






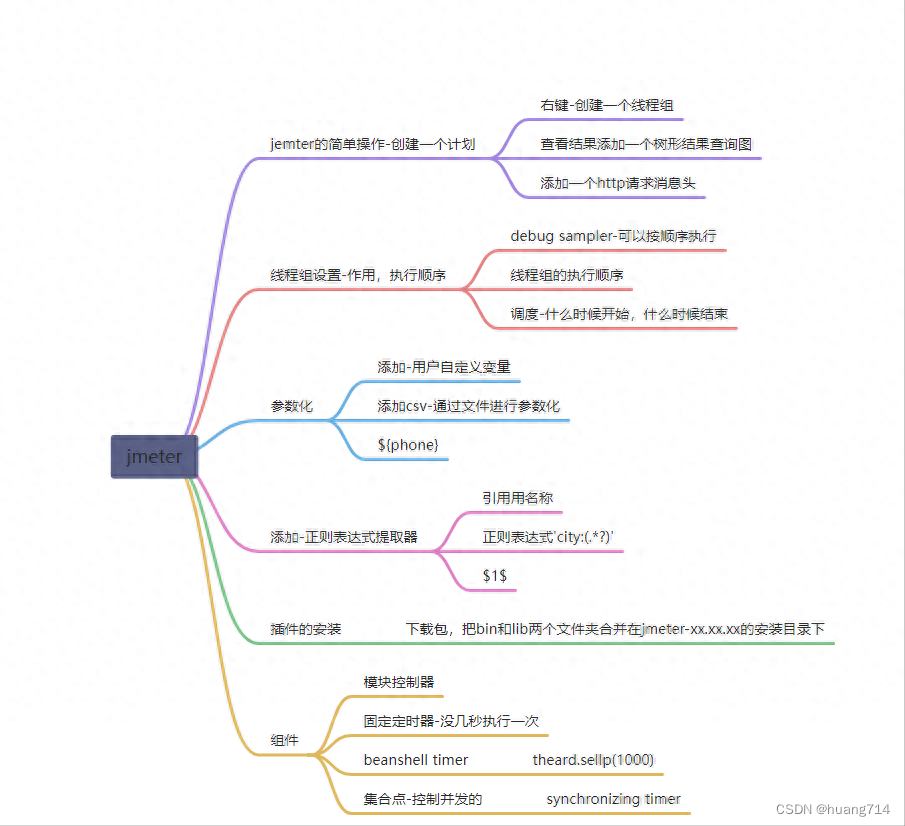
1、 jmeter的介绍
jmeter也是一款接口测试工具,由java语言开发的,主要进行性能测试。
2、jmeter安装
jmeter官网下载链接:
https://jmeter.apache.org/download_jmeter.cgi ,查看是否安装成功【jmeter -v】
下载 java jdk1.8,进行安装,测试命令:java -version,
https://repo.huaweicloud.com/java/jdk/
把jmeter下的bin目录添加到环境变量,然后即可使用
3、界面功能介绍
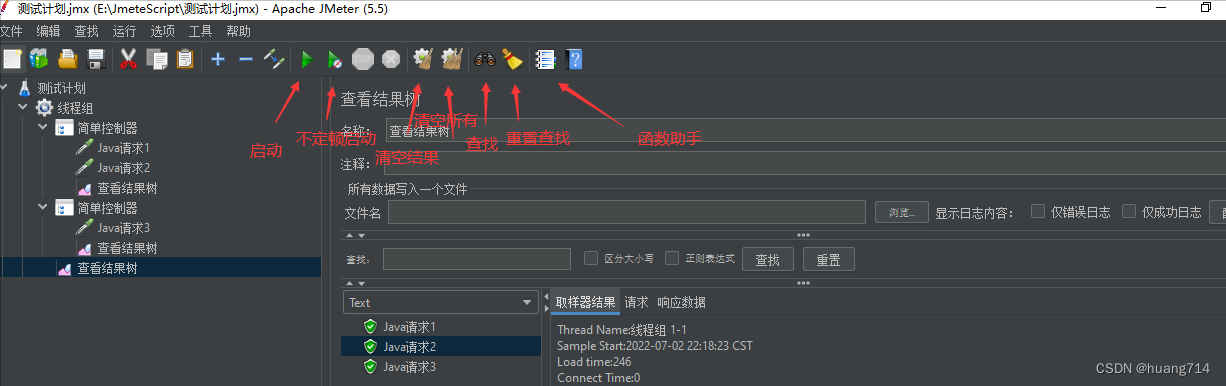
4、jmeter的十大元件
1、测试计划 , jmeter的起点和容器
2、线程组,代表一定的虚拟用户
3、取样器 , 一般会使用http请求 发送请求的最小单元
4、 逻辑控制器, if逻辑控制器,用于条件判断
5、 前置处理器, 发送请求前要做的事情 请求之前的操作
6、 后置处理器, 得到响应数据后要做的事情,比如: json提取器,xpath提取器。 请求之后的操作
7、 断言, 判断预期结果和实际结果是否一致
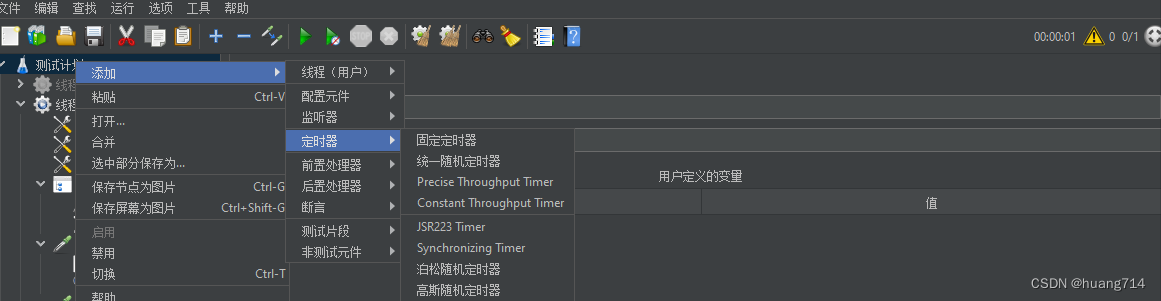
8、 定时器,一般会同步定时器 主要用于做接口性能测试 是否延迟或者定时发送
9、配置元件,一般会使用csv数据参数,用户定义的变量,请求和配置参数
10、监听器,一般会使用察看结果树,聚合报告
测试计划>>>线程组>>>配置元件>>>前置处理器>>>定时器>>>取样器>>>后置处理器>>>断言>>>监听器
5、作用域
组件会作用域他的父及组件,同及组件,以及子组件
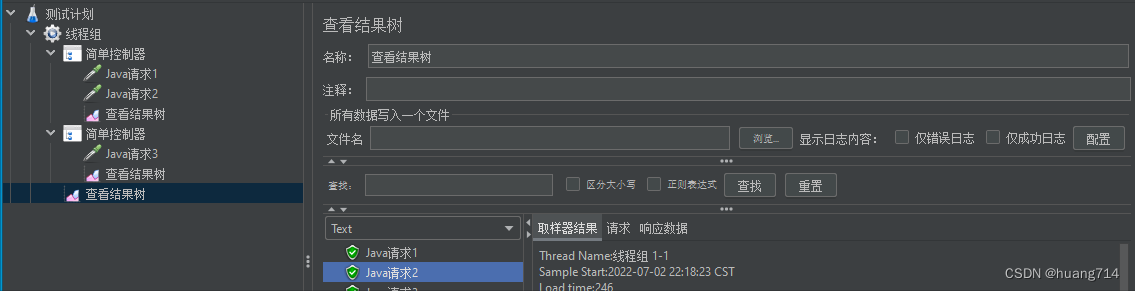
只作用于简单控制器1
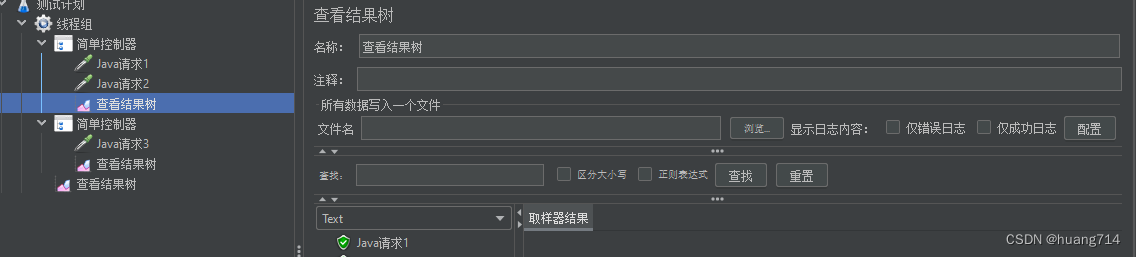
之作用与简单控制器2
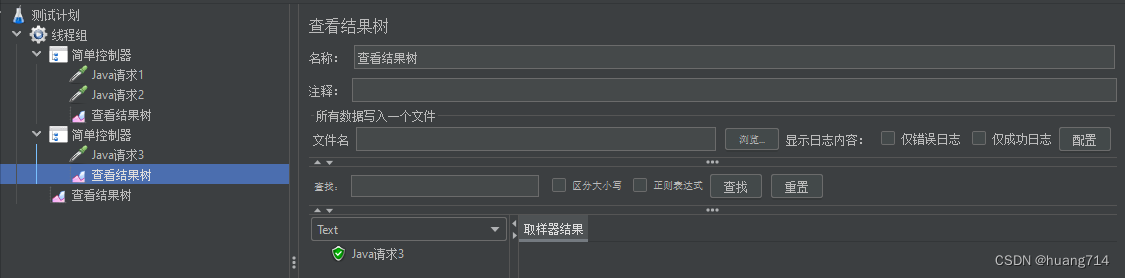
作用于简单控制器1,2
6、进程、线程、线程组
- 进程:一个正在执行的程序或者软件称为进程,进程是用于提供运行资源的,一个进程默认会有一个线程(主线程)
- 线程:进程中执行任务的一个单元。线程是属于进程的,是进程中真正干活的。
- 线程组:把线程进行分组,可以形成不同的团队或者部门。比如:开发组,测试组。
线程组的执行:默认情况下多个线程组是并行执行的,想要设置成顺序执行,需要在测试计划里面勾选独立运行每个线程组
提示:在线程组内,多个任务是顺序执行的。
7、jmeter的基本使用
1. 启动jmeter
2. 创建了测试计划
3. 选中测试计划右击选择线程组
4. 右击线程组添加http请求
5. 配置http请求的相关信息
6. 添加察看结果树(察看请求结果的)
7. 点击绿色箭头执行
一下是一个简单get请求的设计
案例一:jmete实现数据驱动
步骤一: 创建测试计划
步骤二:创建线程组
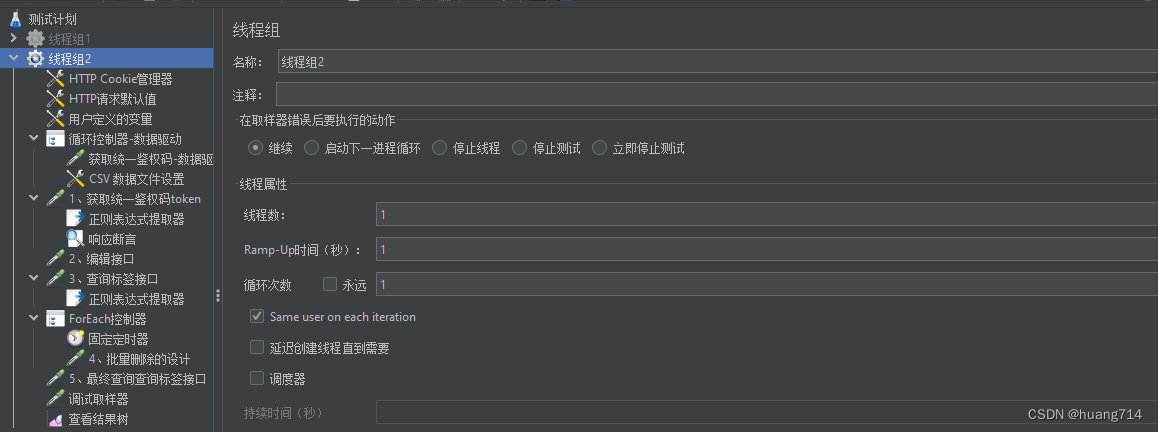
步骤三:添加 HTTP Cookie管理器
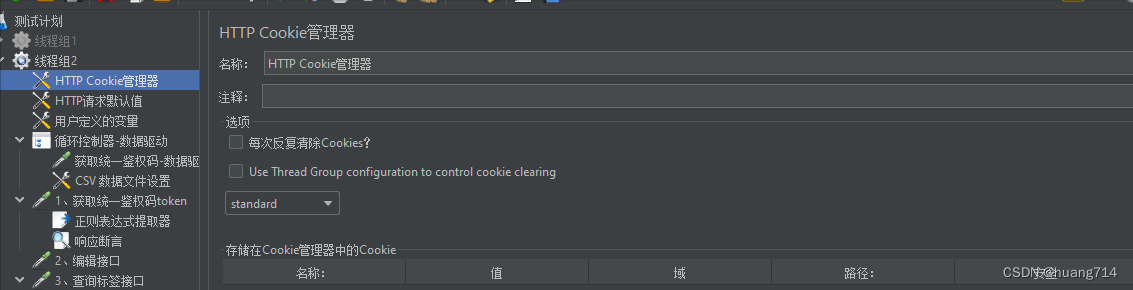
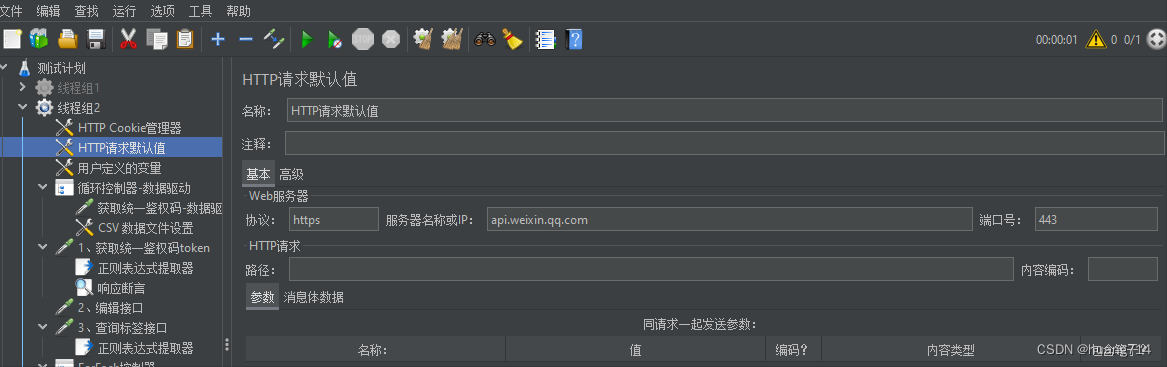
步骤四:天剑 HTTP请求默认值
步骤五:添加 用户定义的变量

步骤六: 添加循环控制器-数据驱动

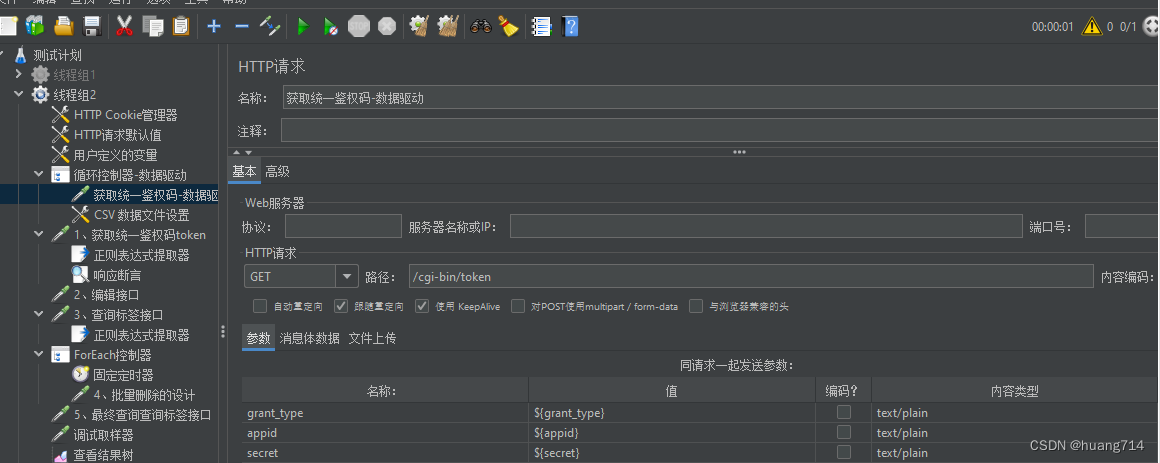
步骤七: 获取统一鉴权码-数据驱动
步骤八: CSV 数据文件设置
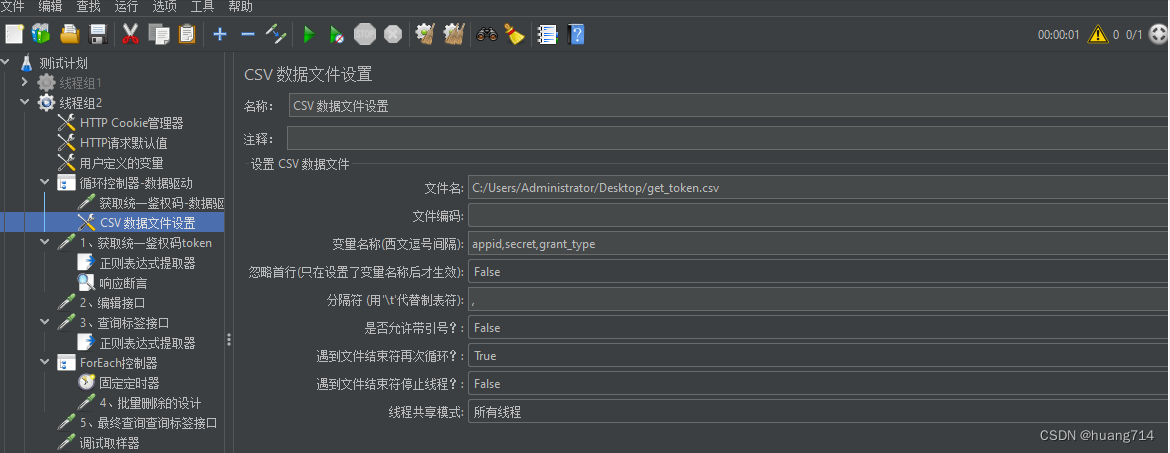
案例二:从相应结果中提取变量
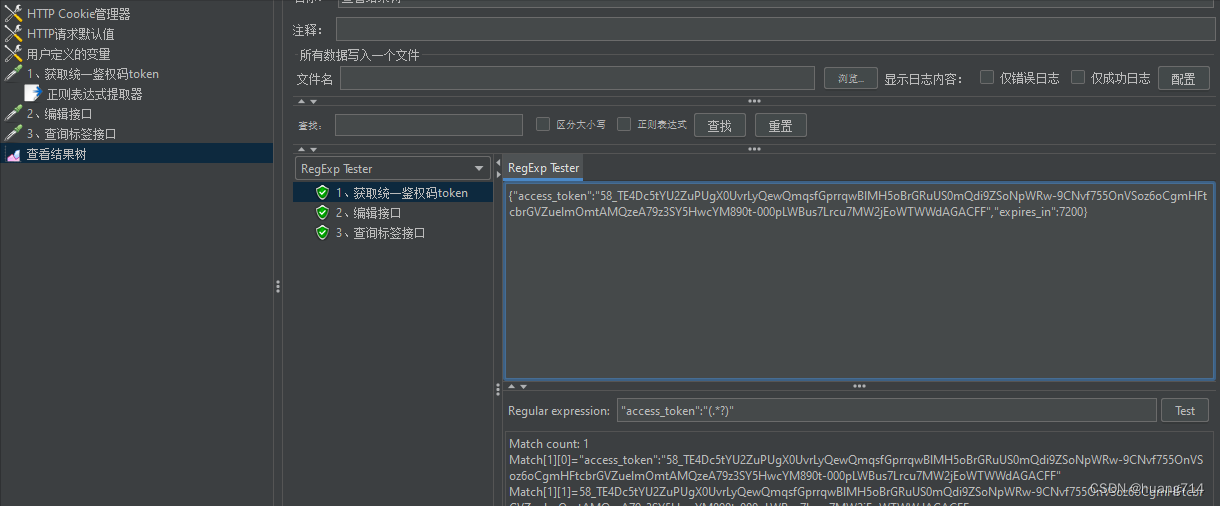
步骤一: 1、获取统一鉴权码token
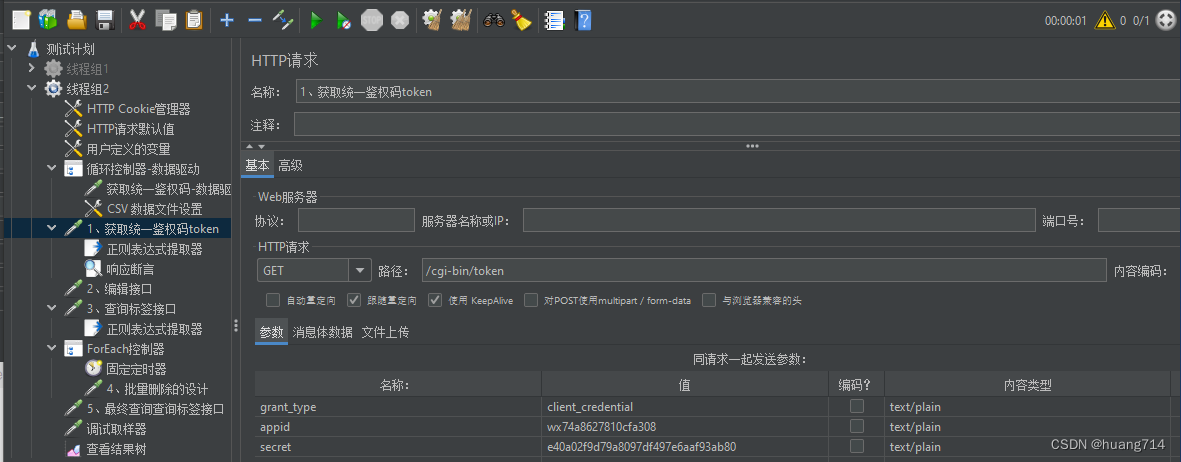
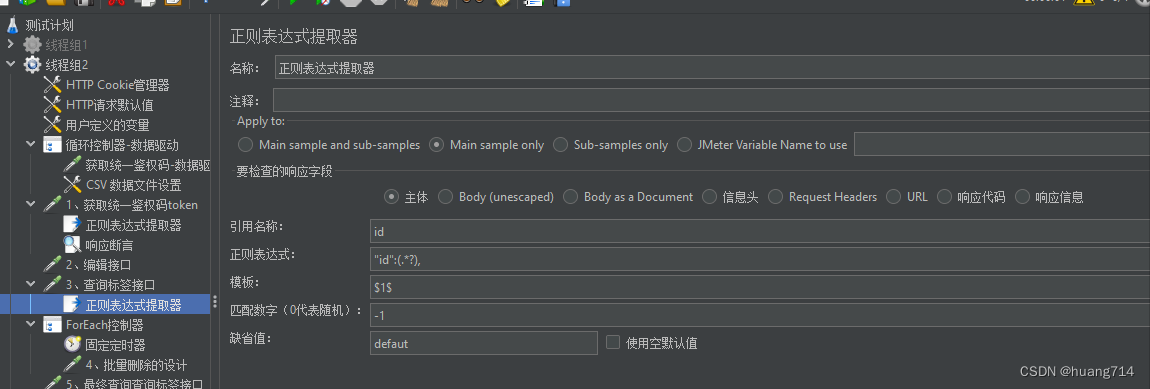
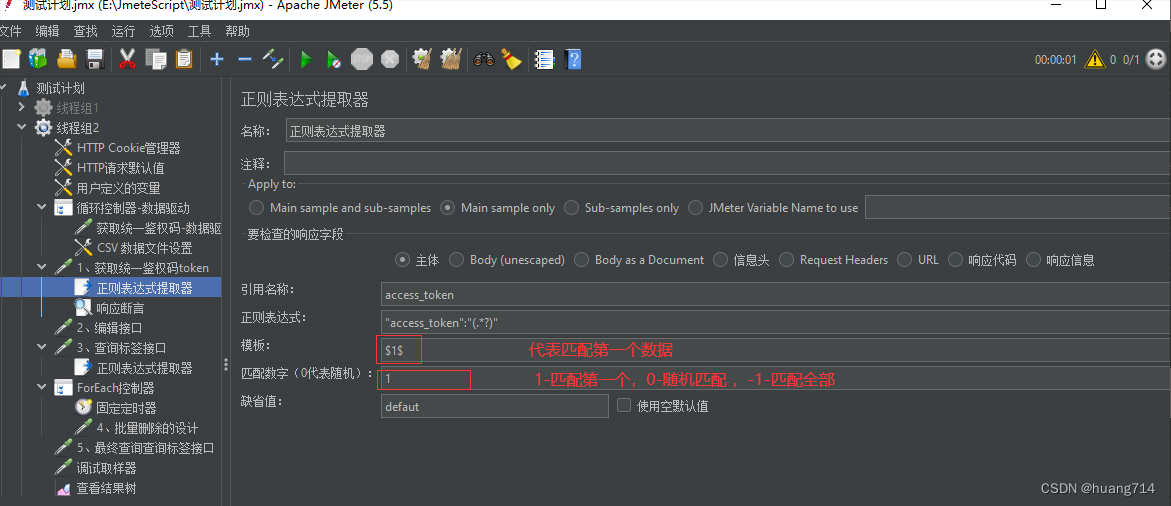
步骤二:添加 正则表达式提取器

步骤三:添加 响应断言
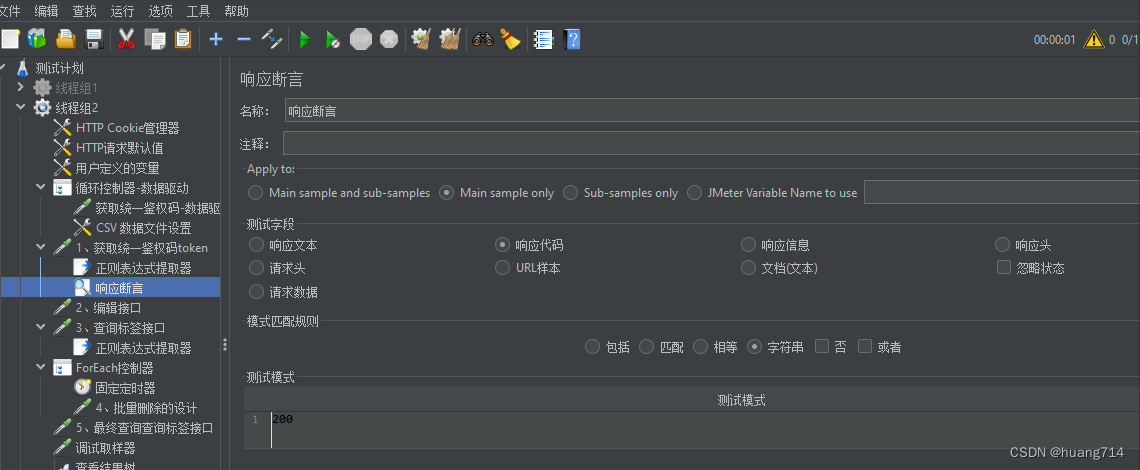
案例三:2、编辑接口(从上述结果中提取变量token实现接口关联)
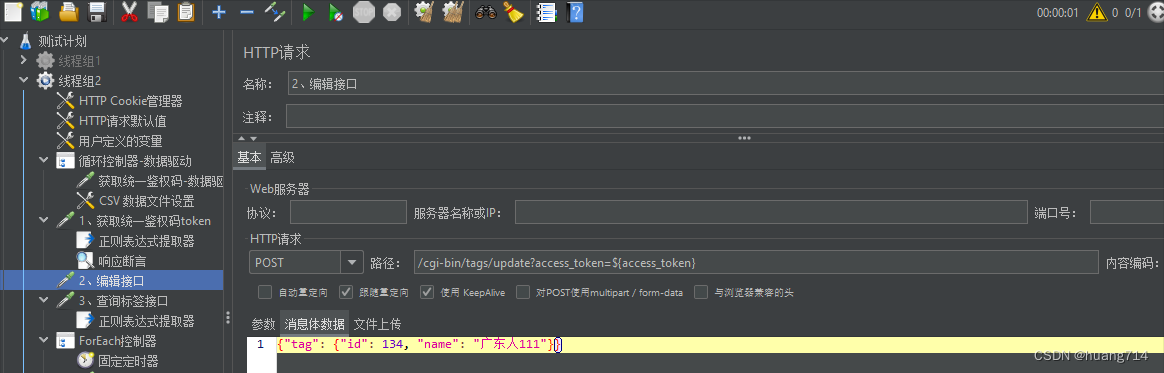
案例四:从查询接口中获取id,从而实现以上的从添加数据,修改数据,删除数据的闭环操作
步骤一:查询接口
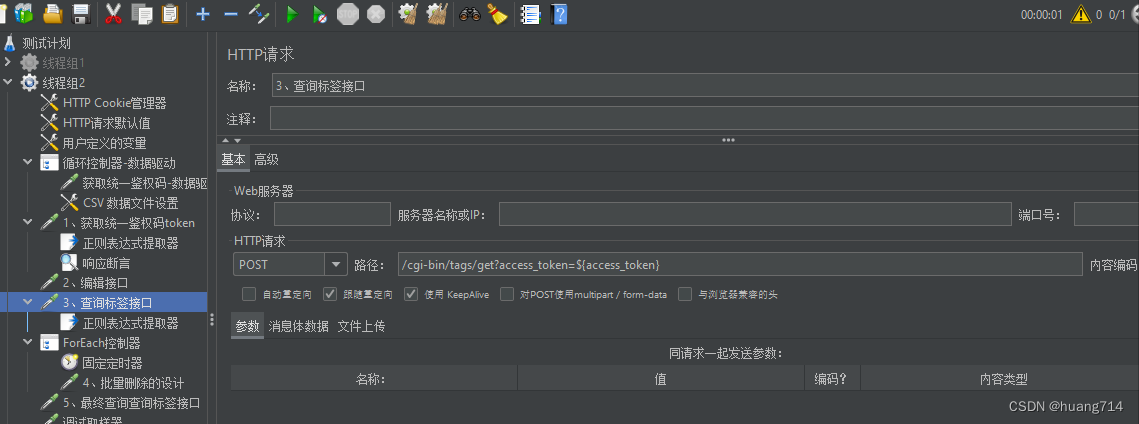
步骤二:” 正则表达式提取器
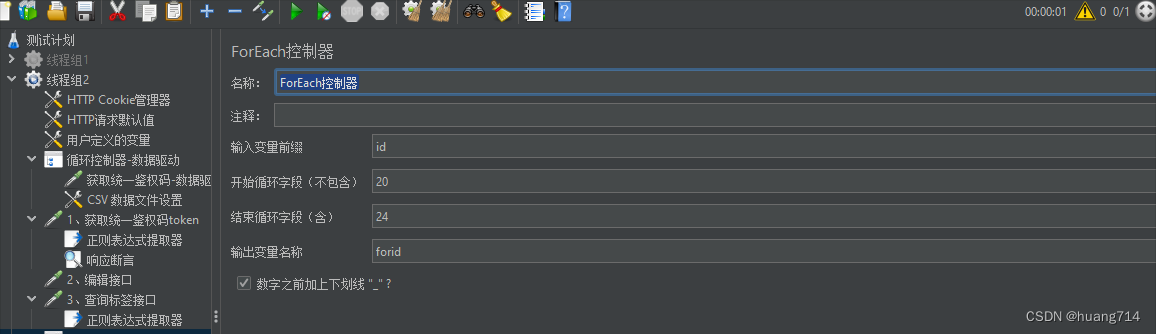
步骤三 ForEach控制器
步骤四: 固定定时器
步骤五 4、批量删除的设计
结果返回乱码:,解决乱码的一下两种方式
方式一1,直接在请求接口中修改为utf-8,如果还没解决,试着方法二
方式二,在bin文件找那个修改jmeter.properties文件
8、接口关联的方式
1、方式一:正则表达器
2、方式二:jsonpath方式提取
1、代表根节点的目录:$
2、取子节点的目录:.
结合起来复杂一点:$.tag[17].name9、setup线程组和teardown线程组
setup线程组:在所有线程组中最先执行的,一般可以用于初始化工作,比如: 准备测试数据,登录。
线程组:在setup之后和teardown线程组之前执行的。
teardown线程组:在所有线程组中最后执行的,一般用于扫尾工作,比如: 退出登录,测试数据。
10、http请求默认值
当发送http请求的时候,请求信息会有一些重复,比如:http协议、ip地址、端口号,编码格式等一般都是相同的,则可以把http请求相同的信息添加到http请求默认值里面。位置是在配置元件里面
提示:当配置完http请求默认值以后,在发送http请求的时候,重复的信息就不需要再次填写了,只添加动态变化的数据,比如:请求的路径,请求的方法
11、参数化
11.1、用户参数实现参数化
1. 创建线程组
2. 右击线程组选择前置处理器添加用户参数
3. 分别添加用户(数据共几条)和添加变量(参数有几个)
4. 添加http请求,配置相关的信息,在消息头里面获取用户参数,语法:${变量名}
5. 添加http信息管理器,配置请求头信息,
Content-Type:application/json
6. 点击线程组,把线程数改成用户数(数据的条数)
11.2、csv文件实现参数化
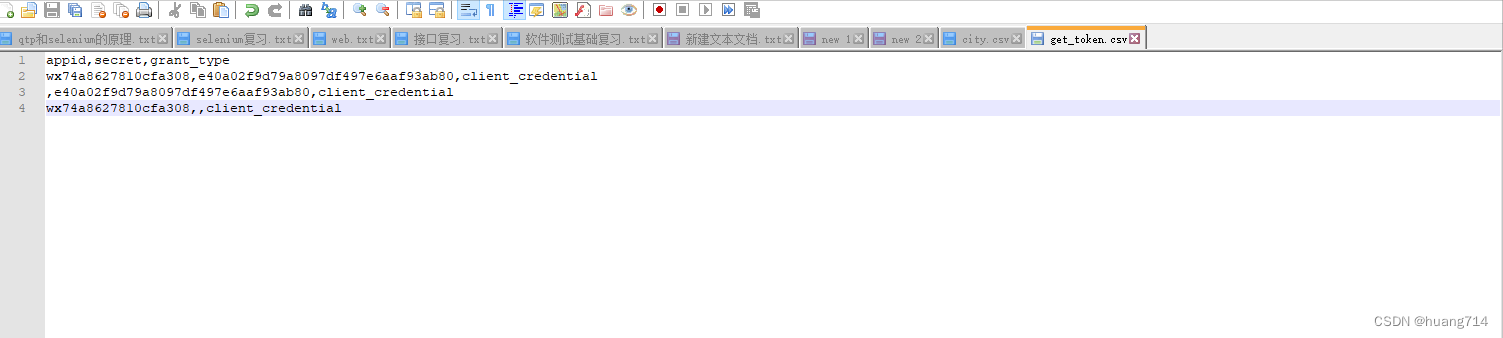
1、准备csv文件,数据如下:
T803,三国学院,罗贯中,男人的一部戏
T804,红楼梦学院,曹雪芹,女人的一部戏
内容格式
2、创建线程组
3、右击线程组选择配置元件添加csv数据文件设置(CSV Data Set Config)
4、配置CSV Data Set Config相关信息:
1、csv文件的路径
2、 文件的编码格式
3.、设置变量名,每一列对应一个变量名,变量名之间使用逗号,比1如:dep_id,dep_name,master_name,slogan
5、添加http请求,添加学院信息,在消息体里面获取变量名对应的数据,比如:
{
"data": [
{
"dep_id":"${dep_id}",
"dep_name":"${dep_name}",
"master_name":"${master_name}",
"slogan":"${slogan}"
}
]
}6、右击线程组,添加http信息头管理器,设置
Content-Type:application/json
7、点击线程组,设置循环次数,这个次数等于文件中的条数(参数数据的条数)
8、执行察看结果树。
11.3、csv文件实现参数化和用户参数实现参数化对比
两者实现思路基本一致
实现流程 用户参数 相对简单
批量设置数据时 csv 相对简单
用户参数 设置的是线程数
csv 设置的是循环次数
用户参数设置的是线程数,使用线程意味着更加消耗资源,效率从微观角度讲不如csv
提示: csv 相对更常用
12、jmeter实现操作数据库的原理
jmeter本身不具备操作数据库的能力,因为jmeter是java语言编写的,所以可以借助第三方模块(JDBC jar 包) 来实现操作数据库。
1、直连数据库
jmeter操作数据库的原因:
1. 对比查询数据库的结果和接口返回的结果是否一致,
2. 可以对数据库进行压力测试。
2、jmeter 实现操作sqlite数据库的步骤
1、点击测试计划,添加sqlite数据库的jar
2、创建线程组
3、右击线程组选择配置元件选择JDBC Connection Configuration
1. 配置连接数据库的名字(Variable Name for created pool)
2. 设置操作数据库的路径(Database URL):
路径格式为:jdbc:sqlite:sqlite数据库路径
3. JDBC Driver class 选择:org.sqlite.JDBC
4、右击线程组添加JDBC request
1. 配置连接数据库的名字
2. 如果是查询操作,Query Type设置为:Select Statement
5、执行查看结果树
3、jmeter 实现操作mysql数据库的步骤
1、点击测试计划,添加mysql数据库的jar
2、创建线程组
3、右击线程组选择配置元件选择JDBC Connection Configuration
1. 配置连接数据库的名字(Variable Name for created pool)
2. 设置操作数据库的路径: Database URL
如果操作mysql数据库,路径格式为:
jdbc:mysql://数据库对应的ip地址:数据库的端口号/操作的数据库
例:
jdbc:mysql://127.0.0.1:3306/zhujiang
如果window电脑报错:
在database url后面加上【?serverTimezone=UTC】其中UTC是统一标准世界时间即可解决。
解决中文乱码输入问题,可以在database url后面加上【?characterEncoding=UTF-8?useUnicode=true】。
3. JDBC Driver class选择:com.mysql.jdbc.Driver
4、右击线程组添加JDBC request
1. 配置连接数据库的名字
2. 如果是查询操作,Query Type设置为:Select Statement
5、执行查看结果树
4、jmeter 实现增删改的操作
1、点击测试计划,添加sqlite数据库的jar
2、创建线程组
3、右击线程组选择配置元件选择JDBC Connection Configuration
1. Variable Name for created pool(配置连接数据库的名字)
2. 设置操作数据库的路径(Database URL):
操作sqlite数据库,路径格式为:
jdbc:sqlite:sqlite数据库路径
3. JDBC Driver class选择:org.sqlite.JDBC
4、右击线程组添加JDBC request
Variable Name of Pool declared in JDBC Connection Configuratior(配置连接数据库的名字)
如果是修改操作,Query Type设置为:update Statement
update、insert、delete sql语句
5、执行查看结果树
5、数据库查询结果再处理
1、在JDBC request里面设置保存结果的变量
Variable names设置保存结果的变量名,比如: name
2、在http request 获取name变量保存的数据,比如:获取第一个数据,${name_1}
3、执行查看结果树
6、调试取样器
用来获取用户设置的变量名和变量值
调试取样器的使用步骤
创建线程组,添加jdbc request,设置对应设置变量,比如: name来保存用户查询的数据
2. 右击线程组选择取样器添加debug sampler (调试取样器)
3. 执行查看结果树
13、提取器
1、XPath提取器的使用
1、创建http请求,比如:请求京东
2、右击http请求选择后置处理器添加xpath提取器
1. 勾选use tidy 表示在html文档中提取数据,不勾选表示xml文档中提取数据,
2. 设置引用的名字,比如: jd_title
3. 设置xpath路径表达式
4. 如果想要查看提取的数据,可以添加一个调试取样器
3、创建http请求,在设置参数的时候获取之前xpath提取的内容,比如:${jd_title}
4、执行查看结果树
2、JSON提取器的使用
1、创建http请求,请求学生管理系统中所有学院信息
2、右击http请求选择后置处理器添加JSON提取器
1. names of created variables(设置一个变量名),用于保存提取的json数据
2. JSON Path expressions(json 路径表达式),比如: $.results[0].dep_name
$:表示整个json数据对象
3. 还可以设置默认值[可选]
4. 如果想要查看提取的数据,可以添加一个调试取样器
3、创建http请求,在设置参数的时候获取之前json提取的内容,比如:${dep_name}
4、执行查看结果树
14、断言
使用程序或者工具来判断预期结果和实际结果是否一致。
jmeter断言的分类
响应断言
大小断言
持续时间断言
响应断言
1、判断响应的内容是否和预期结果一致,比如: 状态码,响应内容(响应体)
2、响应断言的操作步骤
3、创建http请求
4、右击http请求,选择断言,添加响应断言
设置响应代码
设置响应文本
等于
包含
… …
5、执行查看结果树
说明:
响应文本:响应体
响应代码:状态码
响应信息:英文的状态描述,比如: 404 Not Found,200 OK
大小断言
判断响应内容的大小和预期结果是否一致
大小断言的步骤
1、创建http请求
2、右击http请求,选择断言,添加大小断言
选择完整响应
选择响应头
选择响应消息体
选择响应代码
选择响应信息
选择符号
设置大小
3、执行查看结果树
持续时间断言
判断接口响应时间是否在指定的时间内进行响应,否则断言失败
1、创建http请求
2、右击http请求,选择断言,添加持续时间断言
限定响应的时间,单位毫秒
3、执行查看结果树
14、聚合报告
用于查看接口的性能指标的。
添加聚合报告的步骤:在监听器里面添加聚合报告
1、聚合报告参数说明:
1. 样本: 每个请求发送次数
2. 平均值: 请求的平均响应时间
3. 中位数: 50%的请求响应时间小于该值
4. 90%百分位: 90%的请求响应时间小于该值
5. 95%百分位: 95%的请求响应时间小于该值
6. 99%百分位: 99%的请求响应时间小于该值
7. 最小值: 请求的最小响应时间
8. 最大值: 请求的最大响应时间
9. 异常: 请求的错误率
10. 吞吐量: 每秒处理完成的请求数,一般认为它为TPS:每秒处理的请求数 ***
11. 接收KB/sec: 每秒从服务器端接收到的数据量
12. 发送KB/sec: 每秒向服务器发送数据量
2、ramp-up
启动所有线程数需要的时间
提示: 通过设置ramp-up的值进行对比,可以得知ramp-up值越大,异常率越小。
3、ramp-up总结:
ramp-up时间越短,错误率越高。
线程数:表示就是用户数。
如果ramp-up时间为10,本质上是将10秒平均分成1000份,即 10/1000 = 0.01秒执行一次请求。
同理,如果设置为0,则相当于1000个人同时请求 。
通过聚合报告来查看接口的性能。
4、同步定时器(集合点)
模拟多用户的并发请求,保证同一时刻有指定的并发量。
在定时器里面选择同步定时器(Synchronizing Timer)
参数说明:
1、模拟用户组的数量:表示同一时刻有多少并发用户
2、超时时间: 不够指定用户数量,超过时间后也会做并发请求
5、__setProperty 和 __property函数的使用
主要是实现跨线程组传参的。
这两个函数关联需要通过后置处理器的BeanShell PostProcessor来完成
##6、 逻辑控制器
1. if控制器: 根据条件真假判断是否执行取样器(http请求)
2. ForEach控制器: 根据用户定义的变量来循环执行取样器(http请求)
3. 循环控制器: 根据用户设置循环次数,循环执行控制器里面取样器(http请求)
7、常数吞吐量定时器
常数吞吐量定时器有的地方也称常量吞吐量定时器,主要用于保证访问次数,一般用于压力测试。
主要针对于模拟单个用户发送多次请求
同步定时器:是针对于模拟多用户发送多次请求
8、生成html报告
无日志文件生成
基本命令格式:
jmeter -n -t <test JMX file> -l <test log file> -e -o <Path to output folder>jmeter -n -t /Users/apple/Desktop/计划/test.jmx -l testlog.jtl -e -o ./output/report参数详解:
-n:以非GUI形式运行Jmeter
-t:source.jmx 脚本路径
-l:运行结果保存路径(.jtl),此文件必须不存在
-e:在脚本运行结束后生成html报告
-o:保存html报告的地址, 此文件必须不存在
9、使用已有的jtl日志文件生成
基本命令格式:
jmeter -g <log file> -o <Path to output folder>示例:
jmeter -g /Users/apple/Desktop/计划/testlog.jtl -o ./output_report参数详解:
-g: 表示指定测试结果文件















 2799
2799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









