







目录
一、反射机制
反射机制是一种基于字符串的驱动形态。通过字符串来查找模块中的函数、属性等,通过反射机制可以极大地简化我们的代码内容,也可以使程序具有在动态运行的过程中修改自己的结构和行为的能力。
反射机制主要就是四个不同的方法:
-
getattr()
-
setattr()
-
hasattr()
-
delattr()
1.getattr()
getattr()就是通过此函数来获取目标对象的属性、方法。这样的写法,是为了代码的精简。
包含有两个参数:
1. 目标:可以是实例化对象,也可以是类本身
2. 名称:通过字符串的形态来输入
下面是用getattr()调用属性
# 反射的示例
class Demo:
attribute_01 = '这是属性01'
attribute_02 = '这是属性02'
def func_demo(self):
print('这是类方法func_demo')
def func_demo1(self):
print('这是类方法func_demo1')
# 先实例化对象
demo = Demo()
# 获取目标对象的属性。
print(getattr(Demo, 'attribute_01')) # 其实就是Demo.attribute_01如果要获取的是方法,需要在getattr()后面再加个()
# 反射的示例
class Demo:
attribute_01 = '这是属性01'
attribute_02 = '这是属性02'
def func_demo(self):
print('这是类方法func_demo')
def func_demo1(self):
print('这是类方法func_demo1')
# 先实例化对象
demo = Demo()
# 获取目标对象的属性。
print(getattr(Demo, 'func_demo')) # 只是通过方法名获取到目标对象是否有这个方法。
getattr(Demo,'func_demo')() # 相当于demo.func_demo()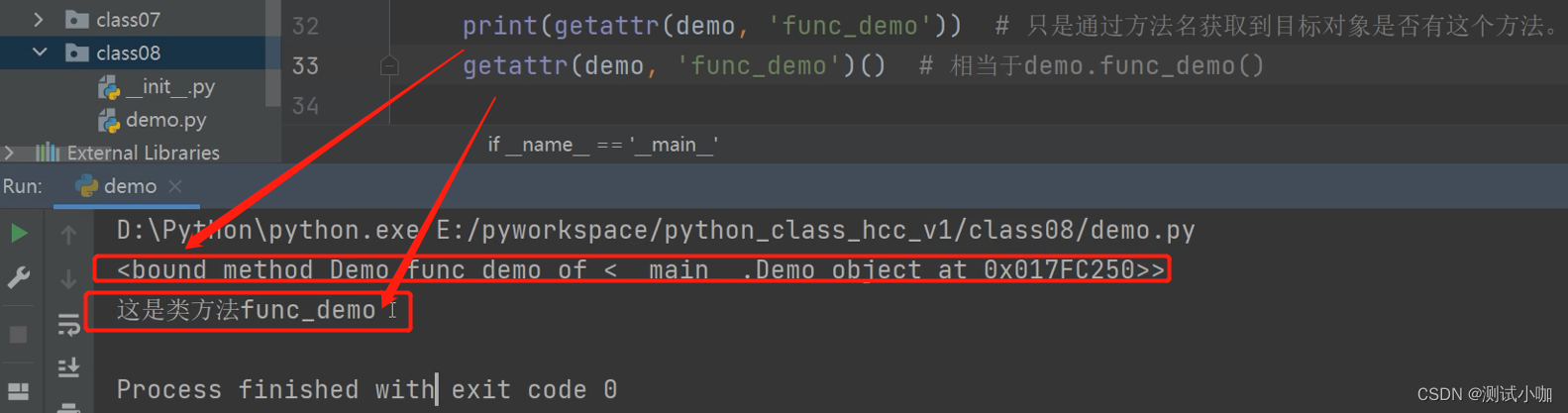
2.setattr()
通过此函数来对对象的属性进行新值的设置。也可以增加新的属性。这种设置,是临时性的,程序结束后就结束了。
# 对已有的属性进行新值的设置
setattr(demo, 'attribute_01', 'this is new attribute value')
# 上面这一步等同于demo.attribute_01='this is new attribute value'
print(demo.attribute_01)
# 对目标对象进行新的属性设置。
setattr(demo, 'attribute_03', 'this is 03')
print(demo.attribute_03)3.hasattr()
判断目标对象中是否包含有某个属性(函数也可以判断),返回True或者False,
同时也可以基于方法名称来判断方法是否存在
# hasattr()判断属性是否在对象中存在
print(hasattr(demo, 'attribute_00'))
print(hasattr(demo, 'attribute_01'))
print(hasattr(demo, 'func_demo')) # 判断是否有这个方法存在 运行的结果如下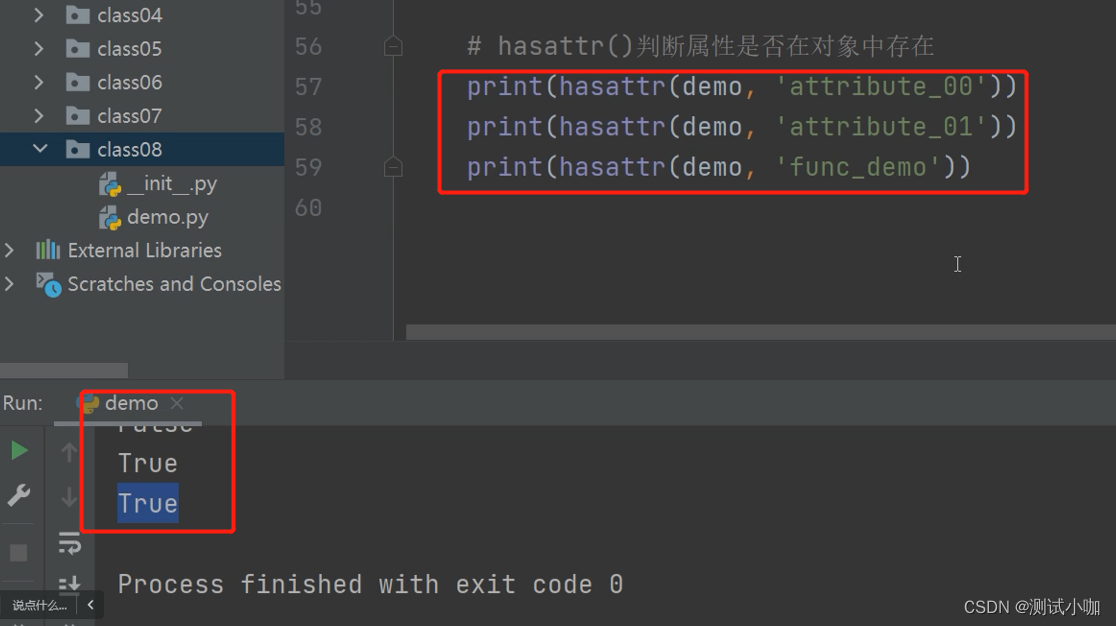
4.delattr()
用于删除目标对象中指定的属性:delattr()只能对类本身进行属性和方法的删除,无法对实例化对象进行属性和方法的删除。
# delattr()用于删除指定属性,只能用于属性,不能用于方法
# delattr(demo, 'func_demo') # 删除实例化对象的方法是会报错的。
delattr(Demo, 'attribute_01') # 删除已存在的属性
delattr(Demo, 'attribute_00') # 删除不存在的属性,也会报错二、Yield关键字
Yield关键字:其实就是讲迭代器、生成器、可迭代对象
1.可迭代对象:但凡可以通过循环来进行取值的都叫做可迭代对象。
2.迭代器:同属于可迭代对象,但是一次只取一个值,取了一个值之后就停在了那里,可以一直取到全部取完为止。前提条件是程序没有终止的情况下。
3.生成器:其实也是迭代器,也就意味着是可迭代对象,通过yield关键字来声明的函数被称为生成器
1.进行迭代器的创建
# 迭代器
li = [1, 2, 3, 4, 5, 6, 7] # 定义一个list可迭代对象
print(type(li))
# 将li转换为迭代器
it = iter(li)
print(type(it))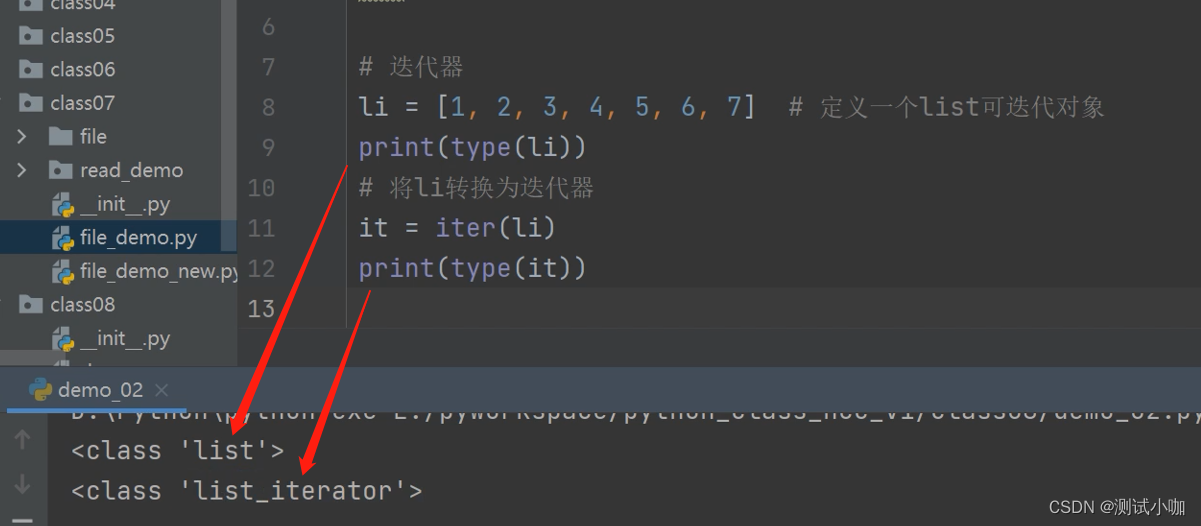
2.对迭代器进行取值操作,通过next
# 迭代器
li = [1, 2, 3, 4, 5, 6, 7] # 定义一个list可迭代对象
print(type(li))
# 将li转换为迭代器
it = iter(li)
print(type(it))
# 对迭代器进行取值操作:通过next()函数来获取值,一次只取一个值
print(next(it))
print('这是在迭代器取值后的操作')
print(next(it))
print('这是在for循环之前的操作')
for i in it:
print(i)3.生成器的演示
# 基于 yield关键字定义生成器
def func_demo(num):
while True:
if num < 0:
break
else:
num -= 1
yield num # 类似于return,但是trturn会终止函数。
# 这里的yeild是另外一种返回值的操作。带有yield关键字的返回,则是一种迭代器,
# 在通过yield返回数据的同时,函数的运行会在后台挂起,不会终结。
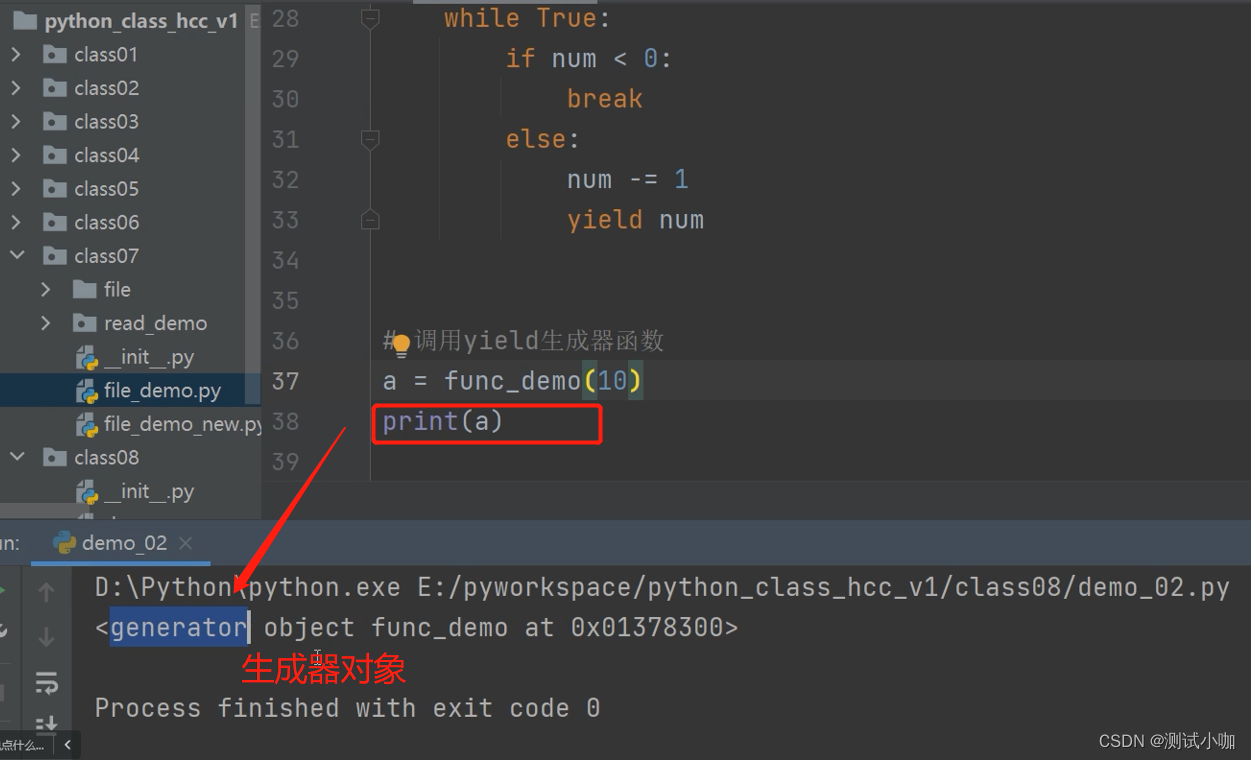
a = func_demo(10)
print(a)运行上面代码,得到下图,func_demo是一个generator对象,也就是生成器对象
对生成器进行取值,需要用到 print(next(a))
# 基于 yield关键字定义生成器
def func_demo(num):
while True:
if num < 0:
break
else:
num -= 1
yield num
a = func_demo(10)
print(next(a))
print(next(a))
print(next(a))4.iter()和yield的区别
yield只能用于函数中,而iter()是将可迭代对象转换为迭代器
yield生成器很大的作用在于:初期获取测试用的大批量数据内容。
因为生成器的特性,每一组数据来执行不同的操作,而这时候只需要一个数据文件即可。
生成器和迭代器都属于同样的性质:
1. 取值都是一个个取
2. 取值都是从前往后走,不能够回头。
3. 一直到取值完毕为止















 1778
1778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









