









前言
编程语言有面向过程和面向对象之分,因此编程风格也有所谓的面向过程的编程和面向对象的编程,而且语言的性质不会限制编程的风格.
这里主要说一下面向过程的编程.
“面向过程”(Procedure Oriented)是一种以过程为中心的编程思想。
C语言是面向过程的编程语言,但是依然可以写出面向对象的程序,同样C++也当然可以写出面向过程的程序咯。
如果我们把所有的程序代码都写在一个main函数里面,那么这个程序显然会显得很不和谐吧。理想一点的做法是我们把一些看起来和main函数逻辑上关联可以独立分开的、在高层次的抽象上有通用的操作的代码分离出来,形成调用函数。而这即是面向过程的编程。
面向过程的编程,即将函数独立出来的好处有三:
1、以一连串函数调用操作取代重复编写相同的程序代码,可以使程序更易读。
2、可以在不同的程序中使用这些高层次抽象封装的程序,比如之前的SICP中的抽象编程中的例子比比皆是。
3、可以根据功能和过程将项目分块,更容易将工作协作给小组team完成。
一、如何编写函数(How to write a function?)
以一个例子驱动讲解:
这样一个关于fibonacci数列的程序,用户询问概数列的第几个元素是什么,程序回答出该问题。
显然计算fibonacci数列指定元素大小的这部分可以抽象出函数。如何编写这个函数呢?
首先需要了解函数定义包括的内容:
四部分:
1、返回类型:即函数执行完如有需要返回给调用者的数据,其数据的数据类型
2、函数名:即是函数的名字,建议名字跟函数功能相关
3、参数列表:即是函数和调用者之间如果需要数据连接,接受调用者传递的数据,则是=需要有参数列表
4、函数体:即是函数的主体执行部分
具体各部分的含义就不再多说了吧。。。不懂的请自行google,毕竟不可能把所有的东西都说了。
是使用函数的时候需要注意的是函数必须先被声明,然后才能被调用。这个道理很明白,就是你必须要想别人说你的名字,然后别人需要你的帮助的时候才能找到你(根据你的名字)。
函数的声明让编译器得以检查后续出现的函数的调用方式是否正确(参数的个数、类型是否匹配etc…)。函数声明只需要声明函数原型即可,不需要函数体部分,但必须要函数返回类型,函数名,参数类表(空是void)。
具体的如何fibonacci数列程序的语句就不再写了,这个看了fibonacci数列原理就很容易写出来。
在编写函数体的时候注意在函数的最后写上return语句,返回给调用者期待的数据。
同时我们需要说的还有一个关于程序健壮性的问题,即是我们编写的函数虽然是逻辑上对的,但是面对用户千奇百怪的操作,他很有可能会挂掉。
这就需要我们去处理这些看起来不合理的操作,毕竟我们的程序是要为用户服务的,我们必须站在大多数的用户的角度考虑我们的程序将要遇到什么问题,然后解决它。
首先可能遇到的问题是用户不合理的请求,比如上面例子中,用户询问第-10或者2.5位置的元素,那么显然程序不可能给出答案,所以,我们就需要提示用户请求不正确,并要求其输入正整数位置的元素。
其次用户如果询问第10000位置的元素的大小的时候,我们的程序也会挂掉,因为这个数字太大,我们所采用的基本的数据类型都无法表示出来,那么就需要为我们的程序“设限”,就是要先向用户声明,我们的程序可以做什么,可以做到什么程度,这样算是一个负责任的声明吧。在用户超出程序的功能范围的时候提示用户即可。
上面说过要在程序的最后写return语句,其实这样的说法不太准确。更加严谨恰当的说法是:在每个函数的每个可能的退出点写return语句。函数的退出点就是执行完某一条语句后,该函数将执行完毕的位置。
(如果返回数据类型是void,可以省略不写return语句,但是个人建议写空return,这样使函数更加完整,可以很清楚知道函数的退出点,有始有终吧)
二、调用函数(Invoking a Function)
本节需要了解传值(by value)和传址(byreference)的参数传递方式。
关于这个很多人应该都了解,如果不了解,我们通过一个程序来看一下:
#include <iostream>
void swap (int a, int b);
int main()
{
int a = 1;
int b = 2;
swap(a ,b);
printf("After swap:%d,%d\n", a ,b);
return 0;
}
void swap(int a, int b)
{
int temp = a;
a = b ;
b = temp;
printf("In function of swapa & b: %d,%d\n", a ,b);
return;
}
程序的运行结果如下:
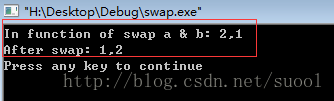
显然,在main函数中的a,b在执行完swap函数之后并没交换,但是在swap内部确实交换的。
我们理所当然的认为,我们把a,b传递给swap函数,他执行结束交换语句后,a和b的值也会改变,但是程序的运行结果却并非如此,因此我们需要问自己这样的问题:我们传递的真的a和b么?
这就涉及到程序的运行时结构。
当我们在调用一个函数时候,会在内存中建一个特殊的区域,成为“程序堆栈”。这块空间提供了每个参数的存储空间。堆栈是两种不同的内存结构,堆和栈。他们有着不同的使命和特点。
详情参:http://www.cppblog.com/oosky/archive/2006/01/21/2958.html,堆栈的区别。
堆栈区域也提供了函数定义的每个对象的内存空间——我们将这些对象称之为“局部对象”,一旦函数完成,这些内存区域便会被释放掉,即是这些区域中的数据也不会存在。
因此,我们所谓的将a,b传入swap,并非真的将我们在main函数中定义的a,b传入,而只是传入其值的大小,在swap函数内部建立了对应的数据拷贝而已,简单地说就是我们把a,b的大小告诉了swap函数,然后swap函数在其内部申请了两个相同类型的空间A,B,来存着这样两个大小的数据,然后在swap执行的数据操作都是操作的A,B对应的空间的数据,所以,这swap中,数据被交换了,但是在main中并没有被交换。
这就是传值的实质。
那么如何避免传值,真正的改变我们的a和b呢?
要改变a和b,我们要知道如何去定位和a和b,就是如何在swap中找到我们在mian函数中定义的a和b,只有找到才能交换他们。
如何找到呢?显然如果你要找一个人,我们知道他的地址的话,就一定可以找到他(非钻牛角也没办法;))。程序也一样,要找到a,b我们只需要知道a,b的地址就可以了,因此我们可以将他们的地址传递给swap函数,这就可真正的交换啦。如下:
#include <iostream>
void swap_value (int a, int b);
void swap_refer(int *a, int *b);
int main()
{
int a = 1;
int b = 2;
int *pa = &a;
int *pb = &b;
swap_value(a ,b);
printf("After by valueswap: %d,%d\n", a ,b);
swap_refer(pa, pb);
printf("After by referenceswap: %d,%d\n", a ,b);
return 0;
}
void swap_value(int a, int b)
{
int temp = a;
a = b ;
b = temp;
printf("In function ofswap_value a & b: %d,%d\n", a ,b);
return;
}
void swap_refer(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
printf("In function ofswap_refer a & b: %d,%d\n", *a ,*b);
}
运行结果如下:
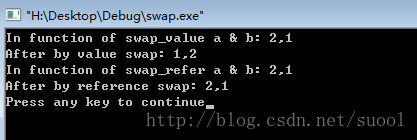
显然此时的a,b被真正的交换了。
上面的例子我们参数是指针类型数据,传递的是指针,即是数据的地址。
在C++中我们也可以传递参数为引用的类型。在此不再示例。
我们要说的是Reference的语义:
他扮演外界与对象之间一个间接的手柄的角色。在类型名称和reference之间插入一个&符号,便是声明了一个reference。(具体的引用定义,用法神马的不再详细赘述)
而引用和指针数据实在是非常相似的东西,引用可以说是数据的另一个名字,引用里面没有存储数据,只是一个对源对象的指向,使用对象的引用和使用该对象有一样的效果。
而指针参数和reference参数更重要的差异是,pointer可能是指向某个实际的对象,当我们在提领pointer的时候,必须要确定该pointer的值非0,即是确实指向了某个对象,否则可能会引起指针异常。但是reference则不必。
因此在函数内操作数据的时候,如果仅仅需要在函数内部改变参数的值,那么使用传值就够咯。
在此还需要注意的一个问题就是作用域的问题。其实更准确的说法是对象的生存期和作用和范围。
这个一般的原则应该都知道,就是全局对象和局部对象的生存期和作用范围(如其名)。
内置类型的对象,如果定义在file scope内,必定会初始化为0,如果定义在local scope之内,则除非显示指定初值,否则不会被初始化。
除了file scope和local scope,还有第三种生存期的形式dynamicextent,即动态范围。其内存是上面所说的堆,heap memory(堆内存)。这种内存必须有程序员来操作。
之所以被称之为dynamic,只因为在程序中可以动态的增加,new出新的内存,直至我们显示的delete才会释放。
如果我们一直new,而没有delete,就会导致内存泄露和溢出。。这是程序崩溃的主要原因之一。
三、提供默认的参数值(Providing Default Parameter Values)
在使用“参数传递”作为程序间的沟通方式的同时,我们很容易就会面临参数默认值的问题,因为存在着不需要输入全部参数值的情况。
默认参数值的声明方法是:
void swap_refer(int &f, int *a, int *b = 3)
此时的第三个参数默认是3。如果要把默认值置为0,则必须要是pointer类型,因为reference不同于pointer不能被设置为0。因此reference必须代表某个对象。
关于默认值的提供,有两个很不直观的规则。第一个规则,默认值的解析操作有最右边开始,如果我们提供了默认值,那么这一参数右侧的所有参数都必须默认值。第二个规则是默认值只能指定一次,可以在函数的声明处,可以在函数定义处,但是不能再两个地方同时指定。(推荐声明的时候)。
四、使用局部静态对象和声明inline函数
在一些需要重复计算的函数中,由于在函数的内部定义的变量集合都是局部变量,每次调用结束都会被释放,因此每次调用也都会重复计算。但是如果为了节省函数间通信的问题而降对象定义与file scope内,则是一种冒险。因为通常file scop的对象会打乱函数间的独立性,使程序变得难以理解。
一个比较合理的解决方法便是使用局部静态对象。
和局部非静态对象不同的是,局部静态对象所处的内存空间,即使在不同的调用过程中,依然持续存在,即是计算过的过程,不会在调用结束被释放结束。
关于inline函数,只需要在函数前面加inline关键字即可。
将函数声明为inline仅仅是对编译器提出一种要求。编译器是否执行这项请求,需视编译器而定。
一般而言,适合声明为inline函数的函数是:体积小,常被调用,所从事的计算并不复杂。
inline函数的定义常在头文件中,由于编译器必须在他被调用的时候加以展开,所以这个时候其定义必须是有效的。
五、重载函数(Override Function)
重载函数在其他的高级语言中经常见到,这个概念对大多数人来说都不默陌生,所谓的重载的函数就,其实就是一个名字的函数,但是有多个实现的方式。
既然函数名字一样,编译器如何知道调用的是那一个函数呢?不要忘记了之前所说的函数声明,声明包括返回类型,函数名,参数列表,借此得以让编译器检查函数调用的正确与否。因此,显然编译器通过识别参数的类型,个数类判断。
需要注意的是,编译器无法根据返回类型来判断和区分两个有相同名称和参数的函数。为什么呢?因为我们调用的时候没有使用返回类型呀,我们只是使用这个名字和参数来调用的哦。
六、定义和使用模板函数(Define and Using Template Functions)
所谓的模板函数,其实只是一个更高级的抽象罢了,这个机制在Lisp这种先祖语言中早就有了。
为什么要模板函数呢?
正如上面所说的,为了更高级的抽象,比如我们有一系列的重载函数,仅仅是参数的数据类型不一样,但是函数内部操作都有一定的模式,即是在更高级的抽象层次上,忽略数据类型的话,他们可以视作一个函数,因此,为了简化抽象,减少重复编码,便产生了所谓的“template function”。
Template function以关键字template开始,其后紧跟尖括号<>包围起来的一个或多个标示符,这些标示符可以表示我们希望推迟确定的数据类型。每次用户使用这一个模板的时候,必须提供对应的类型信息。这些标示符就是起着占位符的作用。当然,模板函数也可以被再次重载。
具体的模板函数不在此详解,毕竟这是一个很重要也很复杂的内容。
七、函数指针
所谓的函数指针,其形式相当复杂,他所指明的是函数的返回类型及函数类表。
即是有一系列的相同类型的函数,只是名字不一样,这看起来就像是一系列的整型变量一样,我们可以把整型变量放在一个数组中,当然也可以把这一系列的函数放在一个数组中,每个元素就是该函数的地址,函数名字就是函数的首地址,因此便产生了函数指针。
八、设定头文件
函数有一个一次定义多次声明的规则,即是在整个程序项目中,同一个函数的定义只能出现一次,可以多次声明,但是有时为了避免多次声明,可以将这样的函数声明放在头文件中。然后在每个使用该函数的程序代码中包含该头文件即可。
同时有一个例外,就是inline函数,为了能够扩展inline函数的内容,在每个调用点上,编译器都必须取得其定义,因此将其定义在头文件中是最恰当的。
同时我们需要注意函数的声明和定义的区别。
//下面的会被认为是定义而非声明
Const int seq = 4;
Const vector<int > *(*seq_arry[seq]) (int)
只要在上述定义前面加速extern即可变成声明。
但是为什么步子啊上面的int seq前面加上extern呢?
这是因为const object和inline函数一样,也是一例外,constobject 的定义只要一出文件之外就不可见。
关于引用头文件的双引号和尖括号之间的区别:
如果头文件和包含此文件的代码在同一个磁盘目录,使用引号,否则使用尖括号。
更专业的回答是:
如果此文件被认为是标准或者专属的头文件,便以尖括号,编译器在搜索改文件的时候会在默认的目录寻找,如果是引号,则认为是用户自定义的,编译器便会在包含此文件的目录开始找。














 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









