






k-近邻算法
k-近邻算法,又称为KNN,在机器学习领域k-近邻算法是比较常用的经典算法之一,KNN算法是一个分类算法,它归于实例学习和懒惰学习,它的原理很简单:
为了判断未知实例样本的类别,以所有已知实例类别作为参考,我们可以选择参数K计算未知实例与所有已知实例距离(一般使用欧式距离),选择最近K个已知实例,通常k是不大于20的整数,在这K个实例中可能多种类别,我们遵循少数服从多数的原则,让未知实例归类为K个最近临近样本中最多数的类别。

KNN算法的优缺点
KNN算法的优点:算法简单易于实现,而且通过对K的选择可具备丢噪音数据的健壮性,我们来举一个例子,下图中鼠标未知是什么类型的样本?
其实我们一看就应该认为它是红三角的,因为它距离红三角比较近,但是这有一个问题就是,假如我们设置K=1,那么此时的未知样本就被认为是蓝方块。这就是蓝色方块噪音对我们的影响。所以我们可以通过增加K,来达到去除噪音的作用,我们可以设置K=4,那么算法就会认为未知样本是红三角了,这就是增加K达到去噪的作用,这是KNN算法的优点。
未知未知样本是什么?
KNN算法的缺点:首先算法需要大量的空间存储,算法复杂性高,需要将未知实例和所有的已知实例进行比较,当一类样本数量过大占主导地位的时候,K也设为很大的时候,新的未知实例容易被数量大的样本主导,但有可能这个未知实例并不接近这个最多的样本类别,它可能更接近其它类别,但这个问题也是可以解决的,为了解决这个问题,根据样本设置权重,比如权重为1/d(d为距离),距离越近权重越大。
k-近邻算法分类的应用
我们如何判断一个电影是动作电影还是爱情电影呢?就我们个人来说只要看一次就可以判断出这个电影的类别,我们只需要判断这个电影是打斗次数多一点还是亲吻次数多,一般来说我们就可以通过这种方式来判断这个电影的类别,假设我们现在有一个关于电影的数据集,每个样本有两个特征,一个特征是打斗次数,另外一个是亲吻的次数。
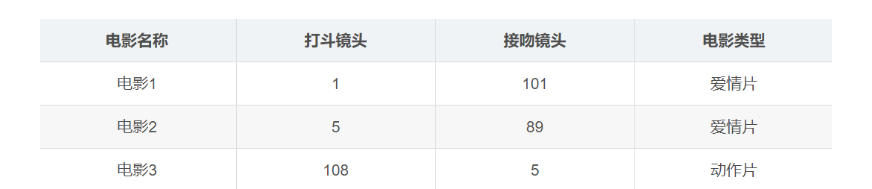
数据集
现在我们已经有了训练集样本,现在当我们有未知样本的时候,我们就可以设置阈值k,然后通过KNN算法,判断距离未知样本最近的K个样本的类别,哪个类别最多,我们就可以认为这个电影是动作电影还是爱情电影。
可视化操作

现在我们将我们的样本通过可视化的方式进行了显示,我们可以看出爱情片偏向于左上角,而动作片偏向于右下角,现在我们有一个未知的样本,它的打斗是101次,而接吻次数是20,我们对这个样本也进行可视化,我们发现这个未知样本距离最近的动作电影类别多,所以我们可以认为这个未知样本是动作片,这就是我们KNN算法分类未知电影为动作电影还是爱情电影的核心。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











