







Linux 查找文本传统上有三种程序可以用来查找整个文本文件:
1,grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设grep指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为"-",则grep指令会从标准输入设备读取数据。
2,egrep 扩展式grep(Extended grep)。这个程序使用扩展正则表达式
grep语法:
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][–help][范本样式][文件或目录…]
参数:
-
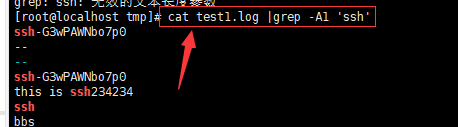
-A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-
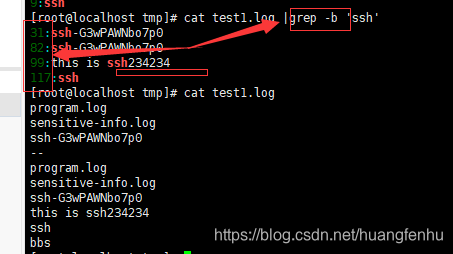
-b 或 --byte-offset : 在显示符合样式的那一行之前,标示出该行第一个字符的编号。
-
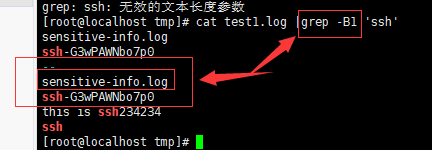
-B<显示行数> 或 --before-context=<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前的内容。
-
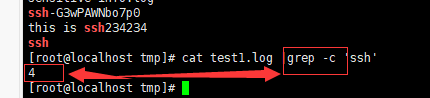
-c 或 --count : 计算符合样式的列数。
-
-C<显示行数> 或 --context=<显示行数>或-<显示行数> : 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-
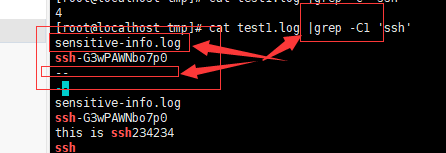
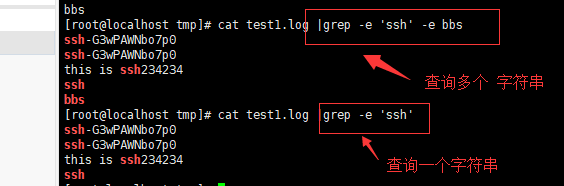
-e<范本样式> 或 --regexp=<范本样式> : 指定字符串做为查找文件内容的样式(用于查找多个内容)
-
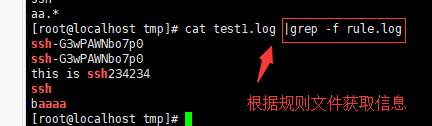
-f<规则文件> 或 --file=<规则文件> : 指定规则文件,其内容含有一个或多个规则样式,让grep查找符合规则条件的文件内容,格式为每行一个规则样式。

-
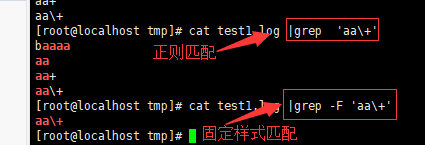
-F 或 --fixed-regexp : 将样式视为固定字符串的列表。
-
-G 或 --basic-regexp : 将样式视为普通的表示法来使用。(仅支持基本正则,扩展正则需要添加‘\’支持)


-
-h 或 --no-filename : 在显示符合样式的那一行之前,不标示该行所属的文件名称。

-
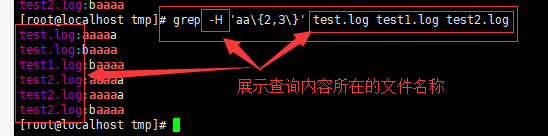
-H 或 --with-filename : 在显示符合样式的那一行之前,表示该行所属的文件名称。
-
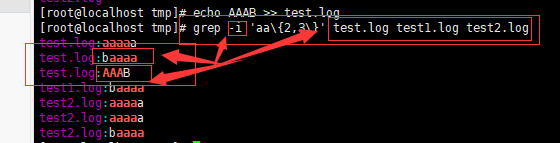
-i 或 --ignore-case : 忽略字符大小写的差别。
-
-l 或 --file-with-matches : 列出匹配内容的文件名,这个很常用。

-
-L 或 --files-without-match : 列出文件内容不符合指定的样式的文件名称。

-
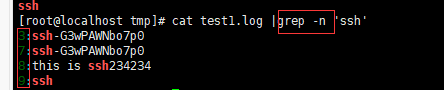
-n 或 --line-number : 在显示符合样式的那一行之前,标示出该行的列数编号。
-
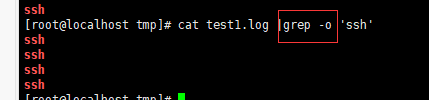
-o 或 --only-matching : 只显示匹配PATTERN 部分。
-
-q 或 --quiet或–silent : 不显示任何信息。


-
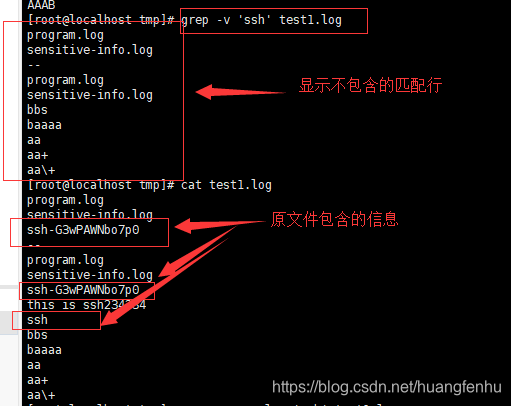
-v 或 --revert-match : 显示不包含匹配文本的所有行。
-
-V 或 --version : 显示版本信息。
-
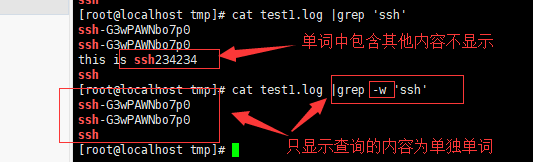
-w 或 --word-regexp : 只显示全字符合的列。
-
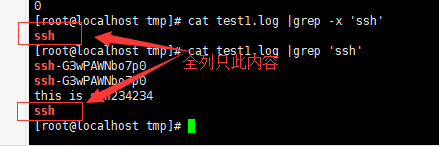
-x --line-regexp : 只显示全列符合的列。
正则表达式元字符集(基本集):
^ 锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ 锚定行的结束 如:'grep$'匹配所有以grep结尾的行。
. 匹配一个非换行符的字符如:'gr.p'匹配gr后接一个任意字符,然后是p。
* 匹配零个或多个先前字符如:'*grep'匹配所有一个或多个空格后紧跟grep的行。 .*一起用代表任意字符。
[] 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\< 锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
\w 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W \w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b 匹配一个单词的边界。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。
\B 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。
用于egrep和 grep -E的元字符扩展集:
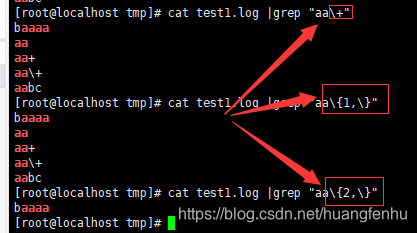
+ 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。
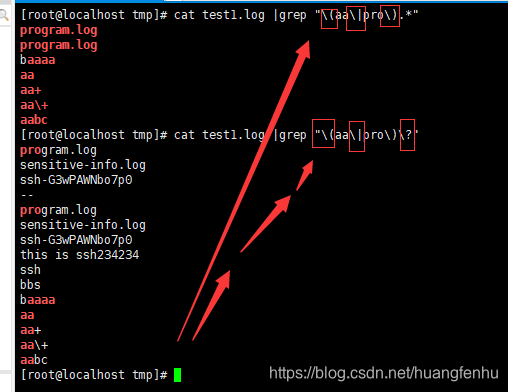
| 将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her"
() 分组符号,如:love(able|rs)ov+匹配loveable或lovers,匹配一个或多个ov。
{n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。
{n,} n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。
{n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。
如果grep想要直接使用扩展集的话,需要在扩展集字符前面添加上“\”:
POSIX字符集(以下字符集作为一个整体使用):
类别 匹配字符
[:alnum:] 数字字符
[:alpha:] 字母字符
[:blank:] 空格(space)与定位(tab)字符
[:cntrl:] 控制字符
[:digit:] 数字字符
[:graph:] 非空格字符
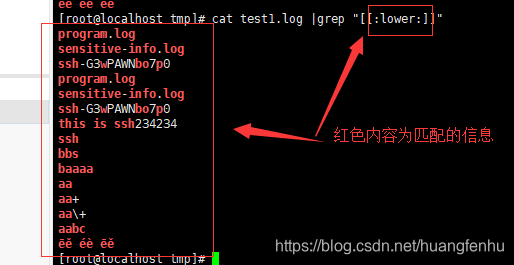
[:lower:] 小写字母字符
[:print:] 可显示的字符
[:punct:] 标点符号字符
[:space:] 空白字符
[:upper:] 大写字母字符
[:xdigit:] 十六进制数字
示例如下:
cat test1.log |grep "[[:lower:]]"
等价字符集:
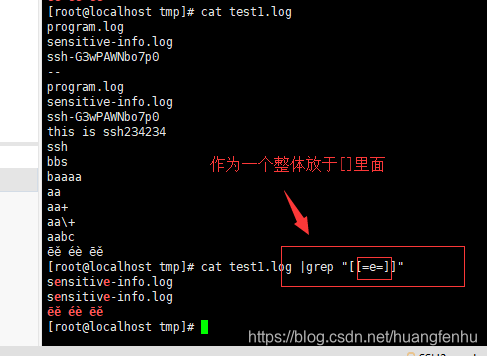
等价字符集列出的应视为等值的一组字符,例如e与ēě éè。它由取自于locale的名字元素组成,以[=与=]括住
示例如下:
cat test1.log | grep "[[=e=]]"
删除空白行:
cat test1.log |grep -v '^$'
参考资料如下:
《中文版shell脚本学习指南》
http://www.zsythink.net/archives/1733
https://www.runoob.com/linux/linux-comm-grep.html















 1610
1610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









