







Numpy的使用
1.numpy读取文件。
#delimiter为分隔符
world_alcohol = np.genfromtxt('world_alcohol.txt',delimiter = ',')
print(type(world_alcohol))
输出结果:<class ‘numpy.ndarray’>
2.numpy.array能够将把一个list或多个list作为输入。
#输入为一个list则转化为一维数组
vector = np.array([5,10,15,20])
#输入为多个list则转化为二维矩阵
matrix = np.array([[5,10,15],[20,25,30],[35,40,45]])
print(vector)
print(matrix)
输出结果:[ 5 10 15 20] [[ 5 10 15][20 25 30][35 40 45]]
3.shape属性。
vector = np.array([1,2,3,4])
print(vector.shape)
matrix = np.array([[5,10,15],[20,25,30]])
print(matrix.shape)
输出结果:(4,) (2, 3)
4.dtype属性
#numpy数组的值都是同一个类型,当读取numpy的数据或者转换list到numpy.array时,#numpy都会自动识别类型,使用dtype进行检查。
numbers = np.array([1,2,3,4])
print(numbers.dtype)
输出结果:int32
5.当numpy不能转换一个数值类型(例如float或者integer)时,它会使用nan值进行填充,nan表示一个丢失的值,1.98600000e+03 is actually 1.986 * 10 ^ 3。
print(world_alcohol)
输出结果:[[1.986e+03 nan nan nan 0.000e+00]]
6.numpy读取文件高阶。
#为了让读出的数据是string格式,加上参数dtype=“U75”
#skip_header:跳过数据集中的第一行
world_alcohol = np.genfromtxt("world_alcohol.txt",delimiter=",",dtype="U75", skip_header=1)
print(world_alcohol)
输出结果:[[‘1986’ ‘Western Pacific’ ‘Viet Nam’ ‘Wine’ ‘0’]]
7.numpy支持索引进行读取数据。
urguay_other_1986 = world_alcohol[1,4]
third_country = world_alcohol[2,2]
print(urguay_other_1986)
print(third_country)
输出结果:0.5 Cte d’Ivoire
8.切片操作。
vector = np.array([5,10,15,20])
print(vector[0:3])
输出结果:[ 5 10 15]
matrix = np.array([[5, 10, 15],[20, 25, 30],[35, 40, 45]])
print(matrix[:,1])
输出结果:[10 25 40]
print(matrix[:,0:2])
输出结果:[[ 5 10] [20 25] [35 40]]
print(matrix[1:3,0:2])
输出结果:[[20 25] [35 40]]
9.值的比较如果相等则返回True,否则返回False,从而返回布尔向量或者布尔矩阵。
vector = np.array([5,10,15,20])
print(vector == 10)
输出结果:[False True False False]
matrix = np.array([ [5, 10, 15], [20, 25, 30], [35, 40, 45]])
print(matrix == 25)
输出结果:[[False False False] [False True False] [False False False]]
10.通过比对产生布尔向量或者矩阵,根据布尔向量或者矩阵进行取数据。
equal_to_ten = (vector == 10)
print(equal_to_ten)
print(vector[equal_to_ten])
输出结果:[False True False False] [10]
second_column_25 = (matrix[:,1] == 25)
print(second_column_25)
print(matrix[second_column_25, :])
输出结果:[False True False] [[20 25 30]]
equal_to_ten_and_five = (vector == 10) & (vector == 5)
print(equal_to_ten_and_five)
输出结果:[False False False False]
equal_to_ten_and_five = (vector == 10) | (vector == 5)
print(equal_to_ten_and_five)
输出结果:[ True True False False]
equal_to_ten_or_five = (vector == 10) | (vector == 5)
vector[equal_to_ten_or_five] = 50
print(vector)
输出结果:[50 50 15 20]
second_column_25 = matrix[:,1] == 25
print(second_column_25)
输出结果:[False True False]
matrix[second_column_25, 1] = 10
print(matrix)
输出结果:[[ 5 10 15] [20 10 30] [35 40 45]]
11.astype方法改变值的类型。
vector = np.array(["1", "2", "3"])
print(vector.dtype)
print(vector)
vector = vector.astype(float)
print(vector.dtype)
print(vector)
输出结果:<U1 [‘1’ ‘2’ ‘3’] float64 [1. 2. 3.]
12.sum方法求和。
vector = np.array([5, 10, 15, 20])
print(vector.sum())
输出结果:50
#axis=1:行
print(matrix.sum(axis=1))
输出结果:[ 30 60 120]
#axis=0:;列
print(matrix.sum(axis=0))
输出结果:[60 60 90]
13.isnan、切片、astype、sum和mean的综合使用。
#replace nan value with 0
world_alcohol = np.genfromtxt("world_alcohol.txt", delimiter=",")
#print world_alcohol
is_value_empty = np.isnan(world_alcohol[:,4])
#print is_value_empty
world_alcohol[is_value_empty, 4] = '0'
alcohol_consumption = world_alcohol[:,4]
alcohol_consumption = alcohol_consumption.astype(float)
total_alcohol = alcohol_consumption.sum()
average_alcohol = alcohol_consumption.mean()
print(total_alcohol)
print(average_alcohol)
输出结果:[ 30 60 120] [60 60 90] 1137.78 1.140060120240481
14.arrange和reshape方法的使用。
#arrange(15):[0,15)的整数
a = np.arange(15).reshape(3, 5)
print(a)
输出结果:[[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14]]
print(np.arange( 10, 30, 5 ))
输出结果:[10 15 20 25]
print(np.arange( 0, 2, 0.3 ))
输出结果:[0. 0.3 0.6 0.9 1.2 1.5 1.8]
15.shape、ndim、dtype.name、size属性的使用。
print(a.shape)
输出结果:(3, 5)
#the number of axes (dimensions) of the array
print(a.ndim)
输出结果:2
print(a.dtype.name)
输出结果:int32
#the total number of elements of the array
print(a.size)
输出结果:15
16.zeros和ones方法的使用。
print(np.zeros ((3,4)) )
输出结果:[[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]]
print(np.ones ((3,4)) )
17.random方法的使用。
print(np.random.random((2,3)))
输出结果:[[0.98226175 0.81002624 0.95239989] [0.53141983 0.81667488 0.96626387]]
18.linespace方法的使用。
print(np.linspace( 0, 2*np.pi, 100 ))
输出描述:100个[0, 2*np.pi)从小到大。
print(np.sin(np.linspace( 0, 2*np.pi, 100 )))
输出描述:进行sin三角函数的运算。
19.运算符的使用。
#the product operator * operates elementwise in NumPy arrays
a = np.array( [20,30,40,50] )
b = np.arange( 4 )
print(a)
print(b)
#b
c = a-b
print(c)
#平方
print(b ** 2)
print(a < 35)
输出结果:[20 30 40 50] [0 1 2 3] [20 29 38 47] [0 1 4 9] [ True True False False]
#The matrix product can be performed using the dot function or method
A = np.array( [[1,1],[0,1]] )
B = np.array( [[2,0],[3,4]] )
print(A)
print(B)
print(A*B)
print(A.dot(B))
print(np.dot(A, B))
输出结果:[[1 1] [0 1]] [[2 0] [3 4]] [[2 0] [0 4]] [[5 4] [3 4]] [[5 4] [3 4]]
20.exp和sqrt方法的使用。
B = np.arange(3)
print(B)
print(np.exp(B))
print(np.sqrt(B))
输出结果:[0 1 2] [1. 2.71828183 7.3890561 ] [0. 1. 1.41421356]
21.floor向下取整方法的使用。
#Return the floor of the input 向下取整
a = np.floor(10*np.random.random((3,4)))
print(a)
输出结果:[[5. 7. 8. 6.] [1. 4. 4. 7.] [9. 6. 4. 1.]]
22.变形数组
#转成数组
print(a.ravel())
a.shape = (6, 2)
print(a)
#转置
print(a.T)
a.resize((2,6))
print(a)
#If a dimension is given as -1 in a reshaping operation, the other dimensions are automatically calculated:
print(a.reshape((3,-1)))
输出结果:[5. 7. 8. 6. 1. 4. 4. 7. 9. 6. 4. 1.] [[5. 7.] [8. 6.] [1. 4.] [4. 7.] [9. 6.] [4. 1.]] [[5. 8. 1. 4. 9. 4.] [7. 6. 4. 7. 6. 1.]] [[5. 7. 8. 6. 1. 4.] [4. 7. 9. 6. 4. 1.]] [[5. 7. 8. 6.] [1. 4. 4. 7.] [9. 6. 4. 1.]]
23.hstack行扩充和vstack列扩充的方法使用。
a = np.floor(10*np.random.random((2,2)))
b = np.floor(10*np.random.random((2,2)))
print(a)
print('---')
print(b)
print('---')
#行扩充
print(np.hstack((a,b)))
#列扩充
print(np.vstack((a,b)))
输出结果:[[7. 6.] [0. 6.]] — [[7. 1.] [5. 5.]] — [[7. 6. 7. 1.] [0. 6. 5. 5.]] [[7. 6.] [0. 6.] [7. 1.] [5. 5.]]
24.切分成组。
a = np.floor(10*np.random.random((2,12)))
print(a)
#分组之后组的个数为2
print(np.hsplit(a,2))
#在2、3各自切开
print(np.hsplit(a,(3,4))) # Split a after the third and the fourth column
a = np.floor(10*np.random.random((12,2)))
print(a)
print(np.vsplit(a,3))
输出结果:


25.用等号赋值实际上表示同一个数(同址)。
#Simple assignments make no copy of array objects or of their data.
a = np.arange(12)
b = a
# a and b are two names for the same ndarray object
print(b is a)
b.shape = 3,4
print(a.shape)
print(id(a))
print(id(b))
输出结果:True (3, 4) 2464616692672 2464616692672
26.用view赋值共享相同的值,但是一旦一个数组的值发生改变,另一个也会改变。数组不同地址但是数组的值共享相同地址。
#The view method creates a new array object that looks at the same data.
c = a.view()
print(c is a)
c.shape = 2,6
print(a.shape)
c[0,4] = 1234
print(a)
输出结果:False (3, 4) [[ 0 1 2 3] [1234 5 6 7] [ 8 9 10 11]]
27.用copy赋值(不同地址,不共享值)
#The copy method makes a complete copy of the array and its data.
d = a.copy()
print(d is a)
d[0,0] = 9999
print(d)
print(a)
输出结果:False [[9999 1 2 3] [1234 5 6 7] [ 8 9 10 11]] [[ 0 1 2 3] [1234 5 6 7] [ 8 9 10 11]]
28.argmax和max的使用。
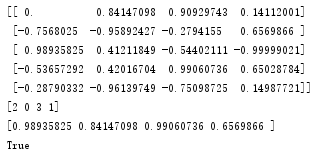
data = np.sin(np.arange(20)).reshape(5,4)
print(data)
ind = data.argmax(axis=0)
print(ind)
data_max = data[ind, range(data.shape[1])]
print(data_max)
print(all(data_max == data.max(axis=0)))
输出结果:
29.title使用。
a = np.arange(0, 40, 10)
b = np.tile(a, (3, 5))
print(b)
输出结果:

30.sort和argsort的使用。
a = np.array([[4, 3, 5], [1, 2, 1]])
print(a)
# axis=1 :行
b = np.sort(a, axis=1)
print(b)
a.sort(axis=1)
print(a)
a = np.array([4, 3, 1, 2])
j = np.argsort(a)
print(j)
print(a[j])
输出结果:[[4 3 5] [1 2 1]] [[3 4 5] [1 1 2]] [[3 4 5] [1 1 2]] [2 3 1 0] [1 2 3 4]















 3487
3487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









