




大家好,我是华山自控编程朱老师,今天给大家介绍下我之前设计的入门项目——工件正反面识别及角度测试系统
系统功能
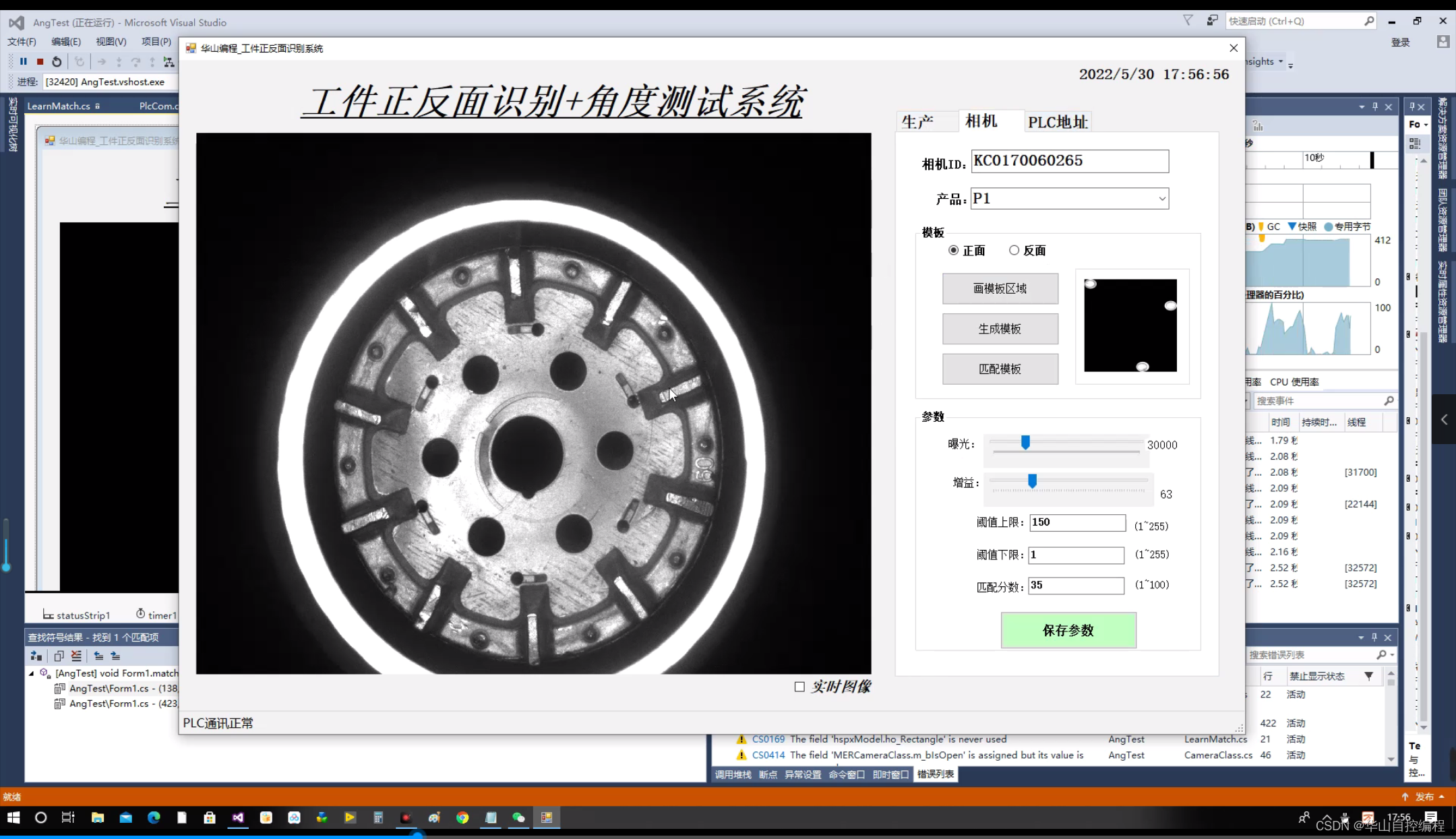
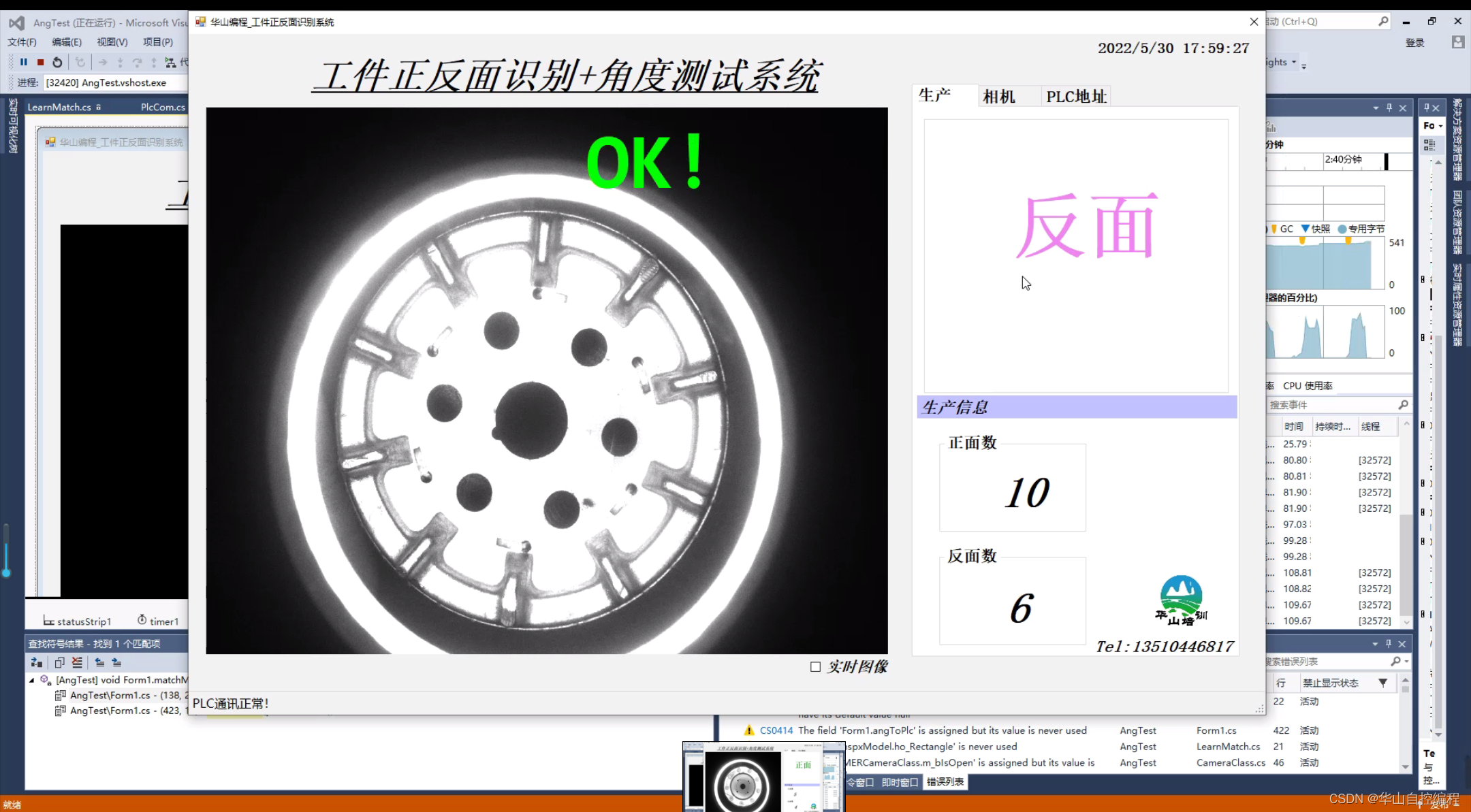
首先,系统的功能包括识别工件正反面,测试工件旋转角度。这些任务是由PLC来控制工件传送、启动拍照以及上位机。当拍照完成后,数据会被传送给PLC。
硬件配置
系统的硬件配置包括相机和PLC。大恒U2、U3以及千兆网相机均适用于该系统。而三菱全系列PLC也都能够适配。
综上所述,这个系统可以实现自动化的工件识别和测试,并且可以与多种不同型号
 该系统由朱老师设计,功能包括工件正反面识别和角度测试,使用PLC控制与相机配合。硬件涉及相机和三菱PLC,软件采用C#和Halcon。项目适合初学者,涵盖C#编程、PLC通讯和机器视觉基础知识,提供上位机编程入门学习路径。
该系统由朱老师设计,功能包括工件正反面识别和角度测试,使用PLC控制与相机配合。硬件涉及相机和三菱PLC,软件采用C#和Halcon。项目适合初学者,涵盖C#编程、PLC通讯和机器视觉基础知识,提供上位机编程入门学习路径。
大家好,我是华山自控编程朱老师,今天给大家介绍下我之前设计的入门项目——工件正反面识别及角度测试系统
系统功能
首先,系统的功能包括识别工件正反面,测试工件旋转角度。这些任务是由PLC来控制工件传送、启动拍照以及上位机。当拍照完成后,数据会被传送给PLC。
硬件配置
系统的硬件配置包括相机和PLC。大恒U2、U3以及千兆网相机均适用于该系统。而三菱全系列PLC也都能够适配。
综上所述,这个系统可以实现自动化的工件识别和测试,并且可以与多种不同型号

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+







