







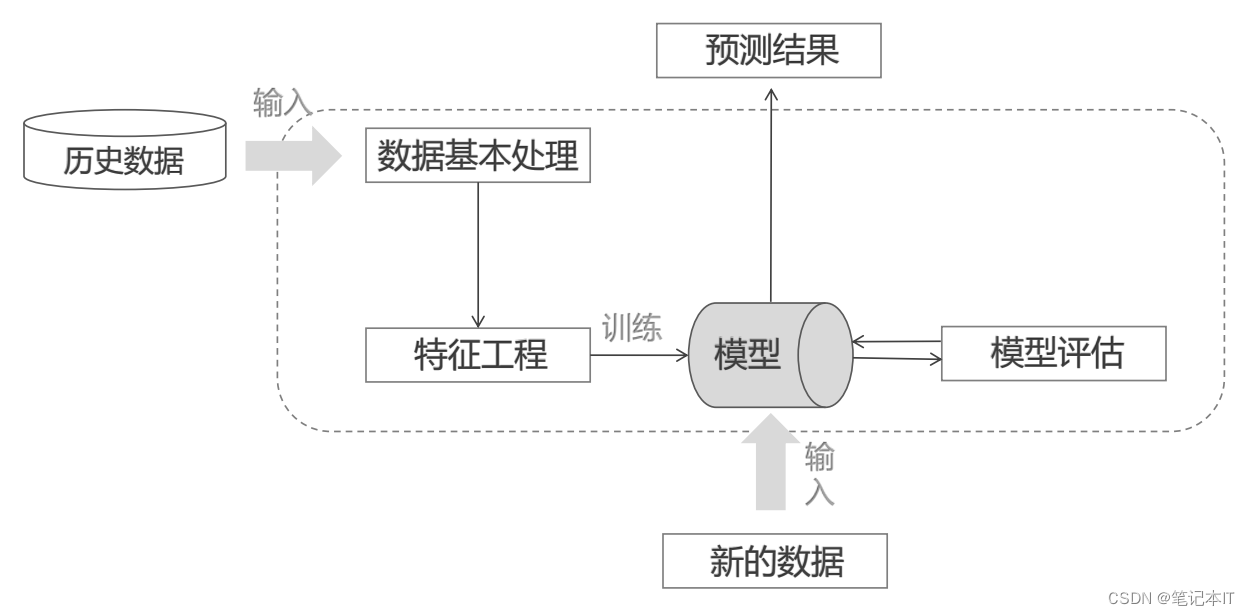
实现流程
数据输入->数据基本处理->特征工程->训练->模型评估->新数据输入->预测结果
数据类型:
类型一:特征值+目标值
类型二:只有特征值
一、数据基本处理
达到的标准

二、特征工程

三、机器学习(模型)分类:
监督学习
定义:有目标值
分类:回归问题、分类问题
回归算法:线性回归、岭回归
分类算法:K-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归、神经网络
无监督学习
定义:意味着输入数据没有被标记,也没有确定的结果(无具体目标值)。样本数据类别未知,需要根据样本间的相似性对样本集进行分类(聚类)试图使类内差距最小化,类间差距最大化。
聚类算法:K-means、PCA降维手段
半监督学习
定义:可以简单理解为一部分数据有目标,而一部分数据无目标。主要使用于监
督学习效果不能满足需求时,就使用半监督学习来增强学习效果。
强化学习
定义:主要用来自动进行决策,并且可以做连续决策。也就是说,整个过程都是一个
动态的,上一步数据的输出是下一步数据的输入。
四、模型评估
定义: 模型评估是模型开发过程不可或缺的一部分。它有助于发现表达数据的最佳模型和所选模型将来工作的性能如何。
模型评估主要是评估模型误差的大小。误差主要分为:
- 经验误差:在训练集上面的误差
- 泛化误差:对未知数据上的误差
保留测试集的方法:
◆ 留出法
◆ K折交叉验证
◆ 自助法
留出法:
每层数据随机抽取N成训练集与随机抽取M成测试集,这样做若干次,重复实验,取平均值
K折交叉验证法:
分十份,每次留一份作为测试集【数据量少时非常有效,数据量大时对算力要求比较高】
自助法:
初始化数据集D,共有10个元素。 D=[1,2,3,4,5,6,7,8,9,10]
训练集D’:从D中随机有放回的抽取10个。比如: D’=[2,2,1,1,5,4,7,8,9,10]
- 会有一些数不一定能够选择到
- 假设一共为m个数,某一个数被选到的概率为1/m
- 该数没有被选到的概率: (1-1/m)
- 一共选了m次,没选到的概率总共为: (1-1/m)**m
- m趋向于无穷的,就会有一个极限值为 1/e=0.368
这样即可保证:
1.原本数据集D、训练集与测试集的样本个数都可一致
2. 初始数据D 中大概会有36.8%的数据没在训练集 D’ 中出现。同理可得,初始数据集D中,约有36.8%的数据没在测试集中出现
自助法适用于:数据集较少、难以有效划分测试机与训练集
缺陷:分布偏差引来的估计偏差。
训练集(训练模型)+测试集(模型评估)+验证集(调参)
性能度量
- 回归问题:

- 分类问题
方案一
错误率与精准率

缺陷:(只能判断 是 与 不是)
数据集{0,1,2,3,4,5,6,7,8,9,10} ->> =5正确的,!=5的时候不正确 ->> 错误率=10/11
方案二
查准率与查全率:
用一个例子说明:
现有模型预测:
100条新闻,60条你真正感兴趣的,40你真正不感兴趣的。
平台推送的结果:预测70条你感兴趣的,预测30条你不感兴趣的

查准率:他推送的广告(预测)有多少比例是你真的感兴趣的
查全率:你真正感兴趣的广告有多少真的被预测成功了
模型评估:
模型评估用于评价训练好的模型的表现效果,其表现效果大致可分为两类:欠拟合、过拟合。
















 2544
2544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











