







一:hadoop2.X 笔记
hadoop1.0中,HDFS存在的问题-NameNode单点故障
-NameNode压力过大、内存受限
MapReduce存在的问题 ---mapReduce 计算时间 比较长
JobStacker 访问压力大,影响系统的扩容性
在1.x中 不支持spark。storm
Hadoop2.x 由Hdfs、MapReduce和YARN三个分支构成:
HDFS:NN federation(联合会、联邦) 是两个独立的NameNode、HA
YARN:资源管理系统
MapReduce:运行在YARN上的计算框架、或者其它计算框架
HA(high Available) :NameNodes 中只有一个处于Active 状态,其他的处在Standby 状态。其中ActiveNameNode 负责集群中的所有客户端操作,StandbyNameNode 仅仅充当备机,保证一旦ActiveNameNode 出现问题能够快速切换


二:hadoop2.5.2 HA搭建流程
前面基本流程和hadoop1差不多,参考配置http://blog.csdn.net/hu948162999/article/details/39059755
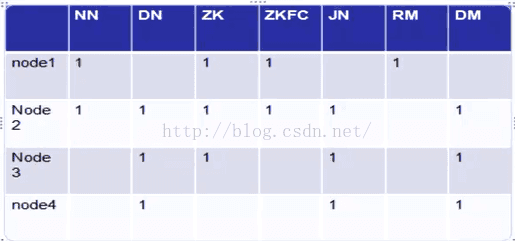
一个4台机器。指定节点如下:
一:解压之后。修改hadoop-env.sh和yarn-env.sh。指定JAVA_HOME
虽然默认配置了${JAVA_HOME}的环境变量,但是hadoop启动时,会提示找不到,没有办法,指定绝对路径,这个是必须的。
二:修改hdfs-site.xml
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--配置rpc协议的端口-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>host1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>host2:8020</value>
</property>
<!--配置http的端口-->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>host1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>host2:50070</value>
</property>
<!--配置journalNode的 url地址-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://host2:8485;host3:8485;host4:8485/mycluster</value>
</property>
<!--配置客户端使用的一个类,配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--配置隔离机制的时候 需要ssh 免密码登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!--配置journalnode 目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop/journal/data</value>
</property>
<!-- 开启失败自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>三:修改core-site.xml namenode配置
包括了 zookeeper的相关配置(host1,host2,host3作为zk节点,参考:
http://blog.csdn.net/hu948162999/article/details/45063579),分别在
host1.host2,host3机器上启动zk。
<configuration>
<!--配置hdfs的入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<!-- 设置hadoop的工作目录,默认在linux的tmp目录,linux的tmp目录,每次重启都清空,其它一些目录(hdfs)都是以这些目录为基本目录的-->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/workdir</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>host1:2181,host2:2181,host3:2181</value>
</property>
</configuration>host2
host3
host4sbin/hadoop-daemon.sh start journalnodebin/hdfs namenode -formatsbin/hadoop-daemon.sh start namenodebin/hdfs namenode -bootstrapStandby
九:创建znode在zk上,在一个namenode上面
bin/hdfs zkfc -formatZKsbin/stop-dfs.sh sbin/start-dfs.sh 
如图,先启动namenode,datanode 然后启动journalnodes,最后启动zkfc ,每个namenode对应一个zkfc 。
jps 查看所有java进程,看是否节点状态正常
十一:配置MapReduce
mapred-set.xml和yarn-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration><configuration>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>host1</value>
</property>
</configuration>配置全部OK。这个时候可以启动 sbin/start-all.sh















 1411
1411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









