










一、生成重复记录数据
import numpy as np
import pandas as pd
#生成重复数据
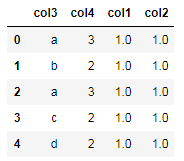
df=pd.DataFrame(np.ones([5,2]),columns=['col1','col2'])
df['col3']=['a','b','a','c','d']
df['col4']=[3,2,3,2,2]
df=df.reindex(columns=['col3','col4','col1','col2']) #将新增的一列排在第一列
df输出:
二、判断重复记录(行)
#判断重复数据
isDplicated=df.duplicated() #判断重复数据记录
isDplicated输出:

三、删除重复值
#删除重复值
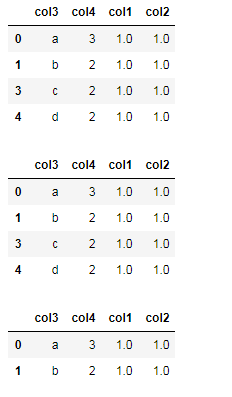
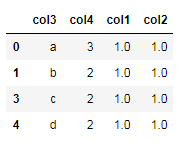
new_df1=df.drop_duplicates() #删除数据记录中所有列值相同的记录
new_df2=df.drop_duplicates(['col3']) #删除数据记录中col3列值相同的记录
new_df3=df.drop_duplicates(['col4']) #删除数据记录中col4列值相同的记录
new_df4=df.drop_duplicates(['col3','col4']) #删除数据记录中(col3和col4)列值相同的记录
new_df1
new_df2
new_df3
new_df4输出:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











