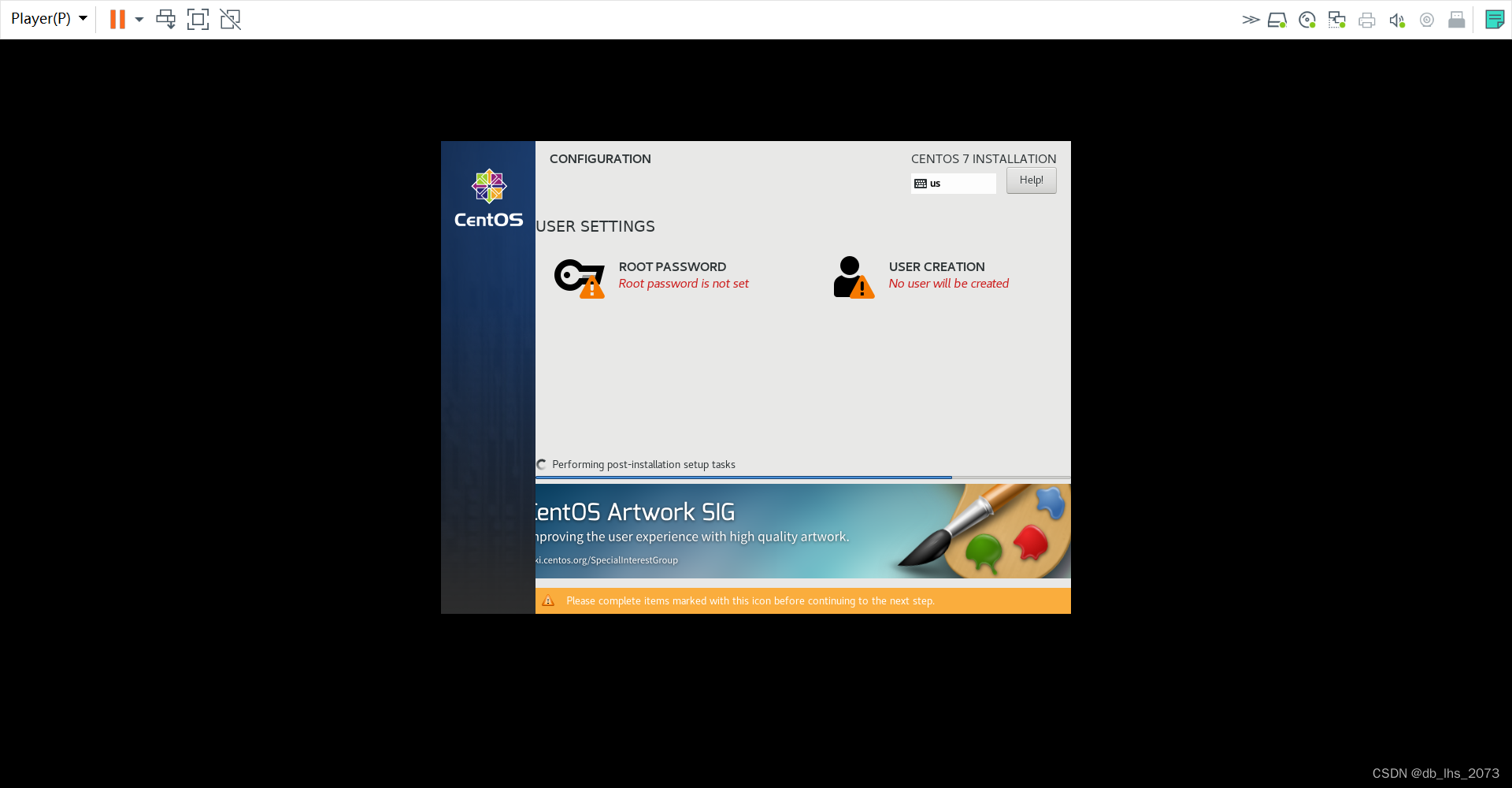
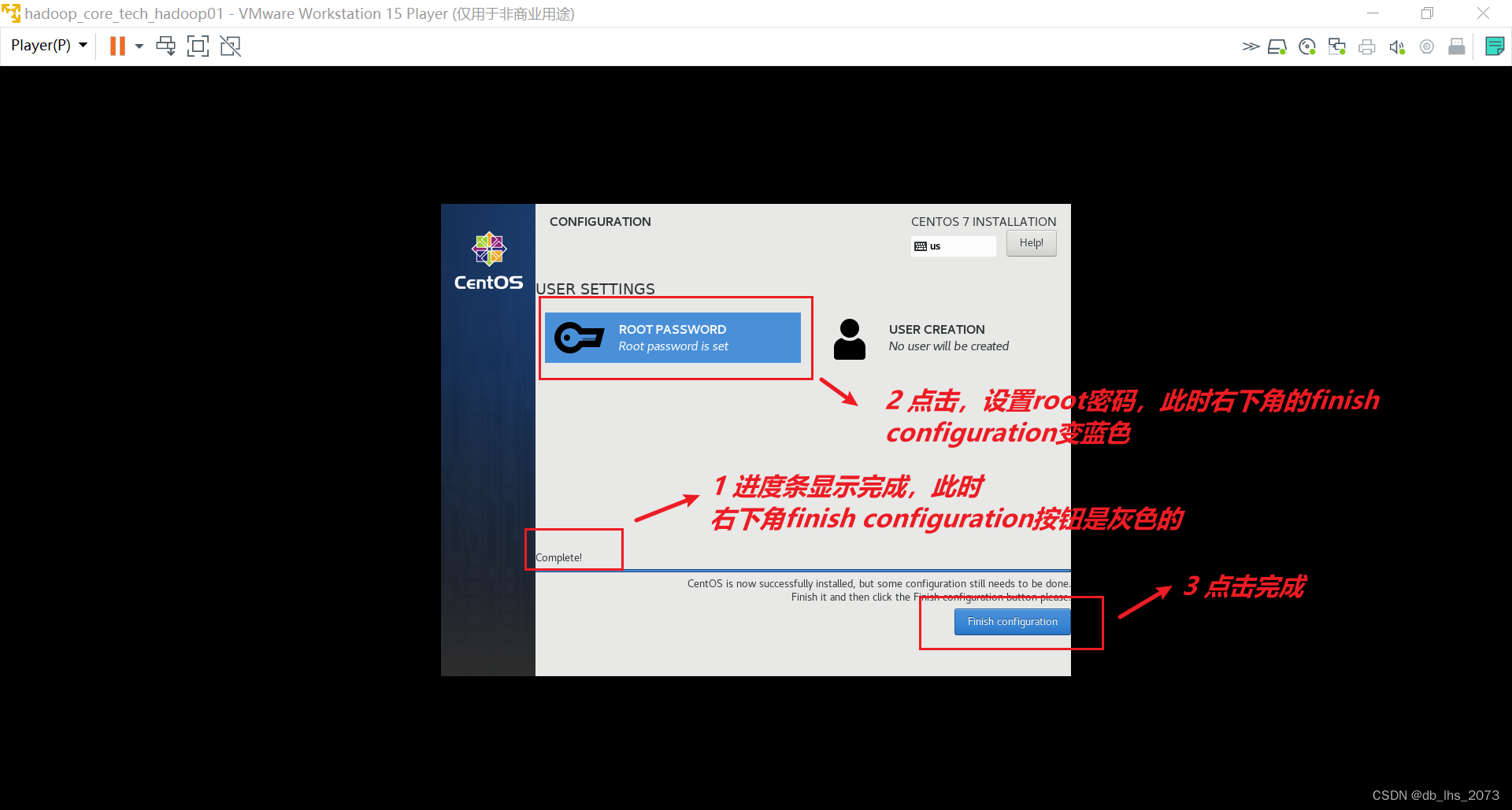

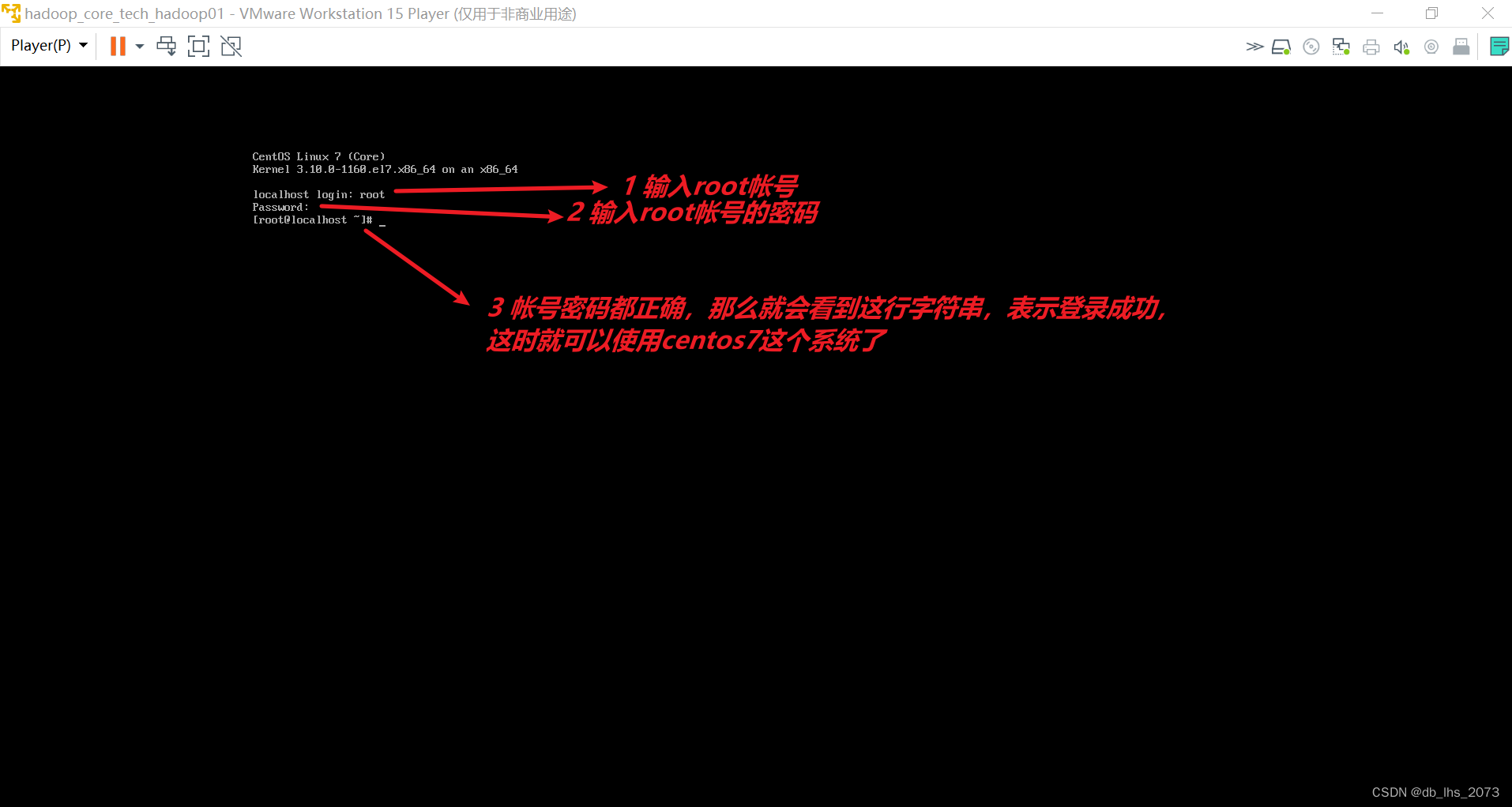
安装成功。
2、Hadoop伪分布式部署的基础准备
1、设置静态IP
Centos7安装好后,默认是通过DHCP协议获取IP的,也就是每次开机,虚拟机的IP可能会发生变化,这种变化对集群来说是致命的,而设置静态IP就可以避免这个问题。
通过执行![]() 这个命令,编辑ifcfg-ens33这个文件,然后按下图说明修改:
这个命令,编辑ifcfg-ens33这个文件,然后按下图说明修改:

重启网卡,并验证是否可以访问外网:

禁止防火墙开机自起

设置主机名
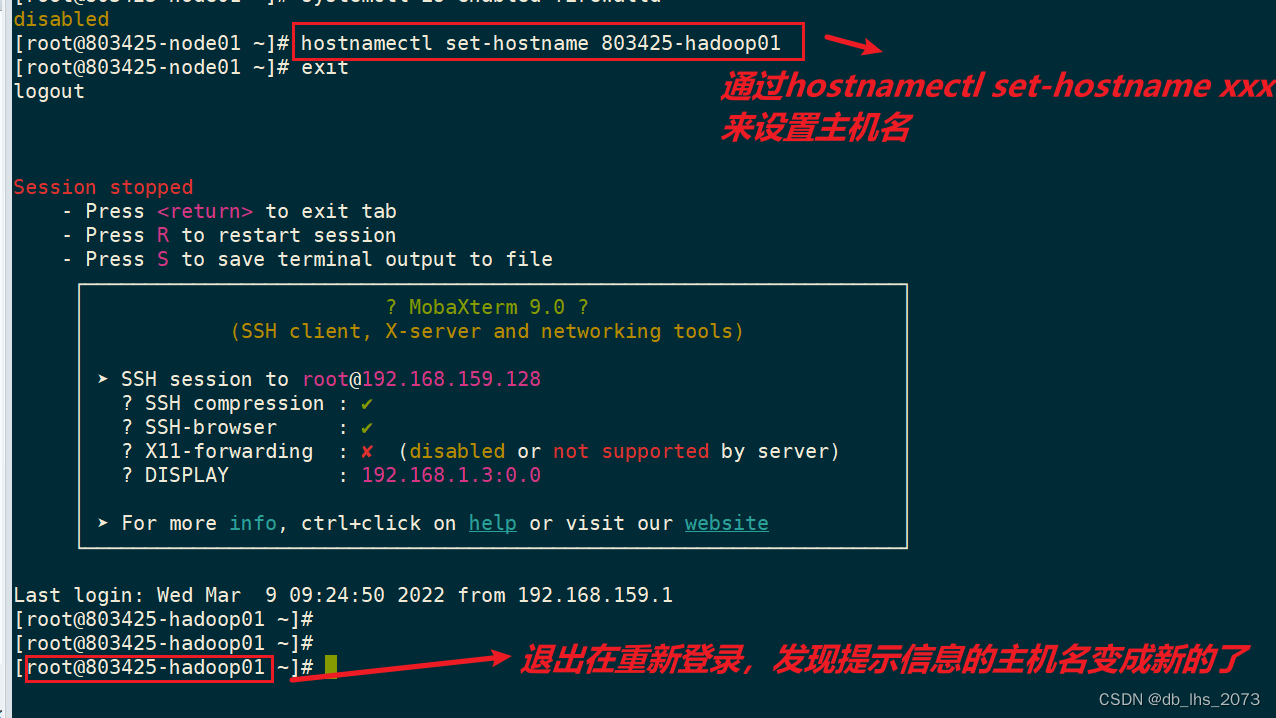
设置主机名和IP的映射
我们知道,网络中,都是通过IP来通信的,故在集群中,如果想要通过主机名通信,则还要设置IP来与之对应,类似于域名要绑定IP。
编辑/etc/hosts这个文件,然后追加一条记录,如下图所示:

3、Hadoop伪分布式部署
1、Hadoop安装
将hadoop-2.7.1.tar.gz上传到Centos7的/usr/local路径:
 解压hadoop-2.7.1.tar.gz:tar -xzvf hadoop-2.7.1.tar.gz
解压hadoop-2.7.1.tar.gz:tar -xzvf hadoop-2.7.1.tar.gz
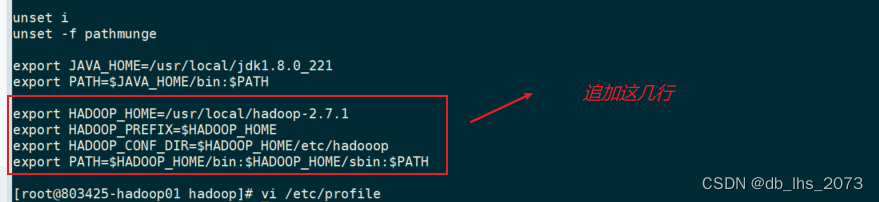
 配置HADOOP_HOME:vi /etc/profile
配置HADOOP_HOME:vi /etc/profile
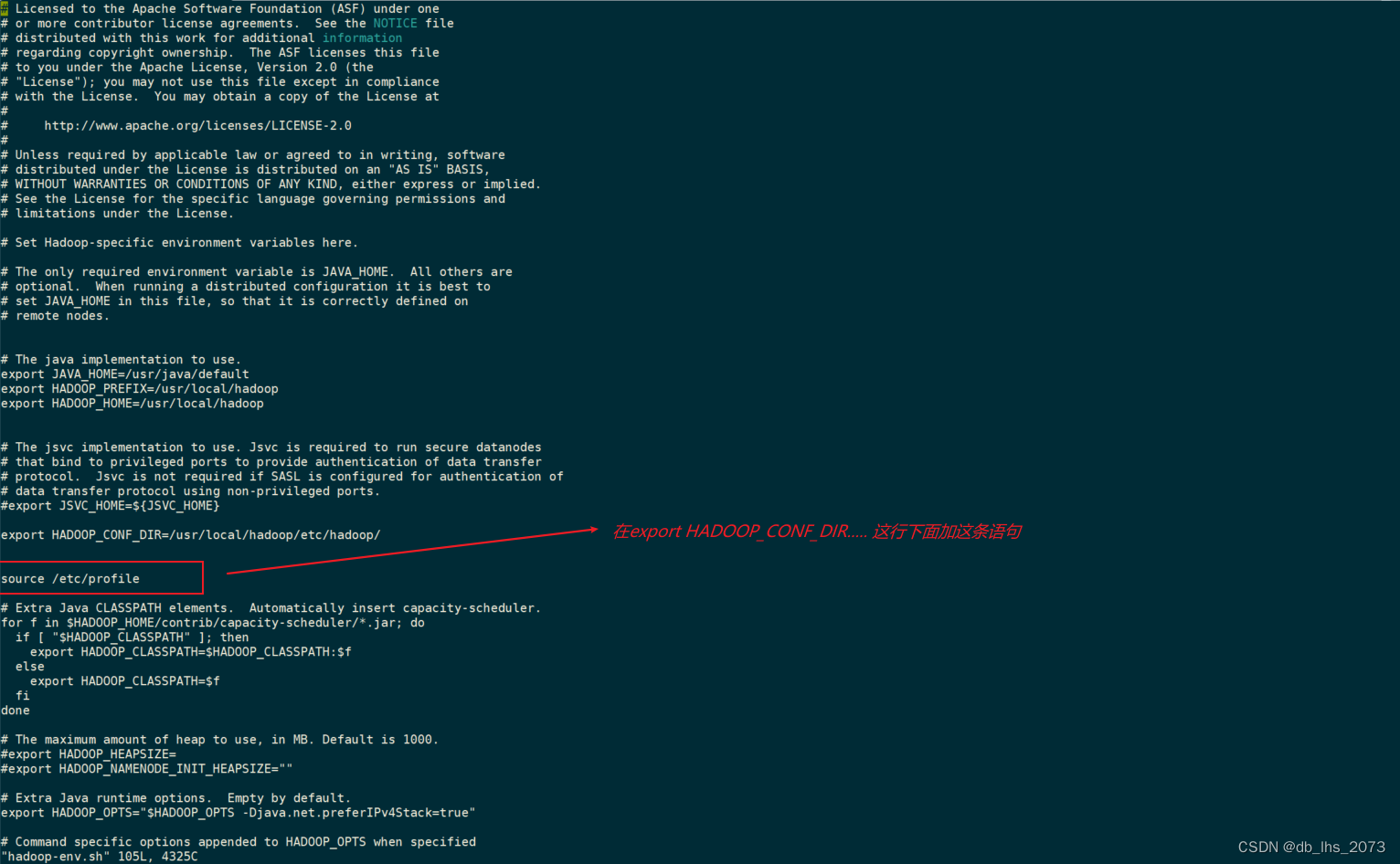
修改hadoop-env.sh文件:cd $HADOOP_HOME/etc/hadoop 然后vi hadoop-env.sh
vi core-site.xml,该配置文件内容如下:

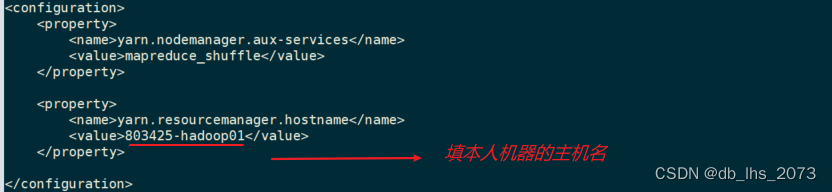
vi yarn-site.xml,该配置文件内容如下:
vi mapred-site.xml,该配置文件内容如下:

vi slaves,该配置文件内容如下:

格式化namenode: hdfs namenode -format

2、Hadoop的启动和停止
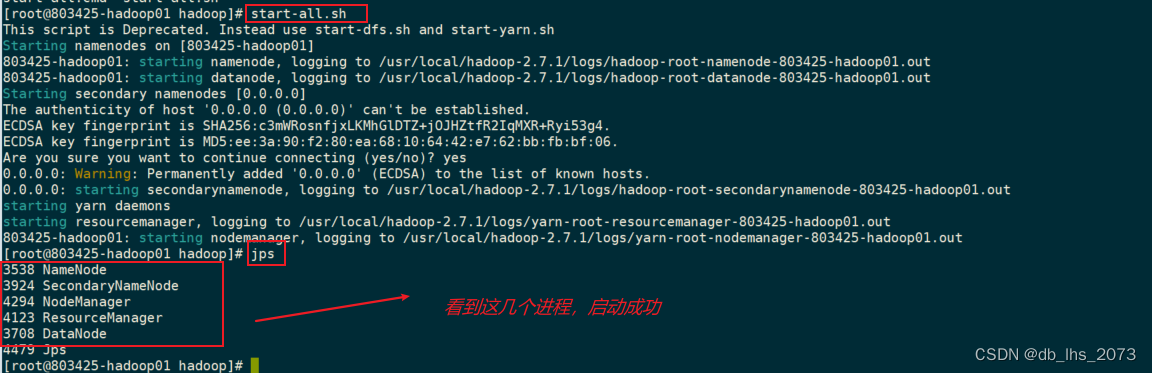
启动: start-all.sh
停止:stop-all.sh
得到下图就布置完成了
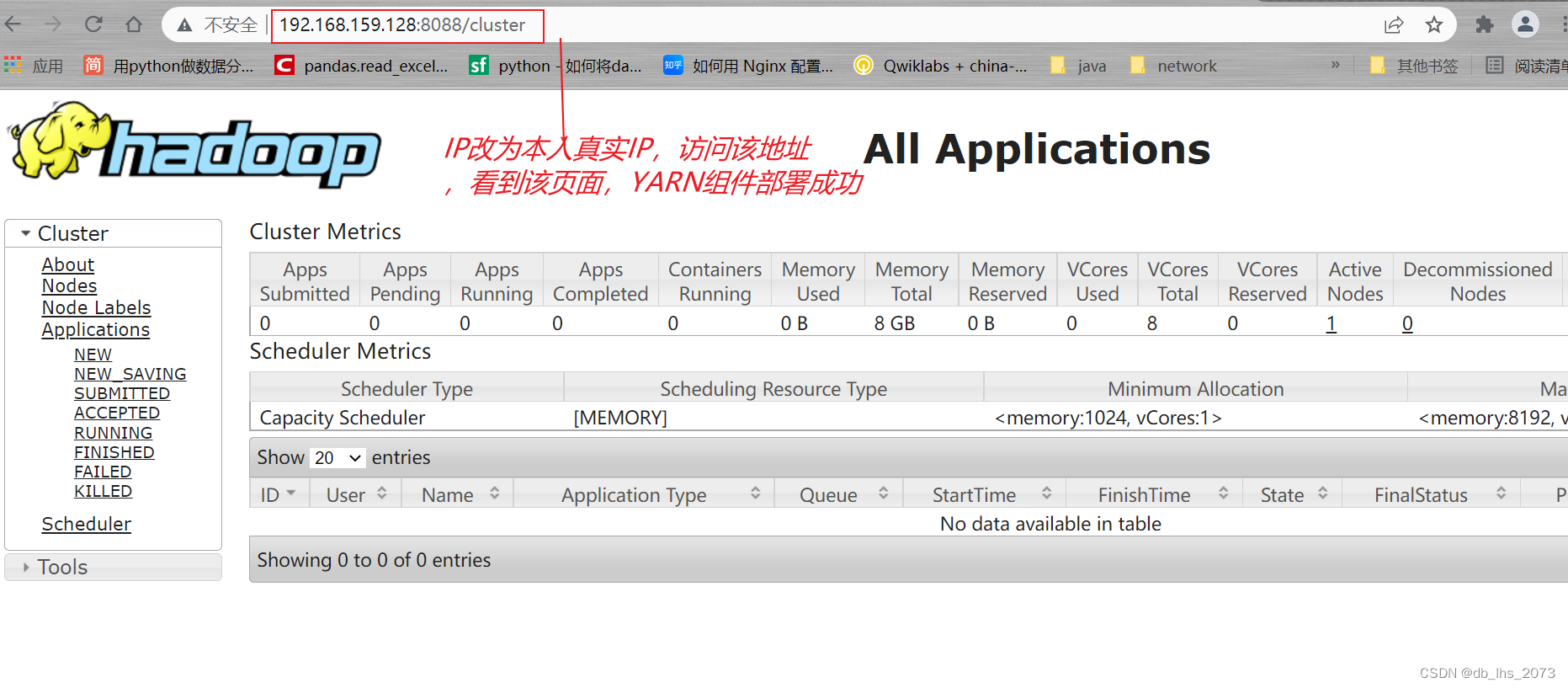
学习到这里就结束了,希望小伙伴们有收获。















 1266
1266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









