







目录
一、断言
所有的自动化测试本质上而言还是测试工作。
测试行为一定会有结果的反馈,自动化测试也是一样。
在自动化测试过程中需要对结果进行校验。
而校验的过程就是断言的行为,实际上就是预期结果与实际结果的对比。
自动化测试中,关于webui的自动化断言的使用,只需要在流程的末尾进行校验即可。一般而言,UI自动化流程中断言只会出现一次,不需要在各个不同的地方进行各种断言。
UI的断言本质上而言其实就是if...else...逻辑。只是说我们会通过assert关键字来实现。断言所选择的点,一定是最具有代表性的内容才可以。
一般断言主要还是基于文本信息来进行,其次可以考虑用元素获取的断言。
文本信息断言,主体还是基于assert关键字来实现,元素的断言推荐使用显式等待的方式来实现。
断言:
关键字是assert,写法是下面这一行的写法
assert 表达式,Message
判断表达式是否成立,如果成立则继续运行,如果不成立,则抛出assertionError,并显示Message信息,同时,程序停止运行
实际运用如下:
from time import sleep
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
# assert关键字的基本使用
# assert 1 == 1, "断言失败"
# 创建driver对象
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('http://hzp.fecmall.com')
# 登录流程的执行
driver.find_element('link text', '登录账户').click()
driver.find_element('name', 'editForm[email]').send_keys('2314419713@qq.com')
driver.find_element('name', 'editForm[password]').send_keys('hzp123456')
driver.find_element('id', 'js_registBtn').click()
# 预期结果
expected = "黄先森"
# 实际结果:text属性就是获取元素的文本信息
reality = driver.find_element('id', 'welcome').text
# 实际结果:基于元素来进行断言
# 校验预期结果是否包含在实际结果之中
assert expected in reality, '断言失败,预期结果是{},实际结果是{}'.format(expected, reality)
assert driver.find_element('link text', '退出1'), '元素未找到,断言失败'
# 显式等待断言只限于针对元素的获取来实现。
WebDriverWait(driver, 5, 0.5).until(lambda el: driver.find_element('link text', '退出'), message='获取退出元素失败')
sleep(20)
二、Document对象与JS执行器
1.Document对象与JS执行器概念
在Selenium中,无法对元素的属性进行修改或者删除,所以才需要js执行器来协助我们完成此类操作,以便于整个自动化流程的顺利开展。
web页面都是基于前端的HTML和JS来进行展示的,我们在操作前端界面的时候因为一些特定的操作行为限制,导致无法直接通过Selenium来完成我们想要做的事情,所以需要通过操作document对象来实现我们要执行的操作行为。
js执行器:专门解决疑难杂症的有效手段。
document对象常用方法:
1. setAttribute(attribute_name,value)设置attribute_name属性值为value,如果有该属性,则进行 修改属性值,若没有,则新增属性值。
2. removeAttribute(attribute_name)将指定的属性进行删除处理。
remove主要是针对readonly属性和style属性值为display:none来进行的操作处理
readonly属性表示元素为只读属性,删除后可以进行写入
display属性值表示元素不可见,无法直接定位和操作,删除后可以获取元素并操作。
3. innerHTML 用于指定元素的txt信息,并返回,就相当于是driver.find_element().text,只是多了一个修改的操作
4. 滚动条操作:
window.scrollTo(x,y)进行滚动条的移动操作,x表示横轴,控制横向滚动条,y表示纵轴,控制上下滚动条
webelement.scrollIntoView() 精准地基于元素来进行滚动条的移动,将指定的WebElement对象显示在页面中心位置
将document对象的这些操作行为基于python的Selenium来运行,运行的载体就是Selenium中的js执行器
2.修改元素属性
在Selenium中,无法对元素的属性进行修改或者删除,所以才需要js执行器来协助我们完成此类操作,以便于整个自动化流程的顺利开展。
下图就是通过document对象进行页面修改的基础操作的演示:
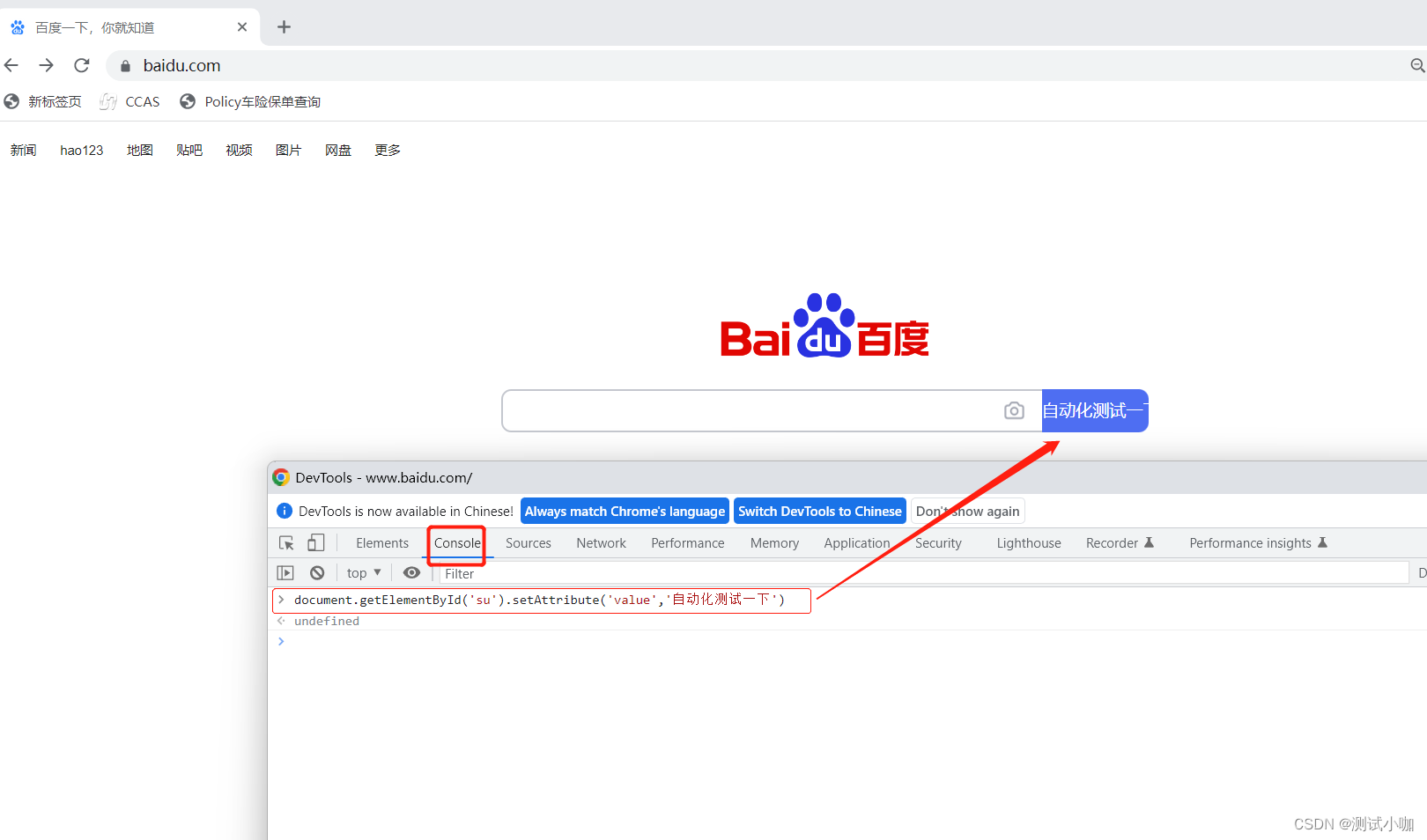
下面就是执行JS指令修改目标属性的写法:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.set_window_size(2000, 1000)
# js指令,修改属性
js = "document.getElementById('su').setAttribute('value','自动化一下')"
driver.execute_script(js) # 单纯执行js指令的写法
sleep(10)除了可以修改,也可以移除属性:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.set_window_size(2000, 1000)
# js指令,移除属性
js = "document.getElementById('su').removeAttribute('value')"
driver.execute_script(js) # 单纯执行js指令的写法
sleep(10)3.selenium+JS完成属性修改
但是上面两种方式都有一定的局限性
只能通过setAttributeById的方式即只支持通过ID去定位属性,但是有的元素是没有id的
这个时候可以通过selenium+Js执行器的方法去定位,
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.set_window_size(2000, 1000)
# selenium+JS执行器
el=driver.find_element('xpath','//*[@id="su"]')
# 通过arguments[0]作为占位符的形式,调用对应的操作,这是固定写法
js="arguments[0].removeAttribute('value')"
# 基于Selenium+JS指令的写法,可以更灵活支持各类元素定位操作
driver.execute_script(js,el)
sleep(10)4.innerHTML
用于指定元素的txt信息,并返回,就相当于是driver.find_element().text,只是多了一个修改的操作
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.set_window_size(2000, 1000)
el = driver.find_element('link text', '新闻')
# 因为要获取文本的返回值,所以需要添加return关键字
js2 = "return arguments[0].innerHTML='hzp news'"
# 基于Selenium+JS指令的写法,可以更灵活支持各类元素定位操作
driver.execute_script(js2,el)
sleep(10)5.scrollTo滚动条操作
window.scrollTo(x,y)进行滚动条的移动操作,
x表示横轴,控制横向滚动条,y表示纵轴,控制上下滚动条
这个方法有个弊端,就是无法精准定位到需要的元素所在的地方
js = 'window.scrollTo(500,1000)' # 大范围的页面移动可以考虑使用
driver.execute_script(js)6.scrollIntoView精准滚动到元素
webelement.scrollIntoView() 精准地基于元素来进行滚动条的移动,
将指定的WebElement对象显示在页面中心位置
# 基于流程执行的精细化滚动条操作,个人推荐使用
el = driver.find_element('xpath', '//span[text()="设置"]')
js = 'arguments[0].scrollIntoView()'
driver.execute_script(js,el)














 1638
1638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









