







现在爬虫这么流行,学了点正则表达式的我就想着用(.*?)去实现一切偷懒的事。前两天看上了电影天堂这个网站,于是开始想:要不一次性爬取一页的视频下载链接试试。下面是这个网站的简图,接下来的任务就是把最右边红色方框的电影链接全给爬出来,然后可以直接可以用迅雷打包再一个文件夹下载。
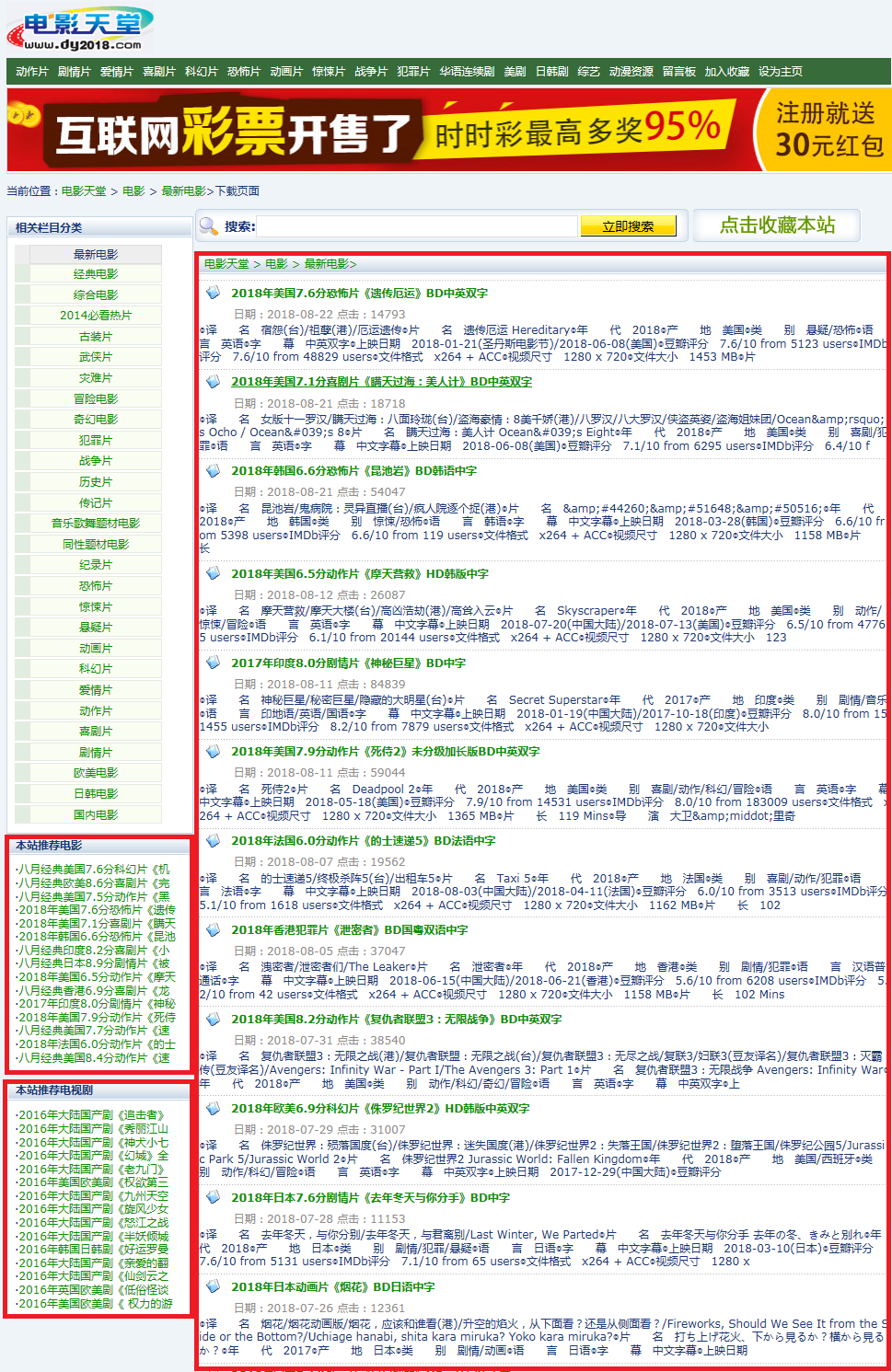
在360极速浏览器里面我们右键选择查看源代码,定位到第一部影片<<遗传厄运>>,其网页代码如下:

很明显,这一页并没有下载链接,必须点击进去这个电影的网址链接才能继续爬虫获取其ftp下载链接。于是我们点进去观察其新网页链接为:
https://www.dy2018.com/i/99901.html
而上面那个html解析代码第523行有:
反复观察几个后确认每个电影点开后的新链接为:
https://www.dy2018.com/i/ + 每个电影自己的独立id + .html
接下来很容易就解析出电影的ftp下载链接和磁力链接:

理论部分讲解完成后,接下来的Python实现代码如下:
# -*- coding:utf-8 -*-
import urllib
import urllib2
import re
import requests
import time
import requests
import requests_cache
# User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64)
# AppleWebKit/537.36 (KHTML, like Gecko)
# Chrome/65.0.3325.181 Safari/537.36 OPR/52.0.2871.64
requests_cache.install_cache('demo_cache')
global fp
url = 'https://www.dy2018.com/html/gndy/dyzz/index.html'
# url = 'https://www.dy2018.com/i/99901.html'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)'
headers = {'User-Agent': user_agent}
try:
r = requests.get(url)
print type(r)
print r.status_code
print r.encoding
html = requests.get(url, headers=headers).text
html = html.encode(r.encoding)
html = html.decode("gbk")
content = html
# print content
fp = open(unicode("temp_pachong.txt", 'utf-8'), 'w') # 文件名不乱码
fp.write(content.encode('utf-8'))
fp.close()
# <a href="/i/99901.html" class="ulink" title="2018年美国7.6分恐怖片《遗传厄运》BD中英双字">2018年美国7.6分恐怖片《遗传厄运》BD中英双字</a>
pattern = re.compile('<b>.*?<a href="/i/(.*?).html" class="ulink" title="(.*?)">.*?</a>.*?</b>', re.S)
items = re.findall(pattern, content)
fp = open(unicode("电影天堂爬虫.txt",'utf-8'),'w') # 文件名不乱码
localtime=time.strftime('%Y-%m-%d-%H:%M:%S', time.localtime(time.time()))
count=0
fp.write("********************" + localtime +"********************".encode('utf-8') + '\n')
print '本页总资源数为:' + str(len(items))
for item in items:
count=count+1
temp=str(count) + ": " + item[1]
print temp
fp.write(temp.encode('utf-8')+ '\n')
temp='https://www.dy2018.com/i/' + item[0] + '.html'
print temp
#获取下载链接
url = temp
r = requests.get(url)
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)'
headers = {'User-Agent': user_agent}
html = requests.get(url, headers=headers).text
html = html.encode(r.encoding)
html = html.decode("gbk")
content = html
# print content
link_temp = re.compile('<td style=".*?"><a href="(.*?)">.*?</a></td>', re.S)
link = re.findall(link_temp, content)
print link[0]
fp.write(link[0].encode('utf-8') + '\n')
fp.write("********************" + localtime +"********************".encode('utf-8'))
fp.close()
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason
fp.close()
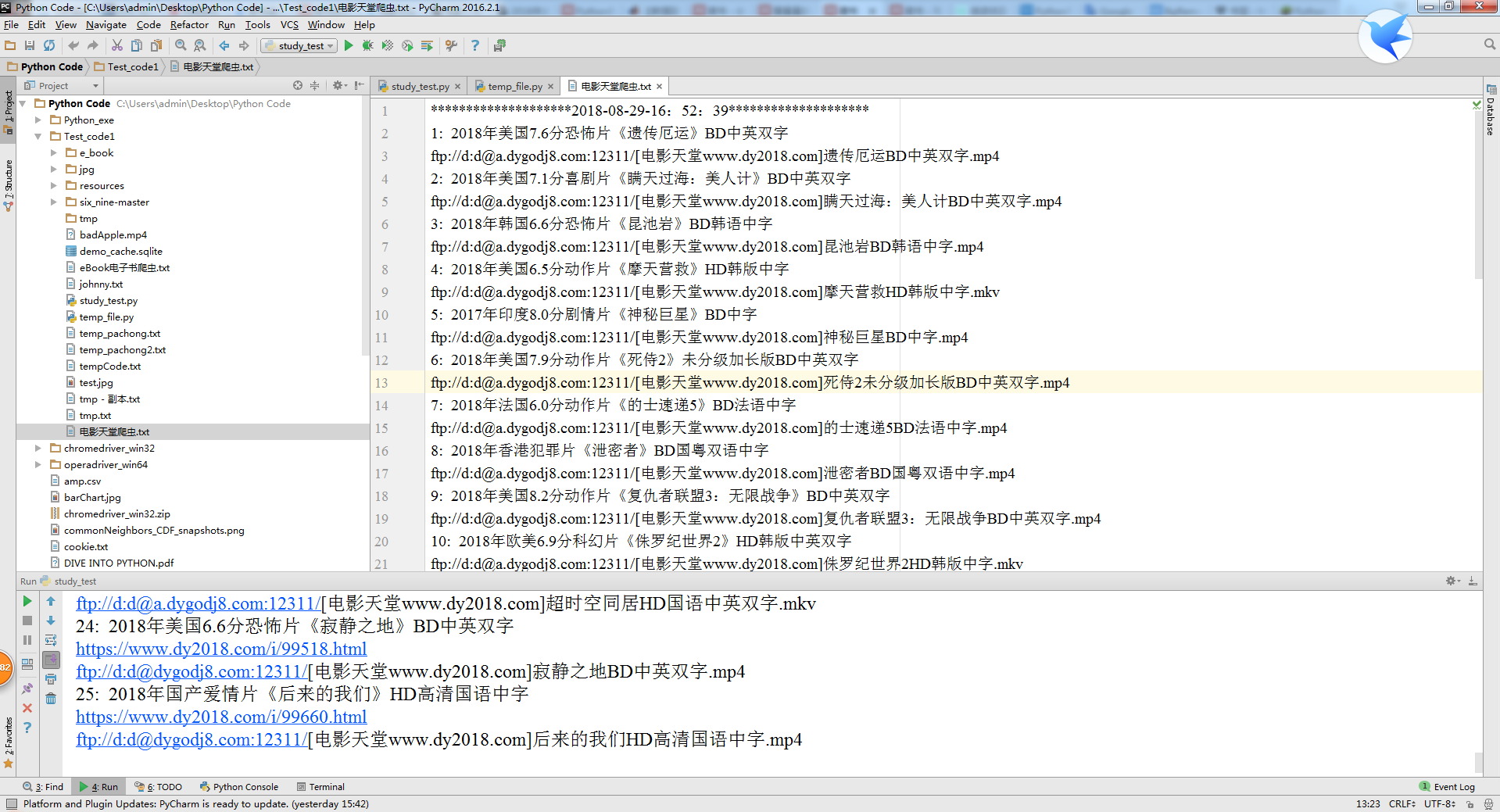
实际效果如下:

















 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









