







目录
数据仓库是什么
数据仓库是一个面向主题的、集成的、相对稳定的,反映历史变化的数据集合,主要用于存储历史数据,然后通过分析整理进而提供数据支持和辅助决策。
数据仓库和数据库的区别
数据库(OLTP),数据仓库(OLAP)。
(1)数据库中主要存放的是一些在线的数据,数据仓库中主要存放的是历史数据,并且存放的数据要比数据库多;
(2)数据库主要用于业务处理(比如交易系统),数据仓库主要用于数据分析;
(3)数据库的设计就是要避免冗余,而数据仓库通常会专门引入冗余,减少后面进行分析时大量的 join 操作。
在数据仓库中,冗余指的是相同的数据在多个表中重复存储。比如预聚合数据,为了提高查询性能,数据仓库可能会事先计算并存储聚合数据。
数据仓库和数据集市
数据仓库其实指的集团数据中心:主要是将公司中所有的数据全部都聚集在一起进行相关的处理操作 (ODS层)
数据的集市(小型数据仓库):在数据仓库基础之上, 基于主题对数据进行抽取处理分析工作, 形成最终分析的结果。
一个数据仓库下, 可以有多个数据集市。
数据仓库和数据集市的区别
- 范围的区别
- 数据仓库是针对企业整体分析数据的集合。
- 数据集市是针对部门级别分析的数据集合。
- 数据粒度不同
- 数据仓库通常包括粒度较细的数据明细。
- 数据集市则会在数据仓库的基础上进行数据聚合,这些聚合后的数据就会直接用于部门业务分析。
数据湖产品
数据湖与数据仓库的区别
为什么要对数据仓库分层

补充说一下:我觉得数据仓库就是一种以空间换取时间的架构!
数仓分层,以及每一层的作用
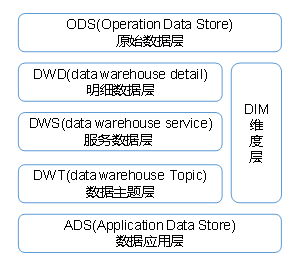
(1)ODS 原始数据层:存放原始数据,直接加载原始日志,数据,数据保持原貌不做处理。
DIM层,维度层,保存维度数据,主要是对业务事实的描述信息,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1339
1339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









