









背景
之前我在团队中一直负责的是数据开发的相关工作。因此,对于后台系统开发并没有很多工作实践。不过近期我也着手做了一些后台开发的相关工作,在实践过程中使用到了缓存,在实践一段时间后,在此文中对我使用缓存的实践做一总结。
实际上,我们的业务场景非常简单,没有很高的并发以及时延要求。因此,在设计缓存时,我们也没有把问题复杂化,方案设计的很简单。不过也并不影响我们进一步的思考缓存的使用。本文主要总结的是在工作实践这一场景下更多的联想思考,包括为什么要使用缓存、我们的缓存方案选择以及使用缓存中可能要注意的问题。一篇文章肯定远远总结不完我们对于缓存的实践,因此后续还可能会继续写文章讨论一这话题。
业务场景
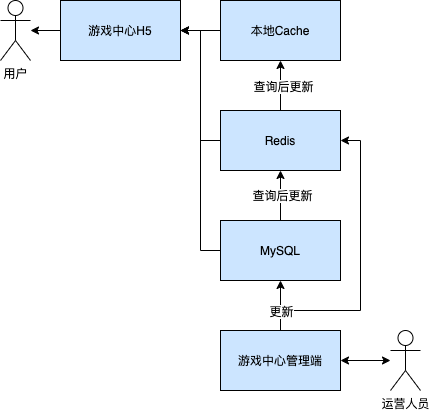
我当前在做的其中一个工作是游戏中心的后台开发。所谓游戏中心,对于外部来说其实就是一个H5页面,该页面个性化的展示了我们IEG的各个游戏,之后规划会将该H5页面嵌入到一些中小媒体的APP中,用于做腾讯游戏的推广和分发。目前我们系统的QPS大约只有500,不过我相信随着后续媒体的不断接入,QPS会持续升高的。
游戏中心的前端页面是这样的:
该前端页面主要是调用我们后台的两个接口:游戏列表、游戏详情。
后台的这两个接口会去查询到相应的数据并返回给前端做展示。因此,对于前端页面来说,只有对后台数据的读取,没有写入。
后台数据的写入是通过游戏中心的管理端进行的。
整个业务示意如图所示:

为什么要使用缓存
我们的后台服务在查询数据时使用到了缓存,那么,我们为什么要使用缓存呢?
其中有三点原因:
- 减轻数据库的压力
具体的例子来说,我们使用Redis做缓存。一个Redis实例可以有万级的吞吐量,而一个MySQL实例大概是千级的吞吐量。在业务请求并发量很高的情况下,如果每次查询数据都要到MySQL数据库里去查,那么MySQL会压力非常大。极端情况下,有可能会导致MySQL挂掉。就算我们MySQL可以堆很多资源,从成本角度来说,也不如加上缓存。 - 提升用户的体验
缓存使用的是计算机内存进行存储,而数据库使用的是计算机的磁盘。从读写性能上来说,当然缓存的读写性能远优于数据库。因此,在查询数据的时候,缓存的时延要远低于数据库查询的时延。对于用户来说,就可以有更好的使用体验。 - 提高系统并发量
如前面所述,缓存的并发量远大于数据库的并发量。使用缓存可以有效提高系统的请求并发量。
实现方案的选择
缓存设计模式主要有三种:Cache Aside、Read/Write Through和Write Behind Caching。
这里就不一一详细说明了,简单来说的话,这三者就是更新数据库的时机有所不同:
Cache Aside:在更新缓存的同时更新数据库。
Read/Write Through:更新缓存后,由缓存来更新数据库。
Write Behind Caching:更新缓存后,缓存定时异步更新数据库。
我们实际的方案设计中有Cache Aside的设计思想,但是也不完全一样。
方案的思考
方案一
第一种方案的操作示意如图所示:
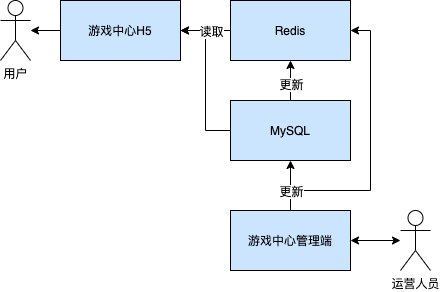
外部会先从Redis中读取数据,如果读取到了数据则直接返回。若没有读取到数据,则会去MySQL中读取相应数据,并同时将MySQL中读取到的数据更新至Redis中。若MySQL中也读不到该数据,则报错返回。
在MySQL数据发生更新时,会同时将数据更新到Redis中,并设置Redis数据的过期时间。
外部读取数据时的流程如下图所示:
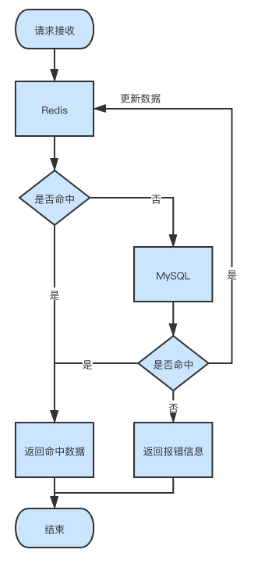
该方案的优缺点如下
优点:
- 数据的更新非常及时,运营人员操作更新数据后,外部获取到的数据也会立即更新。
- 一般情况下不会出现数据不一致的情况。
缺点:
- 若发生缓存雪崩或缓存击穿的情况,那么就有导致MySQL出问题的风险。
- 相较于本地Cache,读取Redis的数据还是需要一定的网络IO。
方案二
第二种方案的操作示意如下图所示:
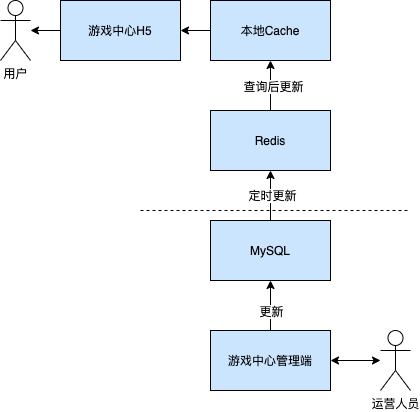
这里使用了定时更新的方式,运营人员通过管理端往MySQL中写数据这块不用赘述。
MySQL中的数据会每隔3分钟往Redis中刷新数据。而外部在请求数据时,首先会访问本地的Cache,如果本地Cache中没有该条数据,则会去Redis中进行查询,并同时会将该条数据更新至本地Cache(本地Cache会设置过期时间)。而若Redis中也查询不到该条数据,那么我们就会返回报错信息,不会再到MySQL中进行查询。
外部读取数据时的流程如下图所示:
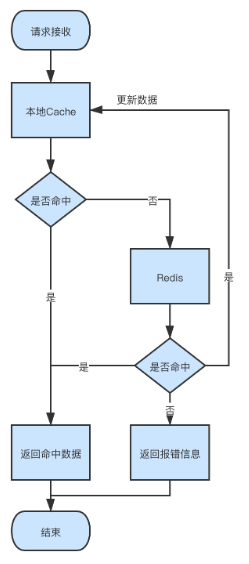
该方案的优缺点如下
优点:
- 实现很简单,不需要访问数据库,只需要写一些定时任务执行。
- 不用访问数据库,可以完全避免缓存雪崩与缓存击穿所对数据库会带来的风险。
- 使用本地Cache,会比访问Redis获取数据更快一些。
缺点:
- 数据的更新延迟很大,完全不适用对数据及时性要求高的系统。
- 使用本地Cache,若有多节点对外提供服务,很可能会有数据不一致的问题。
方案三
第三种方案的操作示意如下图所示:
方案三在方案一的基础之上增加了本地Cache缓存。
该方案在外部读取数据时的流程如下图所示:
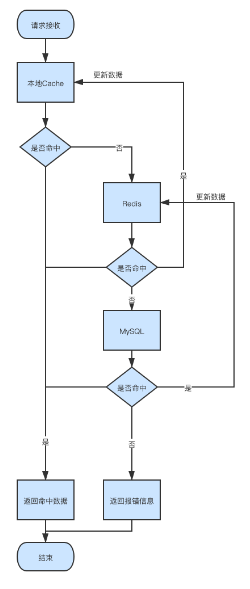
该方案的优缺点如下
优点:
- 使用本地Cache,会比访问Redis获取数据更快一些。
- 每次有更新都会非常及时的同步到外部访问的数据。
缺点:
- 若发生缓存雪崩或缓存击穿的情况,那么就有导致MySQL出问题的风险。
- 使用本地Cache,若有多节点对外提供服务,很可能会有数据不一致的问题。
缓存实现方案的对比
| 方案 | 数据一致性 | 请求时延 | 数据更新时机 | 方案风险 |
|---|---|---|---|---|
| 方案一 | 没有不一致的风险 | Redis的IO时延 | 立即更新 | 缓存雪崩/击穿时,会导致MySQL风险 |
| 方案二 | 有不一致的风险 | 内存读取时延 | 不会立即更新 | 缓存雪崩/击穿时,不会导致MySQL风险 |
| 方案三 | 有不一致的风险 | 内存读取时延 | 立即更新 | 缓存雪崩/击穿时,会导致MySQL风险 |
业务场景下的缓存实现方案选择
通过上面的缓存实现方案对比,基本上我们可以明确三种不同的方案的优劣势。
最终我们的业务选择了方案二来进行具体的实现,原因是:
- 我们当前业务有几个模块共用了同一个数据库,方案二可以完全保证数据库的稳定。
- 当前业务对请求时延有要求,但对数据一致性没有什么要求。
- 当前业务场景下,对数据的更新时机没有高要求,就算数据变更后隔段时间再更新至用户侧,也不会对业务有影响。
当然,之后如果业务的要求有调整,我们后台这边的缓存策略也会做相应的调整的。
使用缓存可能会带来的问题的思考
我们的业务中引入了缓存机制,是为了有效的利用缓存的一些优势,比如减轻数据库的压力、提升用户的体验、提高系统并发量。
但是,缓存的引入也可能会带来一些新的问题。虽然我们当前的业务场景较为简单,可能不会碰到缓存带来的问题,但是也不影响在该场景下的一些延伸思考。接下来,就从几个方面来思考一下缓存可能会带来的问题。
数据不一致
首先,只要引入了缓存机制,那么就不可避免的会要考虑到数据一致性的问题。我们先在这里明确一下数据一致性的定义:
- 缓存中存在数据时,缓存中的数据需要与数据库中的数据一致。
- 缓存中不存在数据时,数据库中的数据需要是最新的数据。
如果以上两点有其中一点不满足,那么我们就认为数据是不一致的了。因此,我们在使用缓存的过程中要思考的问题就是如何去保证数据的一致性。
缓存可以分为两种类型:读写缓存以及只读缓存。接下来我们就以上述方案一为例分别对这两种类型缓存进行数据一致性的分析:
读写缓存
读写缓存不仅可以被读取数据,还可以在缓存中进行增删改操作。因此,使用读写缓存时,一般会有两种数据写回数据库的方式。
一种是外部只操作缓存,然后每隔一段时间将缓存数据写回到数据库一次。这种方式叫做异步写回策略。一般适用于非核心的业务数据。因为如果在缓存数据写回到数据库之前就挂了,那么这些数据的变更记录也就永久丢失了。
另一种是外部在更新缓存的同时,也会同步的更新数据库。这种方式叫做同步直写策略。对于核心的业务数据我们就应该用这种策略。
对于该策略来说,要保证数据的一致性,那么就必须保证缓存和数据库更新的原子性,也就是说,如果要更新成功就都成功,如果更新失败就都回到更新前的状态。只有这样才能保证数据的一致。在这样的前提下,我们具体分别通过增、删、改操作来进行描述。
增:无论是先更新缓存还是先更新数据库,都不会影响到数据的最终一致性。
删:若先更新缓存,后更新数据库。假设操作A更新缓存完成后,且更新数据库前,这是如果有操作B对缓存该数据进行查询,那么就可能会出现将数据库的数据重新刷回缓存的情况,之后A再更新数据库,就会导致最终的数据不一致。若先更新数据库,后更新缓存。那么就不会影响到数据的最终一致性。
改:无论是先更新缓存还是先更新数据库,都不会影响到数据的最终一致性。
可以看到,无论我们是进行增、删、改的哪个操作,最有利的更新策略就是先更新数据库后更新缓存,这样就不会造成数据不一致的问题。
只读缓存
只读缓存与读写缓存不同,对于读操作和删操作来说是一样的逻辑,但是对于增操作和改操作则不同。
此处读操作和删操作不再赘述,只看一下只读缓存的增操作和改操作。
增:对于只读缓存,在做增操作时,只需要对数据库进行操作,也就是只需要在数据库中增加新的数据即可,在下次外部访问缓存时会自动将缓存更新。
改:在进行改操作时,我们有两步需要做,一个是将缓存中对应的数据设置为失效,一个是更改数据库中的数据。若我们先更新缓存,再更新数据库,则可能会碰到数据不一致的问题,原因这里不再赘述。若我们先更新数据库,再更新缓存,则可以保证数据的一致。只不过是数据更改的生效会稍稍慢一些。
对于只读缓存来说,我们也是要保证缓存和数据库操作的原子性。同时,最优的策略依然是先更新数据库后更新缓存。
整理这些情况,如表所示:
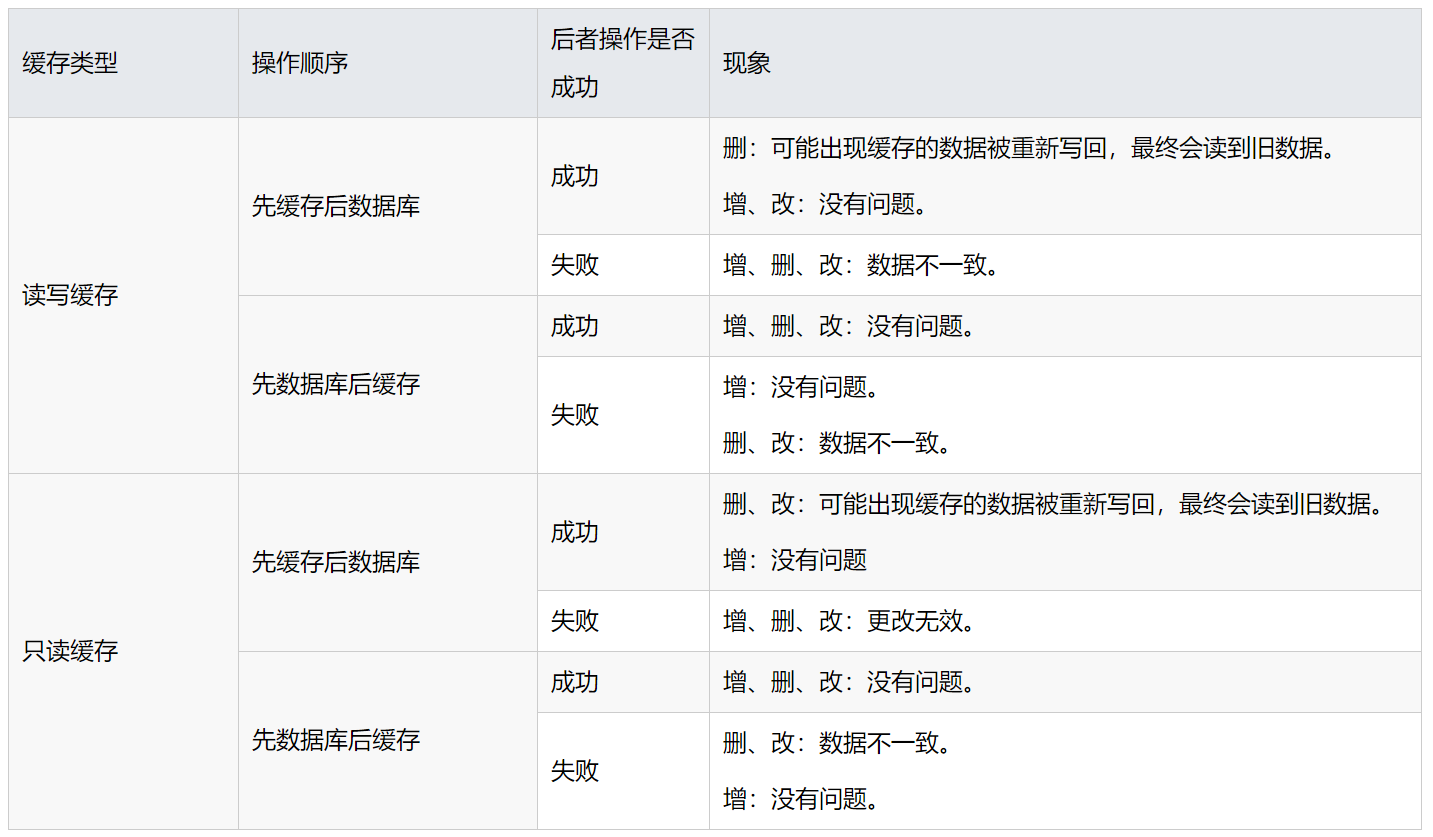
上表看着复杂,实际上整体来看,无论是读写缓存还是只读缓存,我们首先要保证的是缓存和数据库操作的原子性,否则就可能出现数据不一致的情况。同时,我们在进行数据操作时,尽可能考虑优先操作数据库后操作缓存,这样会极大程度的保证数据的一致性。
缓存雪崩
所谓缓存雪崩,指的是缓存在一段时间内无法对外提供服务,这样导致的结果就是会突然有大量的外部请求直接访问到后台数据库。而我们都知道,后台数据库的吞吐能力一般来说都没有缓存大,如果本来应该是缓存的请求,全部都打到数据库上,则很有可能会出现数据库卡顿的情况,甚至可能会引起数据库宕机。
如图所示:
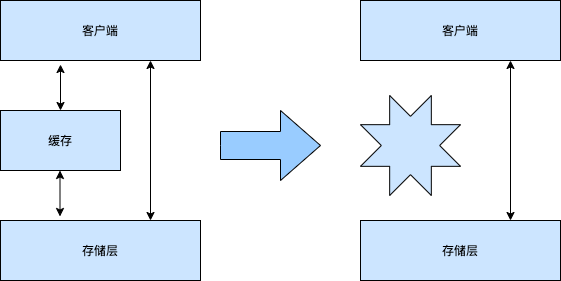
一般来说,会有两种情况会导致缓存雪崩:
第一种,就是缓存服务真的宕机了。这种情况,我们一般有三种手段来进行处理。
- 服务熔断
所谓服务熔断,是一种比较暴力的解决方式,也就是在缓存服务宕机时,让客户端的请求不再打到缓存服务上,而是直接返回我们预设的默认值,或者干脆直接返回报错信息。以避免因为缓存服务的宕机而导致的后续连锁反应。这样,当缓存服务恢复正常时,我们也可以快速的将服务恢复到正常状态。
如图所示:
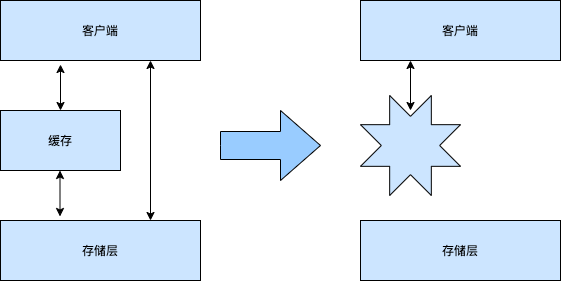
- 服务限流
上面讨论的服务熔断的处理方式或许太过粗暴,会直接导致用户的请求都暂时受到影响。我们还可以用另一种服务限流的方式来进行缓存宕机后的处理。
所谓服务限流,指的是由前端服务限制每秒请求的个数,将每秒请求的个数限制在数据库所能承受的数量内,那么就算是每个请求都直接访问数据库也不会导致数据库出问题了。
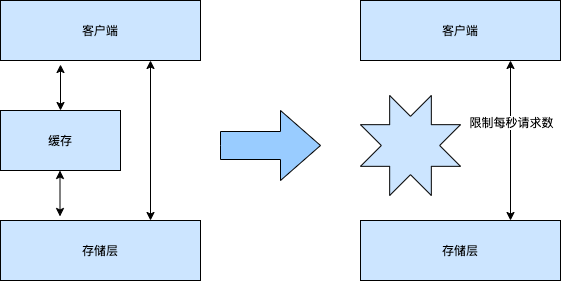
- 服务降级
还有一种比较合理的处理方式是服务降级。
所谓服务降级,指的是在缓存服务宕机的情况下,只对核心接口请求进行处理,而将非核心接口的请求直接返回。这种处理方式更能够考虑到业务的需求。
前面就考虑完了在缓存服务宕机所引发的缓存雪崩的情况下该如何去处理。
另一种会引起缓存雪崩的场景,是大量的缓存同时过期。这时,虽然缓存服务没有问题,但是由于大量的请求都查询不到对应的缓存数据,也会一下子有大量的请求打到数据库上的。像这种情况所引起的雪崩是可以通过合理的设置缓存过期时间来避免的。
具体来说,就是我们在设置缓存过期时间时,不要将缓存过期时间设置为一个固定值,而应该将缓存时间设置为一个固定值加一个上下浮动的随机数。这样就能够比较好的避免因缓存同时过期而导致的缓存雪崩问题。
对于我们的系统而言,Redis缓存是存放在腾讯云上的,基本上可以放心使用不用担心雪崩的问题。但给缓存设置一个合理的过期时间还是非常重要的。
缓存击穿
缓存击穿有别于缓存雪崩,指的是由于某个热点数据的过期,而导致在同一时间有大量请求打到数据库上进行查询的情况。
如图:
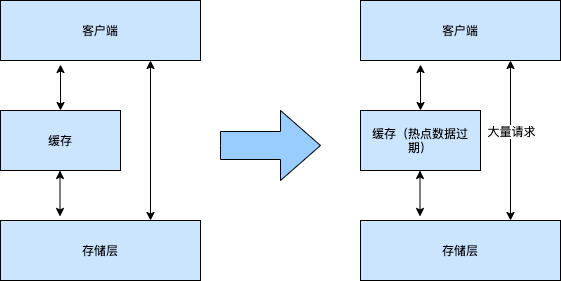
对于这种情况的处理比较简单,就是我们要判别哪些数据在缓存中属于热点数据,这些数据很可能是每次请求都会去访问的。这种数据就不要设置过期时间了,让这些数据长期在缓存中,只有在数据库更新的同时再主动去更新这些缓存数据即可。
对于我们的系统来说,比如首页的游戏列表,这样的数据我们都是长期在缓存中保存的,因为这些数据只有可能被更新,而不会被淘汰。
缓存穿透
缓存穿透指的是外部请求的数据既不在缓存中,也不在数据库中。这种情况更为严重,因为会使缓存和数据库同时承受很大的压力。
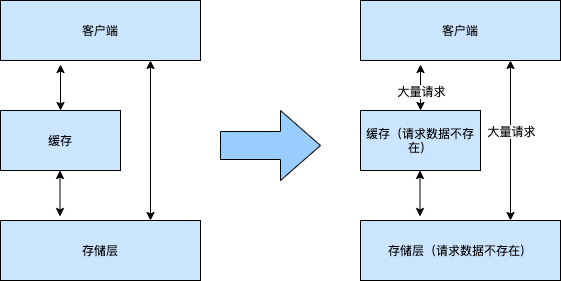
可能会导致缓存穿透的原因有两个:
- 外部黑客的恶意攻击
- 对应数据被误删除
针对缓存穿透的情况,这里可以考虑三点:
- 接口做严格的校验
这是预防的策略,防患于未然,外部之所以可以对系统进行恶意攻击,访问到不存在的数据,是因为前置的接口权限校验以及参数校验做的不够严谨导致。 - 给数据设置缺省值
在数据被误删除的情况下,一个紧急的处理办法就是在缓存中写入对应数据的缺省值。在这种情况下起码可以对数据库做到保护作用。 - 使用布隆过滤器前置值存在与否的查询
这种是比较优雅的预防以及解决缓存穿透的方案。我们在数据被写入到数据库之前先在布隆过滤器做一个标记,在缓存中查询不到数据时,我们就可以先查询布隆过滤器,若未查到标记的数据,那么我们也就可以直接给请求做返回处理了,从而保护了数据库免于被大量无效请求访问。
当前我们的系统隔断了对数据库的访问,因此也就不会出现缓存穿透的问题。不过,严格的接口校验也是必不可少的。另外,如果我们后续可以在Redis中做一个布隆过滤器的话,就可以用方案三来替代掉方案二了。
总结以上缓存问题以及对应的解决方案如下表:

总结
本文从近期业务使用的缓存场景出发,首先简单介绍了我们的业务场景,然后描述了我们为什么要使用缓存,接着对方案的选择过程做了记录,最后分析了我们之后使用缓存过程中可能会遇到的问题以及对应的解决方案。一篇文章肯定远远总结不完我们对于缓存的实践,因此后续还可能会继续写文章讨论一这话题。















 1335
1335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









