







说明
本博文较长,但是有效,如若计划安装多节点的hadoop,请一步一步坚持下去,有问题请留言,我们可以讨论来解决问题。
本人将该4个节点的hadoop安装在了vmware上了,同时支持安装在物理机或者vmware ESXi上。
| 节点 | 说明 | ip地址 |
|---|---|---|
| hadoop01 | 主节点 | 192.168.10.61 |
| hadoop02 | 从节点 | 192.168.10.62 |
| hadoop03 | 从节点 | 192.168.10.63 |
| hadoop04 | 从节点 | 192.168.10.64 |
请注意以下说明:
以root身份执行的命令为红色字体
hadoop用户执行的为黑色字体
环境
| 软件 | 版本 | 下载地址 |
|---|---|---|
| 系统 | RedhatServer linux6.7 | https://access.redhat.com/downloads/ |
| Hadoop | hadoop2.7.0 | http://hadoop.apache.org/docs/current/ |
| Jdk | Jdk7.9.1 | http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html |
其中hadoop2.7.0和Jdk7.9.1两个软件我已经做好iso镜像,大家可以来百度网盘下载:点击下载
准备模板
由于搭建hadoop过程中有许多地方的配置是重复的,故我们需要做一个模板避免过度重复劳动。
安装RedhatServer
操作系统的安装大家可直接从网上寻找,在此不再啰嗦。
关闭防火墙
根据自己的需要执行如下命令
service iptables status –查看当前防火墙状态
service iptables stop –关闭防火墙
chkconfig iptables off –永久关闭防火墙
关闭SElinux
执行如下命令
vim /etc/sysconfig/selinux
将SELINUX设置为disabled
打开rsync
chkconfig rsync on
配置hosts
vim /etc/hosts
添加如下四行数据
192.168.10.61 hadoop01
192.168.10.62 hadoop02
192.168.10.63 hadoop03
192.168.10.64 hadoop04

创建hadoop用户
执行如下命令创建hadoop用户并设置其密码为hadoop123
useradd hadoop
echo “hadoop123” | passwd –stdin hadoop
解压hadoop、java文件
本文中我是将所有的软件包用软碟通打包到hadoop2.7.1dvd.iso中去,然后挂载到虚拟机的虚拟光驱中,大家也可以用FileZilla等工具将软件上传到该系统中去,在media中会显示一个20151220_122127的文件夹。
我的iso文件如下
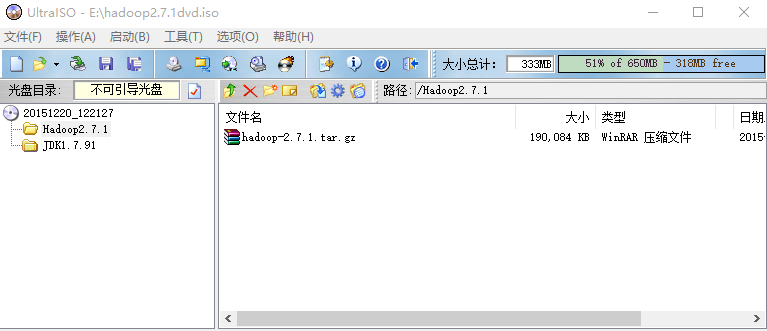
执行如下命令创建相应目录并将安装包复制到相应目录
mkdir /opt/moudles
cd /media/20151220_122127/Hadoop2.7.1/
cp hadoop-2.7.1.tar.gz /opt/moudles/
cd /media/20151220_122127/JDK1.7.91/
cp jdk-7u91-linux-x64.tar.gz /opt/moudles/
执行如下命令将所属用户修改为hadoop用户
chown hadoop /opt/moudles
chown hadoop /opt/moudles/hadoop-2.7.1.tar.gz
chown hadoop /opt/moudles/jdk-7u91-linux-x64.tar.gz
切换到hadoop用户,对压缩包进行解压
su hadoop
cd /opt/moudles/
tar zxvf hadoop-2.7.1.tar.gz
tar zxvf jdk-7u91-linux-x64.tar.gz
配置环境变量
依旧以hadoop身份执行如下命令
cat>>~hadoop/.bashrc <<<EOF
JAVA_HOME=/opt/moudles/jdk1.7.0_91
export JAVA_HOME
HADOOP_HOME=/opt/moudles/hadoop-2.7.1
export HADOOP_HOME
PATH=\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$JAVA_HOME/bin:$PATH
EOF
exit创建临时目录
以root用户身份创建临时目录,并赋予hadoop用户
mkdir -p /hadoopdata/hadoop/temp
chown -R hadoop /hadoopdata
关机,克隆4个节点
克隆4次,分别克隆出hadoop01~hadoop04,其中hadoop01为主节点,hadoop02-04为从节点。
开始安装hadoop 集群
对hadoop01~hadoop04修改
对hadoop01~hadoop04分别配置ip地址
| 节点 | 说明 | ip地址 |
|---|---|---|
| hadoop01 | 主节点 | 192.168.10.61 |
| hadoop02 | 从节点 | 192.168.10.62 |
| hadoop03 | 从节点 | 192.168.10.63 |
| hadoop04 | 从节点 | 192.168.10.64 |
执行如下命令分别对各个节点修改主机名
vim /etc/sysconfig/network
将HOSTNAME设置为对应的名称,如主节点将HOSTNAME设置为hadoop01,从节点分别设置为对应的hadoop02.hadoop03,hadoop04。
修改成功后执行reboot命令重新启动
reboot
配置ssh
请参考另一篇博文linux下多节点之间免密钥访问
修改配置文件
对主节点hadoop01进行修改
对环境文件进行修改
涉及到的文件主要有:
- /opt/moudles/hadoop-2.7.1/etc/hadoop/hadoop-env.sh
- /opt/moudles/hadoop-2.7.1/etc/hadoop/yarn-env.sh
- /opt/moudles/hadoop-2.7.1/etc/hadoop/mapred-env.sh
- /opt/moudles/hadoop-2.7.1/etc/hadoop/slaves
以hadoop用户执行如下命令对hadoop-env.sh文件进行修改
cd /opt/moudles/hadoop-2.7.1
vim etc/hadoop/hadoop-env.sh修改:
export JAVA_HOME=/opt/moudles/jdk1.7.0_91
继续执行如下命令对yarn-env.sh文件进行修改
vim etc/hadoop/yarn-env.sh修改:
export JAVA_HOME=/opt/moudles/jdk1.7.0_91
继续执行如下命令对mapred-env.sh文件修改
vim etc/hadoop/mapred-env.sh修改:
export JAVA_HOME=/opt/moudles/jdk1.7.0_91
继续执行如下命令对slaves文件进行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
cat>slaves<<EOF
hadoop02
hadoop03
hadoop04
EOF对配置文件进行修改
主要涉及的文件有:
- /opt/moudles/hadoop-2.7.1/etc/hadoop/core-site.xml
- /opt/moudles/hadoop-2.7.1/etc/hadoop/hdfs-site.xml
- /opt/moudles/hadoop-2.7.1/ etc/hadoop/mapred-site.xml
- /opt/moudles/hadoop-2.7.1/ etc/hadoop/yarn-site.xml
执行如下命令,对core-site.xml进行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
vim core-site.xml修改为如下
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoopdata/hadoop/temp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
<description>The name of the default file system.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>io file buffer size</description>
</property>
</configuration>
执行如下命令,对hdfs-site.xml进行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
vim hdfs-site.xml修改为如下
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoopdata/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value> file:/hadoopdata/hadoop/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>执行如下命令,对mapred-site.xml进行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml修改为如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value> hadoop01:19888</value>
</property>
</configuration>执行如下命令,对yarn-site.xml进行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
vim yarn-site.xml修改为如下
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
</configuration>把配置文件复制到其他Hadoop集群节点
执行如下命令将配置文件打包,然后传到slave节点上
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
rm -rf hadoopconf
mkdir hadoopconf
cp hadoop-env.sh hadoopconf
cp core-site.xml hadoopconf
cp mapred-site.xml hadoopconf
cp slaves hadoopconf
cp hdfs-site.xml hadoopconf
cp yarn-site.xml hadoopconf
cp yarn-env.sh hadoopconf
cd hadoopconf
tar cvf hadoopconf.tar *
scp hadoopconf.tar hadoop@hadoop02:/opt/moudles/hadoop-2.7.1/etc/hadoop
scp hadoopconf.tar hadoop@hadoop03:/opt/moudles/hadoop-2.7.1/etc/hadoop
scp hadoopconf.tar hadoop@hadoop04:/opt/moudles/hadoop-2.7.1/etc/hadoop
分别在hadoop02,hadoop03,hadoop04上执行如下命令对其解包,完成Hadoop集群配置文件的同步
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
tar xvf hadoopconf.tar第一次启动hadoop
格式化namenode
在主节点上执行
cd /opt/moudles/hadoop-2.7.1/
./bin/hdfs namenode -format启动hdfs
在主节点上执行
cd /opt/moudles/hadoop-2.7.1/
./sbin/start-dfs.sh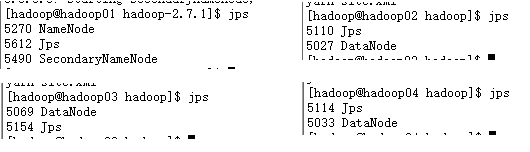
启动yarn
在主节点上执行
cd /opt/moudles/hadoop-2.7.1/
./sbin/start-yarn.sh
```shell

<div class="se-preview-section-delimiter"></div>
## 验证安装成功
<div class="se-preview-section-delimiter"></div>
###浏览器查看
通过浏览器访问http://hadoop01:50070

通过浏览器访问http://hadoop01:8088

<div class="se-preview-section-delimiter"></div>
###程序验证
执行如下代码运行带有12个map和100个样本的pi实例
<div class="se-preview-section-delimiter"></div>
```shell
cd /opt/moudles/hadoop-2.7.1/share/hadoop/mapreduce
yarn jar ./hadoop-mapreduce-examples-2.7.1.jar pi 12 100执行结果如下所示:
Number of Maps = 12
Samples per Map = 100
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Wrote input for Map #10
Wrote input for Map #11
Starting Job
16/06/11 17:07:12 INFO client.RMProxy: Connecting to ResourceManager at hadoop01/192.168.10.61:8032
16/06/11 17:07:12 INFO input.FileInputFormat: Total input paths to process : 12
16/06/11 17:07:12 INFO mapreduce.JobSubmitter: number of splits:12
16/06/11 17:07:12 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1465618407612_0006
16/06/11 17:07:13 INFO impl.YarnClientImpl: Submitted application application_1465618407612_0006
16/06/11 17:07:13 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1465618407612_0006/
16/06/11 17:07:13 INFO mapreduce.Job: Running job: job_1465618407612_0006
16/06/11 17:07:17 INFO mapreduce.Job: Job job_1465618407612_0006 running in uber mode : false
16/06/11 17:07:17 INFO mapreduce.Job: map 0% reduce 0%
16/06/11 17:07:29 INFO mapreduce.Job: map 8% reduce 0%
16/06/11 17:07:30 INFO mapreduce.Job: map 67% reduce 0%
16/06/11 17:07:36 INFO mapreduce.Job: map 75% reduce 0%
16/06/11 17:07:37 INFO mapreduce.Job: map 100% reduce 100%
16/06/11 17:07:37 INFO mapreduce.Job: Job job_1465618407612_0006 completed successfully
16/06/11 17:07:37 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=270
FILE: Number of bytes written=1505992
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3170
HDFS: Number of bytes written=215
HDFS: Number of read operations=51
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=12
Launched reduce tasks=1
Data-local map tasks=12
Total time spent by all maps in occupied slots (ms)=157380
Total time spent by all reduces in occupied slots (ms)=5029
Total time spent by all map tasks (ms)=157380
Total time spent by all reduce tasks (ms)=5029
Total vcore-seconds taken by all map tasks=157380
Total vcore-seconds taken by all reduce tasks=5029
Total megabyte-seconds taken by all map tasks=161157120
Total megabyte-seconds taken by all reduce tasks=5149696
Map-Reduce Framework
Map input records=12
Map output records=24
Map output bytes=216
Map output materialized bytes=336
Input split bytes=1754
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=336
Reduce input records=24
Reduce output records=0
Spilled Records=48
Shuffled Maps =12
Failed Shuffles=0
Merged Map outputs=12
GC time elapsed (ms)=3029
CPU time spent (ms)=35170
Physical memory (bytes) snapshot=3409559552
Virtual memory (bytes) snapshot=11427811328
Total committed heap usage (bytes)=2604138496
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1416
File Output Format Counters
Bytes Written=97
Job Finished in 25.365 seconds
Estimated value of Pi is 3.14666666666666666667
关闭hadoop
停止yarn
在主节点上执行如下命令
cd /opt/moudles/hadoop-2.7.1/
./sbin/stop-yarn.sh停止hdfs
在主节点执行如下命令
cd /opt/moudles/hadoop-2.7.1/
./sbin/stop-dfs.sh














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









