







本文采用linux 3.04内核版本。
多核情况下,CPU是同时并发运行的,但是多它们共同使用其他的硬件资源的,因此我们需要解决多个CPU之间的同步问题。每CPU变量(per-cpu-variable)是内核中一种重要的同步机制。顾名思义,每CPU变量就是为每个CPU构造一个变量的副本,这样多个CPU相互操作各自的副本,互不干涉。比如我们标识当前进程的变量current_task就被声明为每CPU变量。
每CPU变量的特点:
- 用于多个CPU之间的同步,如果是单核结构,每CPU变量没有任何用处。
- 每CPU变量不能用于多个CPU相互协作的场景。(每个CPU的副本都是独立的)
- 每CPU变量不能解决由中断或延迟函数导致的同步问题
- 访问每CPU变量的时候,一定要确保关闭进程抢占,否则一个进程被抢占后可能会更换CPU运行,这会导致每CPU变量的引用错误。
显然,每CPU变量的实现不会这么简单。理由:我们知道为了加快内存访问,处理器中设计了硬件高速缓存(也就是CPU的cache),每个处理器都会有一个硬件高速缓存。如果每CPU变量用数组来实现,那么任何一个CPU修改了其中的内容,都会导致其他CPU的高速缓存中对应的块失效。而频繁的失效会导致性能急剧的下降。
每CPU变量分为静态和动态两种,静态的每CPU变量使用DEFINE_PER_CPU声明,在编译的时候分配空间;而动态的使用alloc_percpu和free_percpu来分配回收存储空间。下面我们来看看Linux中的具体实现:
每CPU变量的函数和宏
- DECLARE_PER_CPU(type, name)声明每CPU变量name,类型为type
- DEFINE_PER_CPU(type, name)定义每CPU变量name,类型为type
- alloc_percpu(type)动态为type类型的每CPU变量分配空间,并返回它的地址
- free_percpu(pointer)释放为动态分配的每CPU变量的空间,pointer是起始地址
- per_cpu(var, cpu)获取编号cpu的处理器上面的变量var的副本
- get_cpu_var(var)获取本处理器上面的变量var的副本,该函数关闭进程抢占,主要由__get_cpu_var来完成具体的访问
- get_cpu_ptr(var) 获取本处理器上面的变量var的副本的指针,该函数关闭进程抢占,主要由__get_cpu_var来完成具体的访问
- put_cpu_var(var) & put_cpu_ptr(var)表示每CPU变量的访问结束,恢复进程抢占
- __get_cpu_var(var) 获取本处理器上面的变量var的副本,该函数不关闭进程抢占
每CPU变量的实现原理
静态的每CPU变量
- #define DEFINE_PER_CPU(type, name) \
- DEFINE_PER_CPU_SECTION(type, name, "")
- #define DEFINE_PER_CPU_SECTION(type, name, sec) \
- __PCPU_ATTRS(sec) PER_CPU_DEF_ATTRIBUTES \
- __typeof__(type) name
- #define __PCPU_ATTRS(sec) \
- __percpu __attribute__((section(PER_CPU_BASE_SECTION sec))) \
- PER_CPU_ATTRIBUTES
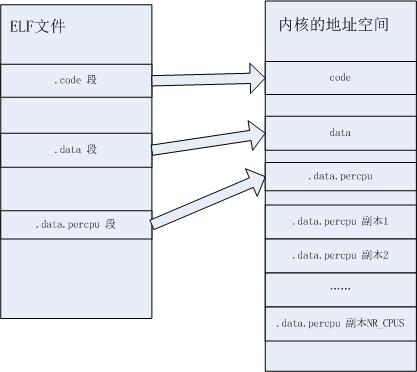
- #define PER_CPU_BASE_SECTION ".data..percpu"
- __attribute__((section(PER_CPU_BASE_SECTION sec)
- void __init setup_per_cpu_areas(void)
- {
- unsigned long delta;
- unsigned int cpu;
- int rc;
- /*
- * Always reserve area for module percpu variables. That's
- * what the legacy allocator did.
- */
- rc = pcpu_embed_first_chunk(PERCPU_MODULE_RESERVE,
- PERCPU_DYNAMIC_RESERVE, PAGE_SIZE, NULL,
- pcpu_dfl_fc_alloc, pcpu_dfl_fc_free);
- if (rc < 0)
- panic("Failed to initialize percpu areas.");
- delta = (unsigned long)pcpu_base_addr - (unsigned long)__per_cpu_start;
- for_each_possible_cpu(cpu)
- __per_cpu_offset[cpu] = delta + pcpu_unit_offsets[cpu];
- }
备注:分配内存以及复制.data.percup内容的工作由pcpu_embed_first_chunk来完成,这里就不展开了。__per_cpu_offset数组中记录了每个CPU的percpu区域的开始地址。我们访问每CPU变量就要依靠__per_cpu_offset中的地址。
动态每CPU变量
了解了静态的每CPU变量的实现机制后,就很容易想到动态的每CPU变量的实现方法了。实际上,在setup_per_cpu_areas的时候,我们会为每个CPU都多申请一部分空间留作动态分配每CPU变量之用(一个场景就是内核模块中的每CPU变量)。相对于静态的每CPU变量,我们需要额外管理内存的分配和回收。
每CPU变量的访问
- #define per_cpu(var, cpu) \
- (*SHIFT_PERCPU_PTR(&(var), per_cpu_offset(cpu)))
- #define per_cpu_offset(x) (__per_cpu_offset[x])
- <pre name="code" class="cpp" style="margin-top: 4px; margin-right: 0px; margin-bottom: 4px; margin-left: 0px; background-color: rgb(240, 240, 240); ">#define SHIFT_PERCPU_PTR(__p, __offset) ({ \
- __verify_pcpu_ptr((__p)); \
- RELOC_HIDE((typeof(*(__p)) __kernel __force *)(__p), (__offset)); \
- })
- <pre name="code" class="cpp" style="margin-top: 4px; margin-right: 0px; margin-bottom: 4px; margin-left: 0px; background-color: rgb(240, 240, 240); ">#define __verify_pcpu_ptr(ptr) do { \
- const void __percpu *__vpp_verify = (typeof(ptr))NULL; \
- (void)__vpp_verify; \
- } while (0)
- # define RELOC_HIDE(ptr, off) \
- ({ unsigned long __ptr; \
- __ptr = (unsigned long) (ptr); \
- (typeof(ptr)) (__ptr + (off)); })















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









