










一元线性回归方法
本文参考浙大《概率论与数理统计》第四版使用python进行实现一元线性回归分析方法,在文末会介绍一个应用实例,有关详细理论可参见书藉,或者参考百度文库下该章对应课件:
浙大四版概率认与数理统计《一元线性回归》
关于浙大版的概率论我个人还是比较推崇的,该书讲解得非常深刻清晰,无论你是考研还是想系统学习下概率论与数理统计,这都是一本不错的书藉。在原书《一元线性回归》一章中同时介绍了非线性回归的分析方法,本文不做扩展,后续有时间会再出python实现举例。
以下对一元线性回归方法做下简介:
回归模型
对于一元线性回归模型:
假设对于 x x 每个都有~ N(a+bx,σ2) N ( a + b x , σ 2 ) , a,b,σ a , b , σ 都是不依赖于 x x 的未知参数
记 , 那么就可以得到一元线性回归模型
其中 Y Y 表示 的线性函数 , ε ε 代表随机误差
参数估计
求解上述一元回归线性方程,即实现对 a,b, a , b , 的求解 ,在高中的线性拟合的课程就学到了最小二乘法。 为了实现误差的分析, 这里采用最大似然法,可以得到 σ σ 的估计(相关证明略)
将
μ^(x)=a^+b^x
μ
^
(
x
)
=
a
^
+
b
^
x
称为
x
x
经验回归函数, 其中 分别是
a,b
a
,
b
的最优估计
其中相应中间计算值如下
现在求解 σ σ 的估计 sigma^ s i g m a ^ ,令 Qe Q e 表示残差平方和则可以证明 Qeσ2 obey χ2(n−2) Q e σ 2 o b e y χ 2 ( n − 2 )
从而 σ2 σ 2 的无偏估计量为
相关系数与决定系数
线性拟合过程中,一般用到相关系数
R
R
. 由于用来它反应线性回归程度结果过于乐观,一般用它的平方决定系数
来反应线性回归程度, 有
当 R2 R 2 接近于1时,说明回归效果显著
线性假设的显著性检验
检验假设:
H0:b=0,H1:b≠0
H
0
:
b
=
0
,
H
1
:
b
≠
0
如果接受
H0
H
0
则表示线性回归结果不显著, 否则回归结果显著,
求解可得
H0
H
0
的拒绝域为:
式(10)表明如果满足H_0拒绝域条件,则可以一定置信水平 α α 认为线性回归结果显著
参数的置信区间
当回归效果显著时, 对系数
b
b
作区间估计, 系数 的置信水平为 的置信区间为
同理得到相应 a a 的置信区间
点预测与预测区间
假设
Y0
Y
0
是
x=x0
x
=
x
0
处对
Y
Y
的观察结果 。 是
Y0
Y
0
的点预测, 给定一定置信水平
α
α
得到相应的预测区间
其意味着给定观察值 Y0 Y 0 , 有一定的 1−α 1 − α 把握认为式(13)预测区间内
python 实现
以下章节使用python实现上述线性回归模型及应用实例分析, python需要安装numpy, matplotlip及scipy实现函数支持
一元线性回归方法python 实现
结合第一章节的理论,用python实现 a,b,σ a , b , σ 的估计, 线性回归显著性检验,及参数相应置信水平置信区间及点的预测区间计算。代码实现如下:
#一元线性回归模型
import scipy.stats as sst
import numpy as np
import matplotlib.pylab as plt
from matplotlib.widgets import Cursor
import csv
#对升序序列找到对匹配val值最接近的点坐标
def index_fit(y, val):
if val >= y[-1]:
return len(y) - 1
for i, yi in enumerate(y):
if val >= yi and val <= y[i + 1]:
if abs(val - yi) <= abs(val - y[ i + 1]):
fit_index = i
else:
fit_index = i+1
break
return fit_index
#用于计算Lxx, Lyy
def laa(x):
x_mean = np.mean(x)
lxx = np.sum((x-x_mean)**2)
return lxx
#用于计算Lxy
def lab(x,y):
x_mean = np.mean(x)
y_mean = np.mean(y)
lxy = np.sum((x-x_mean)*(y-y_mean))
return lxy
#一元线性回归模型
def polyfit_one(x, y, alpha):
assert len(x) == len(y)
n = len(x)
assert n > 2
lxx = laa(x)
lyy = laa(y)
lxy = lab(x, y)
R = lxy/(np.sqrt(lxx) * np.sqrt(lyy))
R2 = R*R #计算相关系数与决定系数
b_est = lxy/lxx #计算b估计
x_mean = np.mean(x)
y_mean = np.mean(y)
a_est = y_mean - b_est * x_mean #计算a估计
Qe = lyy - b_est * lxy
sigma_est2 = Qe / (n - 2)
sigma_est = np.sqrt(sigma_est2) #sigma估计
test = np.abs(b_est * np.sqrt(lxx))/sigma_est
test_level = sst.t.ppf(1 - alpha/2, df=n - 2)
linear_test = test > test_level #线性回归检验
#a,b的置信区间
b_int = [b_est - test_level * sigma_est / np.sqrt(lxx), b_est + test_level * sigma_est / np.sqrt(lxx)]
a_int = [y_mean - b_int[1] * x_mean, y_mean - b_int[0] * x_mean]
poly_int = (a_int, b_int)
poly_val = (a_est, b_est)
#返回回归模型相应参数
test_val = {'R': R,
'R2': R2,
'linear_test': linear_test,
'poly_int': poly_int,
}
process_val = {'lxx': lxx,
'lyy': lyy,
'lxy': lxy,
'sigma_est': sigma_est,
'x_mean': x_mean,
'y_mean': y_mean,
'test_level': test_level,
'ndim': n,
}
return (poly_val, test_val, process_val)
#计算相应的预测区间
def confidence_interval(y0=None, *args, **kwargs):
a_est, b_est = args
sigma_est = kwargs['sigma_est']
test_level= kwargs['test_level']
lxx = kwargs['lxx']
n = kwargs['ndim']
x_mean = kwargs['x_mean']
if isinstance(y0, (int, float, np.ndarray)):
x0 = (y0 - a_est) / b_est
elif isinstance(y0, (list, tuple)):
y0 = np.array(y0)
x0 = (y0 - a_est) / b_est
else:
return None
conf_down = y0 - test_level * sigma_est * np.sqrt(1 + 1 / n + ((x0 - x_mean) ** 2 / lxx))
conf_up = y0 + test_level * sigma_est * np.sqrt(1 + 1 / n + ((x0 - x_mean) ** 2 / lxx))
confidence_interval = (conf_down, conf_up)
return confidence_interval应用说明
本节将以实际的应用举例阐述下一元线性回归模型的使用与分析(博主工作时曾用该模型对工程数据进行参数拟合与风险把控取到了不错的效果,当然工作中的数据是不会给出来的)。这里采用百度文库一篇论文关于铜丝阻抗与温度关系的数据,数据链接如下:
铜丝阻抗与温度数据
本文已将它提取成csv格式文件, 为了方便理解,以下同时以列表形式给出
| Temperature/Degree | Celsius Resistance/Millohm |
|---|---|
| 0 | 4380 |
| 10 | 4560 |
| 20 | 4700 |
| 30 | 4860 |
| 40 | 5080 |
| 50 | 5240 |
| 60 | 5400 |
| 70 | 5580 |
| 80 | 5740 |
| 90 | 5960 |
| 100 | 6060 |
| 110 | 6260 |
| 120 | 6440 |
| 130 | 6580 |
| 140 | 6740 |
| 150 | 6940 |
| 160 | 7120 |
| 170 | 7280 |
| 180 | 7420 |
| 190 | 7600 |
| 200 | 7780 |
针对以上数据,以下进行线性回归模型分析。
区间预测
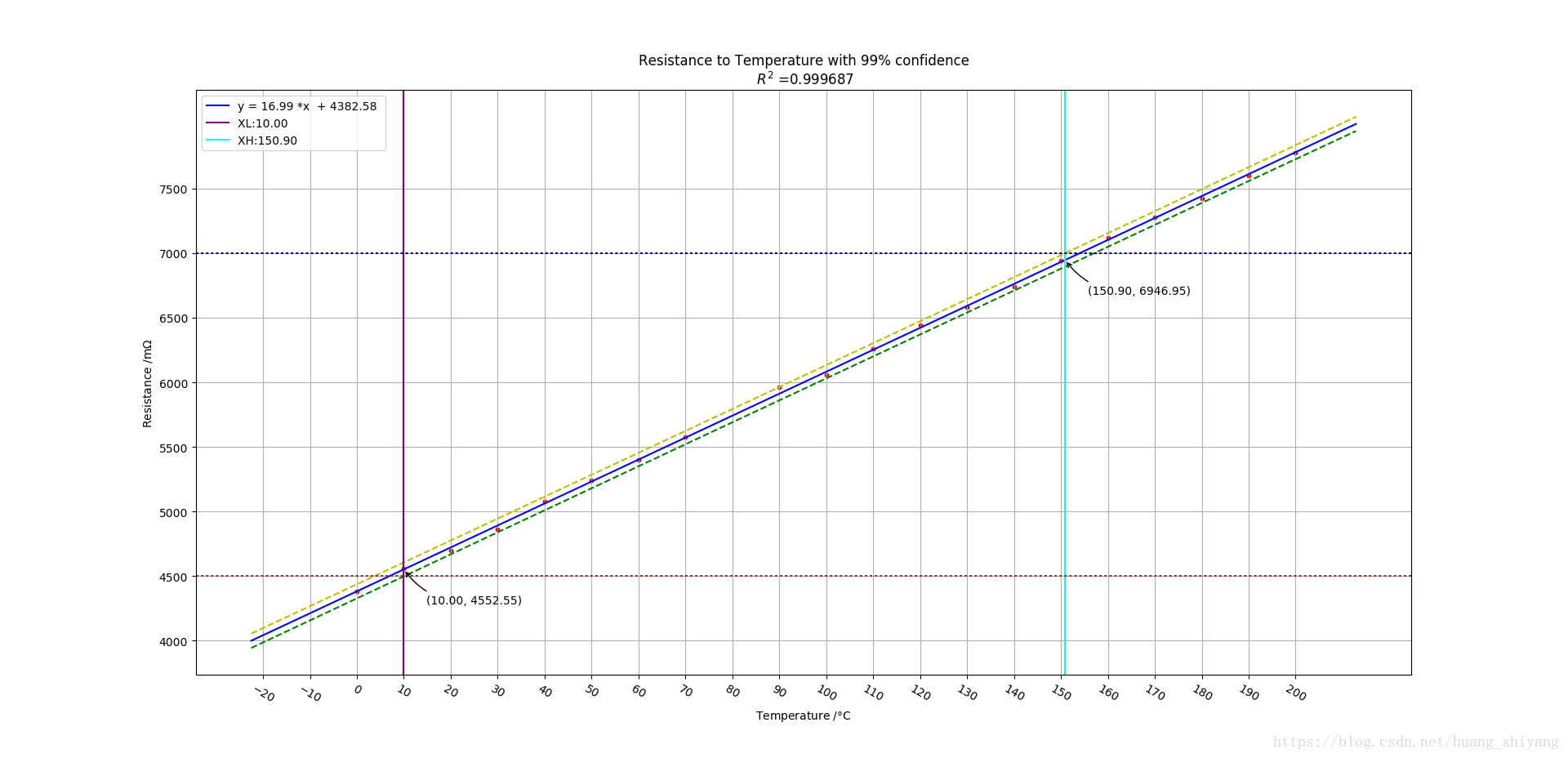
上述数据通过excel或者其他工具可以发现,阻抗与温度之间存在很好的线性关系,如下图
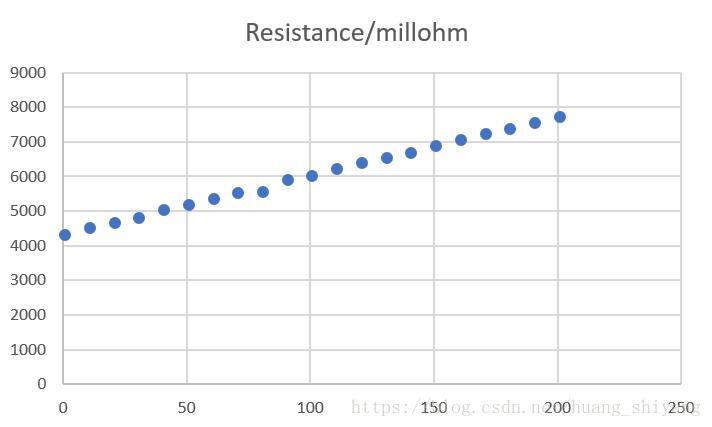
区间估计时一般取95%置信水平,由于数据之间非常好的线性水平这里将采用99%置信水平,进行区间预测。
效果如下:
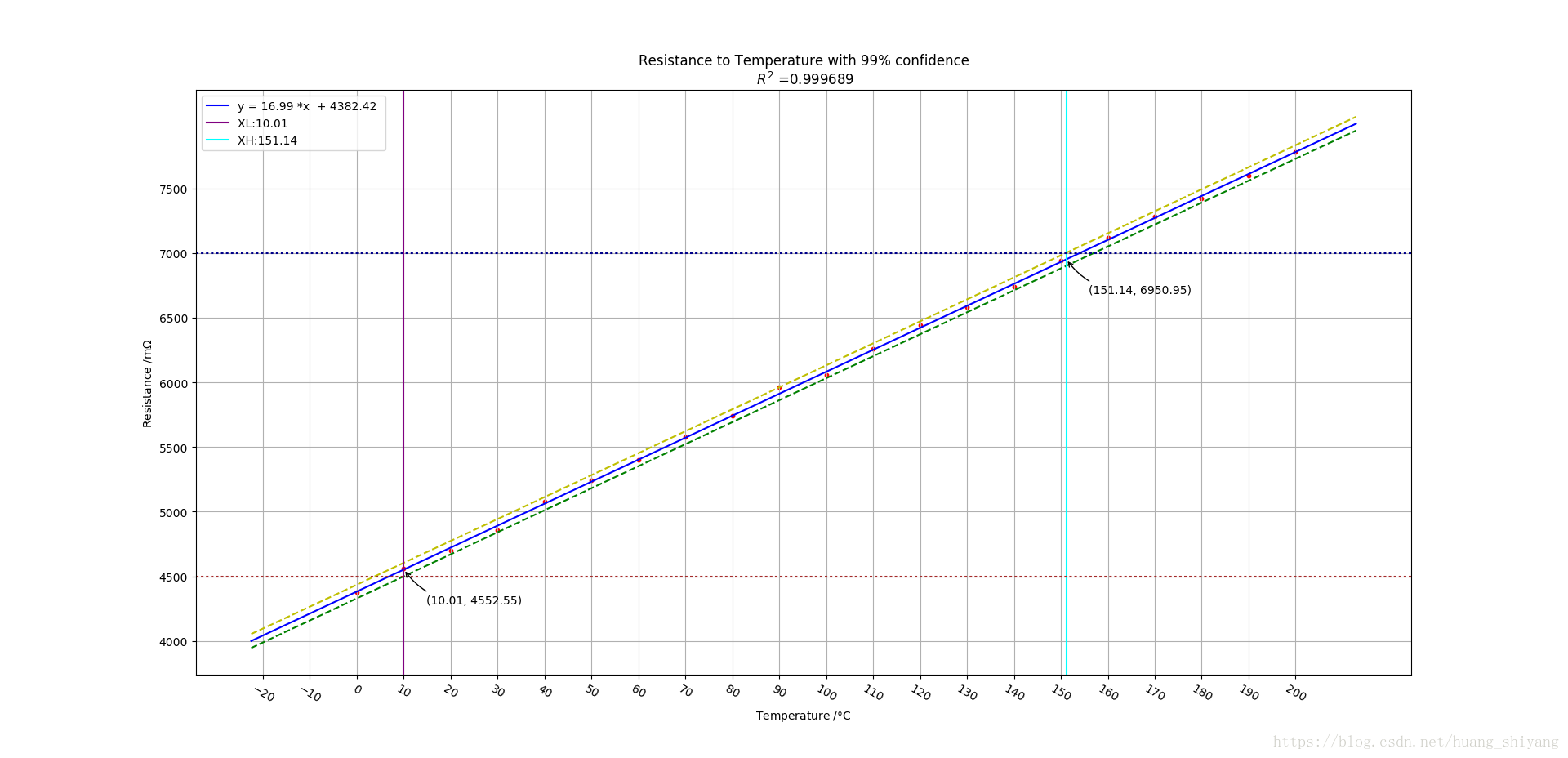
上图中在拟合直线两边的虚线即为相应数据的99%预测区间。 设想如果铜丝阻抗有效工作阻抗在[4500,7000]这个范围内,
那么铜丝工作的合适温度在哪个范围?一种想法是用拟合的直线表达式进行换算温度即可。但这是不够的,因为这种方法
并没有考虑误差的影响。引入了概率分析后,线性回归模型的一个好处就是可以对误差进行理论分析。如上图的紫色与红色横虚线,分别对应了假想的合理阻抗范围。 我们期待的是任意一个温度,基于该温度的点的在一定置信水平的预测区间均落在这两条线之内。 以99%的置信的水平,可以得到建议的温度范围是[10.01, 151.14], 此时可以发现铜丝的预测阻抗分别是4552.55与 6950.95 , 相对于理想的阻抗左右各压缩了50m 安全区间。可能读者觉得这点变化并不足为奇,这是因为原数据之间存在很好的线性关系,以致于不采用线性回归模型仅作拟合就能做一个基本的判断。
如果实验的环境并不是很好,或铜丝的质量不是很好(实际这是存在的),那么结果有如何呢? 我们对原数据加入40dB的相对噪声, 此时的温度-数据关系如下:
加入噪声阻抗与温度关系
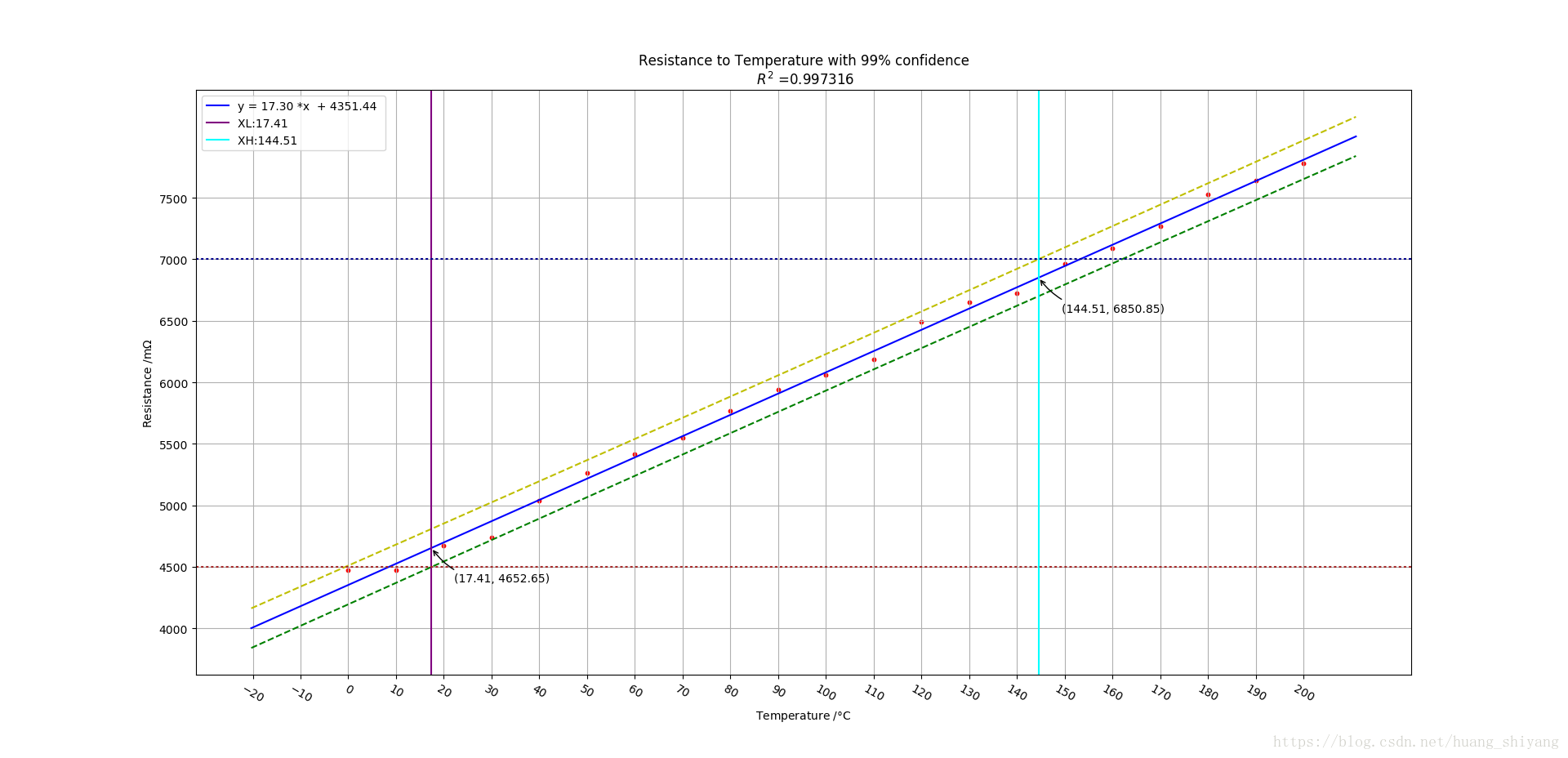
可以发现两次拟合的关系式差别不大,但是噪声使得预测点相应置信水平的预测区间放大了,此时如果想保证铜丝阻抗在[4500,7000]这个范围,99%置信下的温度保证范围在[17.41, 144.51] 此时的变化相对来说就不小了。
另外在代码中, 可以比较加入噪声前后,未加入模拟噪声前的噪声估计 σ^1 σ ^ 1 是 19.08,加入模拟噪声 σ^n σ ^ n 的实际功率是49.71,加入后的噪声估计 σ^2 σ ^ 2 是57.29 , 可以发现 σ^22≈σ^21+σ^2n σ ^ 2 2 ≈ σ ^ 1 2 + σ ^ n 2 。这与线性回归的噪声估计刚好一致。
同时需要说明的是,对一个点取 1−α 1 − α 得到相应水平的预测区间, 但当如果对一个区间卡控时 ,相应的区间边界置信水平是 1−α/2 1 − α / 2 . 如上例阻抗的卡控范围是[4500,7000], 99%的置信水平上边界7000为例相应的边界7000以上的可能性是0.5%, 所以边界的置信水平是99.5%。 所以以99%的水平判断边界时,可设置 α=0.02 α = 0.02
异常点剔除
继续阐述下线性模型的应用, 仍以采用上述阻抗与温度的例子。在线性拟合过程,读者可能有疑问,是否所有的点都应该纳入进行回归计算; 是否存在干扰点会影响线性拟合的结果; 如果存在这样的点怎么判断和剔除?
参上,在线性回归模型已经对每个点在一定置信水平下的预测区间, 那么基于整体可以以一定的置信水平去剔除落在预测区间外的点。以上述数据为例,将温度为80的阻抗5740改成5400(做为记录误差或人为操作误差),仍以99%的置信水平,
作图如下:
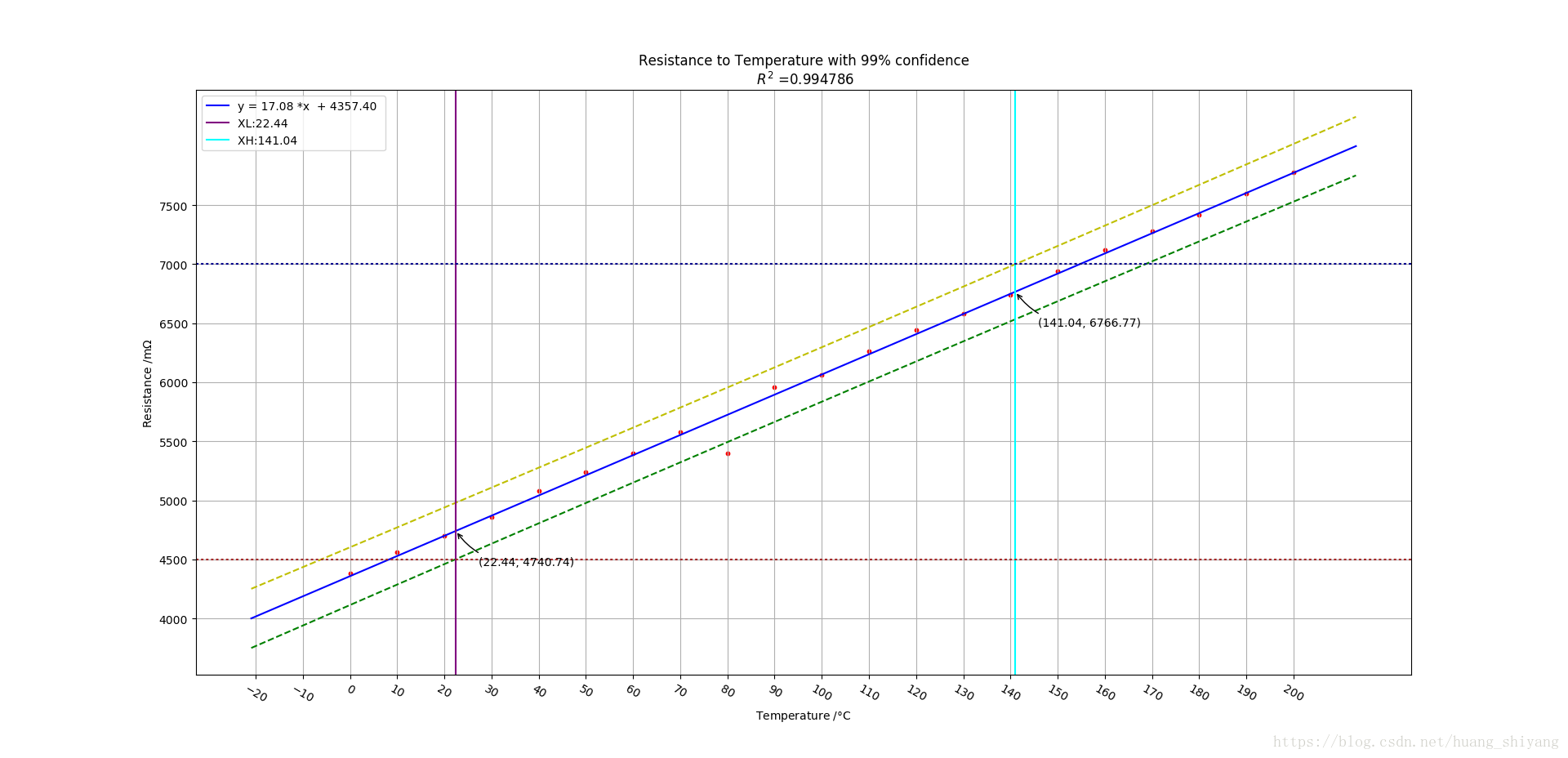
加入异常点后,可以发现在原模型中,温度为80的铜丝阻抗在预测区间外,因此有99%的把握判断其为异常点,剔除后作图如下 :
剔除异常点后,对比可以发现,剔除异常点后模型与原来温度不是80时更加接近。
最后,需要说明的是,该模型仅在线性关系下成立, 同时一些可以转化为线性模型的数据也适用,如指数与对数模型。
像上述阻抗与温度的关系的数据较为理想, 大部分存在线性关系的模型受噪声影响波动时,像20个样本点显然求出的模型
会不太准确,显然样本的数量也会影响模型的准确性。
以下是实验代码(结合上半部分代码一起阅读):
# 构建回归模型图示,
# #parama:alpha 置信水平 ,fignum表示绘画窗口号,
# kwargs 设置ylimit line:ylimit_down, ylimit_up , axis tick: ytick_down, ytick_up
# xlabel, ylabel, lengend label, xtick, ytick,title
def figure_drawing(x,y,alpha, fig_num, **kwargs):
poly_val, test_val, process_val = polyfit_one(x, y, alpha)
down_zone = confidence_interval(4500, *poly_val, **process_val)
up_zone = confidence_interval(7000, *poly_val, **process_val)
print(poly_val)
print(test_val)
print(process_val)
print(down_zone, up_zone)
print("Linear Test:", test_val['linear_test'])
R2 = test_val['R2']
f = plt.figure(fig_num)
# seaborn.set()
ax = f.add_subplot(111)
ylimit_down = kwargs['ylimit_down']
ylimit_up = kwargs['ylimit_up']
tick_yd = kwargs['ytick_down'] # int(ylimit_down * 0.7)
tick_yu = kwargs['ytick_up'] # int(ylimit_up * 1.3)
Y_test = np.linspace(tick_yd, tick_yu, 1000) #从ticks上下限间取1000个点
X_test = (Y_test - poly_val[0]) / poly_val[1]
Y_down, Y_up = confidence_interval(Y_test, *poly_val, **process_val)
xd = X_test[index_fit(Y_down, ylimit_down)]
xu = X_test[index_fit(Y_up, ylimit_up)]
yd = poly_val[0] + poly_val[1] * xd
yu = poly_val[0] + poly_val[1] * xu
xy_text1 = "(%.2f, %.2f)" % (xd, yd)
xy_text2 = "(%.2f, %.2f)" % (xu, yu)
poly_text = "y = %.2f *x + %.2f " % (poly_val[1], poly_val[0])
ax.plot(X_test, Y_test, '-b', label=poly_text)
ax.plot(X_test, Y_down, '--g')
ax.plot(X_test, Y_up, '--y')
ax.scatter(x, y, s=10, c='r')
xlabel = kwargs['xlabel']
ylabel = kwargs['ylabel']
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
xticks = kwargs['xticks']
yticks = kwargs['yticks']
ax.set_yticks(yticks)
ax.set_xticks(xticks)
title = kwargs['title'] + "\n $R^2$ =%f" % R2
ax.set_title(title)
plt.setp(ax.xaxis.get_majorticklabels(), rotation=-30)
plt.axvline(xd, linestyle='-', color='purple', label="XL:%.2f " % xd)
plt.axvline(xu, linestyle='-', color='cyan', label="XH:%.2f " % xu)
legend = ax.legend(loc="upper left")
legend_f = legend.get_frame()
# legend_f.set_alpha(0)
legend_f.set_facecolor("white")
plt.annotate(xy_text1, xy=(xd, yd),
xycoords='data',
xytext=(+20, -30), textcoords='offset points',
fontsize=10, arrowprops=dict(arrowstyle="->", connectionstyle="arc3, rad= -.3"))
plt.annotate(xy_text2, xy=(xu, yu),
xycoords='data',
xytext=(+20, -30), textcoords='offset points',
fontsize=10, arrowprops=dict(arrowstyle="->", connectionstyle="arc3, rad= -.3"))
plt.axhline(ylimit_down, linestyle=':', color='brown')
plt.axhline(ylimit_up, linestyle=':', color='darkblue')
plt.grid(True)
return poly_val, process_val
#从csv文件里面读取x,y
def read_xy(file_path):
with open(file_path,encoding="utf-8") as fp:
csv_reader = csv.reader(fp)
x = []
y = []
for ri,row in enumerate(csv_reader):
if ri == 0:
continue
x.append(float(row[0]))
y.append(float(row[1]))
return np.array(x), np.array(y)
def add_gausian_noise(xtest, snr):
snr = 10**(snr/10.0)
xpower = np.sum(xtest**2)/len(xtest)
npower = np.sqrt(xpower / snr)
noise = np.random.randn(len(xtest))*npower
# print("add noise:", noise)
#受限于信号长度,实际噪声与理论噪声会有一定出入
print("noise real power", np.sqrt(np.sum(noise**2/len(xtest))))
return noise
if __name__ == "__main__":
x, y = read_xy('Resistance to Temperature.csv') #读入数据
y = y + add_gausian_noise(y, 40) # 原信号本身存在噪声,可自行判断是否再加入噪声
fig_opt = {
'title': 'Resistance to Temperature with 99% confidence',
'xlabel': 'Temperature /$\degree$C ',
'ylabel': 'Resistance /m$\Omega$',
'ylimit_down': 4500,
'ylimit_up': 7000,
'ytick_down': 4000,
'ytick_up': 8000,
'xticks': np.arange(-20, 210, 10),
'yticks': np.arange(4000, 8000, 500),
}
poly_val, process_val = figure_drawing(x, y, 0.01, 1, **fig_opt)
reserve_i = []
# 剔除异常点
for i, xi in enumerate(x):
y0 = poly_val[0] + poly_val[1] * xi
if y[i] >= confidence_interval(y0, *poly_val, **process_val)[0] and\
y[i] <= confidence_interval(y0, *poly_val, **process_val)[1]:
reserve_i.append(i)
x = x[reserve_i]
y = y[reserve_i]
print(reserve_i)
print(len(reserve_i))
#剔除异常点后,再进行线性回归图示,此时取alpha为之前的两倍
figure_drawing(x, y, 0.02, 2, **fig_opt)
#添加游动光标
cursor = Cursor(plt.gca(), horizOn=True, color='black', lw=1)
plt.show()如有疑惑,可以通过邮件huangshiyang7197@foxmail.com 进行交流
博文预告: 下一篇博文将会介绍如何用python进行网络爬虫,结合pyecharts进行全国影院密度分布图,点个关注加期待哟!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









